081600107 傅滨: 博客地址:http://www.cnblogs.com/fblogy/p/9766315.html
031602248 郑智文:博客地址:https://www.cnblogs.com/Zzwena/p/9768881.html
https://github.com/fblogy/PairProject-C
主要由我实现了爬虫部分,队友实现了WordCount代码部分| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| ? Estimate | ? 估计这个任务需要多少时间 | 30 | 40 |
| Development | 开发 | 720 | 620 |
| ? Analysis | ? 需求分析 (包括学习新技术) | 240 | 420 |
| ? Design Spec | ? 生成设计文档 | 20 | 10 |
| ? Design Review | ? 设计复审 | 20 | 10 |
| ? Coding Standard | ? 代码规范 (为目前的开发制定合适的规范) | 20 | 5 |
| ? Design | ? 具体设计 | 50 | 40 |
| ? Coding | ? 具体编码 | 220 | 60 |
| ? Code Review | ? 代码复审 | 70 | 30 |
| ? Test | ? 测试(自我测试,修改代码,提交修改) | 80 | 45 |
| Reporting | 报告 | 70 | 90 |
| ? Test Repor | ? 测试报告 | 30 | 45 |
| ? Size Measurement | ? 计算工作量 | 10 | 10 |
| ? Postmortem & Process Improvement Plan | ? 事后总结, 并提出过程改进计划 | 30 | 45 |
| 合计 | 820 | 750 |


代码实现
#获取论文列表的超链接
resp=urllib.request.urlopen(url)
html=resp.read()
html=html.decode()
links=re.findall(r‘content_cvpr_2018/html/.*.html‘,html) #所有论文网址尾部分 # 依次打开每篇论文的网址
for a in links:
resp = urllib.request.urlopen(head+a) #论文网址
html = resp.read()
html = html.decode()
#获取title
t1 = re.search(r‘\"papertitle\">‘,html)
t1 = html[t1.end()+1:]
t2 = re.search(r‘</div>‘,t1)
title = t1[:t2.start()]
print(i, file=data)
print("Title: ", title, file=data)
#获取abstract
a1 = re.search(r‘\"abstract\"‘, html)
a1 = html[a1.end()+3:]
a2 = re.search(r‘</div>‘, a1)
abstract = a1[:a2.start()]
print("Abstract: ", abstract,end="\n\n\n",file=data)
i=i+1
data.close()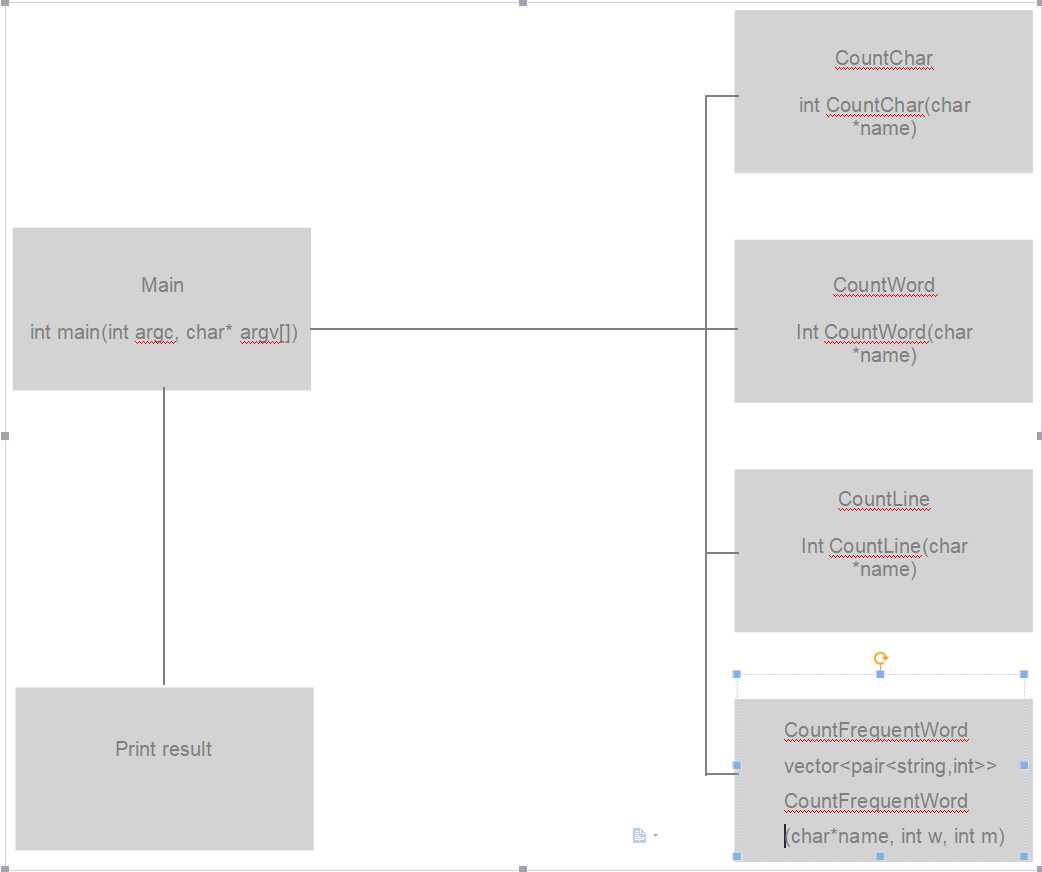
int solve(int l, int r, int w, int m) {
string s; int ch, now = 0, n1 = 0, cnt = 0;
string t;
rep(i, l, r) {
ch = a[i];
if (ch >= ‘A‘ && ch <= ‘Z‘) ch -= ‘A‘ - ‘a‘; //大写字母转小写
if (now == -2) { if (!checkword(ch) && !checknumber(ch)) now = 0; continue; }
// now == -2 表示现在处于非法单词中,只有遇到分隔符才能重新统计新一段单词,不然还是处于非法单词
if (checkword(ch)) { // 遇到字母自动机转移
now++; s += ch;
if (now == 1) fg[n1] = t, t = "";
continue;
}
if (checknumber(ch)) { // 遇到数字自动机转移
if (now >= 4) now++, s += ch;
else now = -2, s = "", t = "", ADD(n1, word, fg, w, m, cnt);
continue;
} // 遇到分隔符自动机转移
if (now >= 4) word[++n1] = s;
else if (now != 0) ADD(n1, word, fg, w, m, cnt); // 对一段合法单