1 # filename: word_freq.py 2 # 注意:代码风格 3 4 5 import argparse 6 import re 7 8 def process_file(dst): # 读文件到缓冲区 9 try: # 打开文件 10 file=open(dst,‘r‘,encoding=‘ISO-8859-1‘) 11 except IOError as s: 12 print(‘IOError‘,s) 13 return None 14 try: # 读文件到缓冲区 15 bvffer=file.read() 16 except: 17 print("Read File Error!") 18 return None 19 file.close() 20 return bvffer 21 #该函数采用ISO-8859-1的方法读取txt文件,若使用utf-8读取,《飘》中开头的换行将会提示错误 22 23 24 25 def process_buffer(bvffer): 26 if bvffer: 27 word_freq = {} 28 # 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq 29 content=bvffer.lower() 30 regex=re.compile(‘[^a-zA-Z\s]‘) 31 content_result=regex.sub(‘‘,content) 32 content_result.lower() 33 34 content_result.replace(‘/n‘,‘ ‘) 35 content_result=content_result.split(‘ ‘) 36 for word in content_result: 37 word_freq[word] = word_freq.get(word, 0) + 1 38 39 return word_freq 40 #该函数处理缓冲区的bvffer,采用了正则表达式来将非空格和字母去除,并将大写改为小写后根据空格来分割 ,并采用wors_freq字典统计词频。 41 42 43 44 def output_result(word_freq): 45 if word_freq: 46 sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) 47 for item in sorted_word_freq[:10]: # 输出 Top 10 的单词 48 print(item) 49 #输出排序后前十的元素 50 51 52 if __name__ == "__main__": 53 parser = argparse.ArgumentParser() 54 parser.add_argument(‘dst‘) 55 args = parser.parse_args() 56 dst = args.dst 57 bvffer = process_file(dst) 58 word_freq = process_buffer(bvffer) 59 output_result(word_freq) 60 #接受参数dst 并最为程序入口依次执行
括号内换行第二行缩进4个空格,适用于起始括号就换行的情形

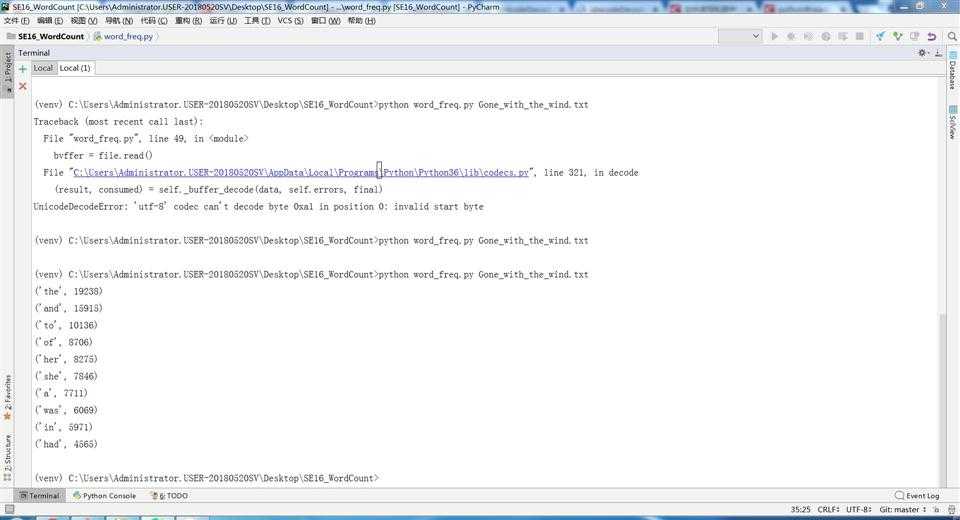
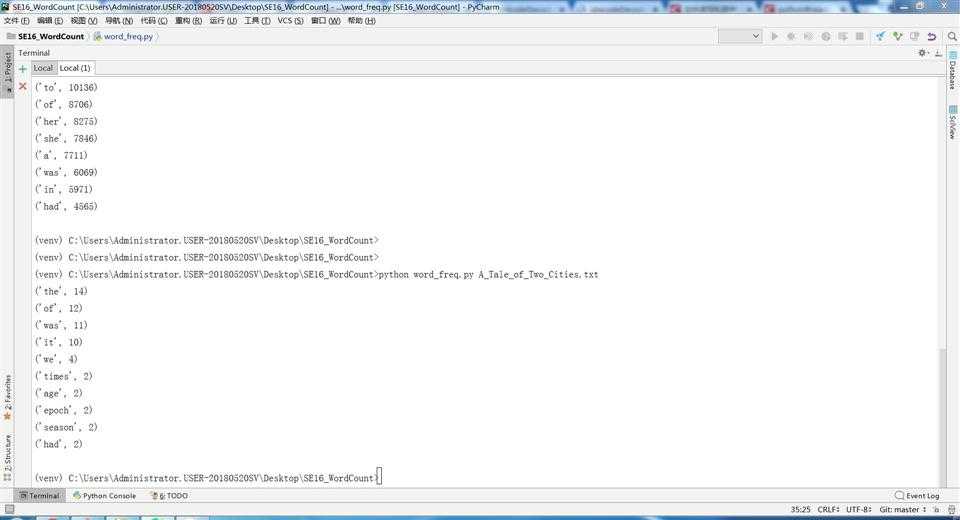
(4)性能分析结果及改进

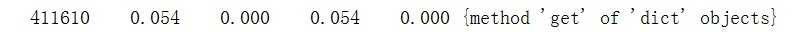
可以看出字典的get()方法执行了411610次,单词时间达到了0.054s,可见开销是很大的。
1 for word in content_result: 2 word_freq[word] = word_freq.get(word, 0) + 1
原代码如上,将get()方法弃用,改为以下代码:
1 for word in content_result: 2 # word_freq[word] = word_freq.get(word, 0) + 1 3 if word_freq.__contains__(word): 4 word_freq[word] = word_freq[word] + 1 5 else: 6 word_freq[word] = 1
使用cprofile运行如下:
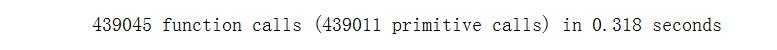
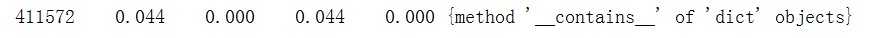
可以发现执行次数减少了很小的一部分(else分支分流了),但是单词时间减少为0.044s,从而使整体的执行时间由0.35s下降到了0.318s,所以改进这一处代码是有效的优化。
原文:https://www.cnblogs.com/vandarkhole/p/9746137.html