作业要求参见[https://edu.cnblogs.com/campus/nenu/2018fall/homework/2145]
一、得出程序运行时间
运行结果如下:
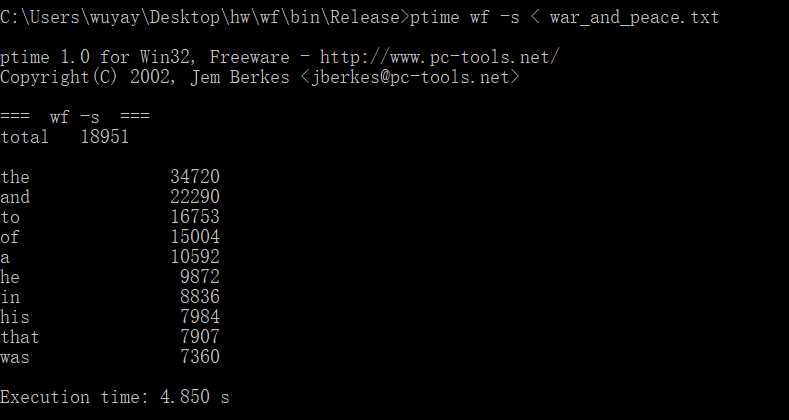
第一次运行时间:4.85s
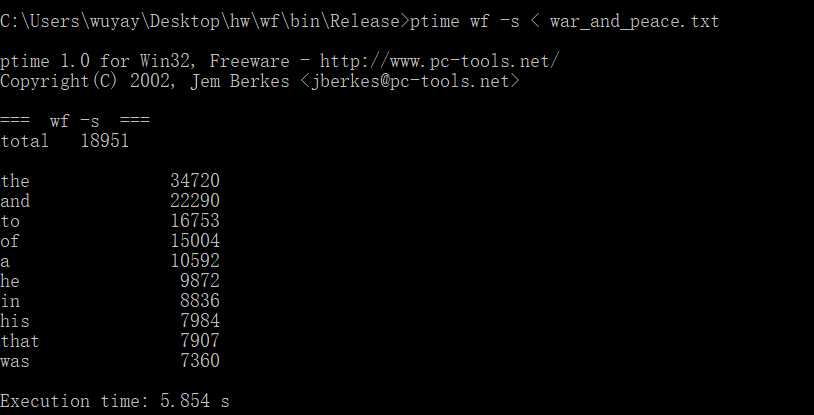
第二次运行时间:5.854s
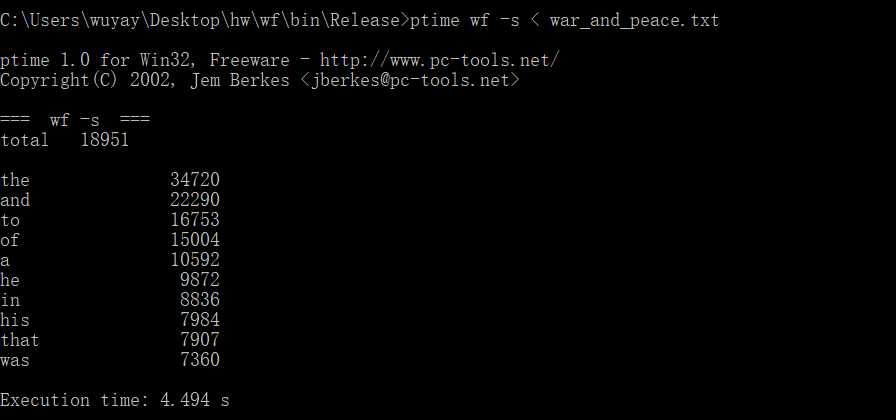
第三次运行时间:4.494s
平均运行时间:5.066s
CPU参数:Intel(R) Core(TM) i5-4200H CPU @ 2.80GHz 2.79 GHz
二、猜测程序瓶颈
直接执行功能四,词频统计的过程大致是,逐个读入字符,然后根据空格和句号等作为单词的分割标志,存储起来,同时在存储的数组中从头遍历是否已经存在,最后对单词频率进行排序。
因此我认为在遍历单词是否已经存在是比较消耗时间的地方
1 while(ch!=EOF) 2 { 3 4 if(isalpha(ch)||(isdigit(ch))) 5 { 6 flag = 1; 7 tmp[i++]=ch; 8 } 9 else 10 { 11 if(flag) 12 { 13 if((ch==‘-‘)||(ch==‘\‘‘)) 14 { 15 tmp[i++]=ch; 16 flag = 1; 17 } 18 else 19 { 20 flag=0; 21 tmp[i]=‘\0‘; 22 i=0; 23 for(j=0;j<num;j++) 24 { 25 if(strcmp((words+j)->w,tmp)==0) 26 { 27 (words+j)->fre++; 28 break; 29 } 30 } 31 if(j==num) 32 { 33 (words+num)->fre=1; 34 strcpy((words+num)->w,tmp); 35 num++; 36 } 37 if(num==500*p) 38 { 39 p++; 40 words=(wordnode*)realloc(words,500*p*sizeof(wordnode)); 41 for(k=num;k<500*p;k++) 42 { 43 (words+k)->fre=0; 44 } 45 } 46 } 47 } 48 } 49 50 51 ch=tolower(getchar()); 52 }
三、profile分析
因为一开始是用code blocks写的作业,所以直接用了code profile插件进行效能分析。
下面是我的程序统计《战争与和平》词频时运行的情况:
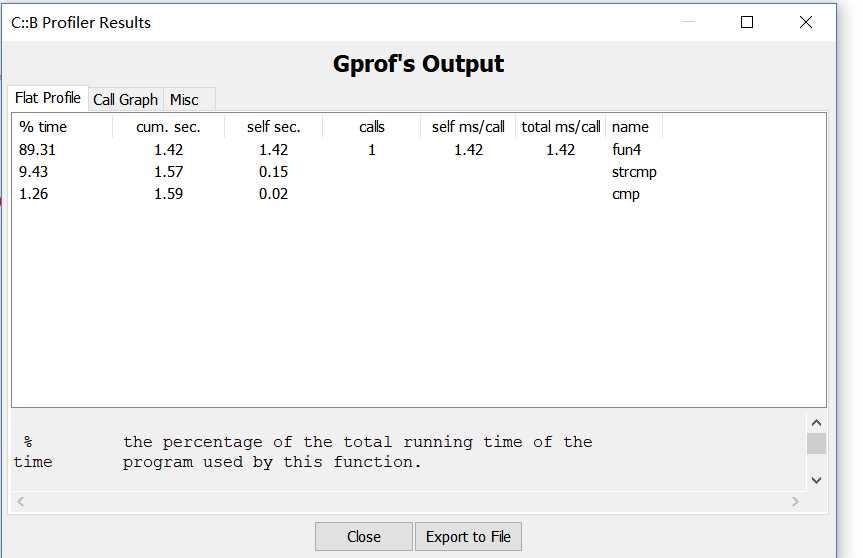
各个信息的解释如下:
可以看到功能4的函数fun4()在运行时,占用的时间中,除去cmp()用于比较排序的时间,其他部分,也就是顺序查找存入单词的时间占用了几乎80%。因此,可以认为我的猜测是对的。
四、优化程序
更改查找的方法,尝试优化,看是否能够缩短运行速度。
一开始选择用顺序查找,想到用二分查找,于是写了下面的一个判断的函数:
int Isinword(wordnode* words,int num,char tmp[]) { int low, high, mid; low=0; high=num; if(num == 0) return -1; while(low<=high) { mid = (low+high)/2; if( strcmp((words+mid)->w,tmp)==0 ) return mid; if(strcmp((words+mid)->w,tmp) > 0) high = mid-1; if(strcmp((words+mid)->w,tmp) < 0) low = mid+1; } return -1; }
但是非常不好的是,用二分查找的前提是要保证已有的数组是有顺序的。。因为一开始是定义了数组来存储单词,所以在插入新的单词时都是无序的。。为了偷懒,想在每次插入之前都排序一下。。。。好吧,我承认这很愚蠢,因为这样运行程序后,得到结果所需要的时间以分钟计算。
五、再次测试
头脑简单,我真的跑了一次。。
它仿佛能运行一辈子,我放弃了
六、总结
这次作业尝试对之前写的程序做优化,最后没有能够成功。
一开始写的时候没有想明白怎么实现,很多东西想当然就直接去写。我一直觉得自己的编程很差,在这样自己写程序出来的实践中,中途有很多时候觉得自己的程序就像一件衣服,到处都是破洞,到处都在打补丁,很难看,很想扔掉。。
想来还是能力有限,不会编程,不会规划。后面,也许还想重新来写,这次时间有限没能达到预期的目的。
原文:https://www.cnblogs.com/wuyiyao694/p/9744616.html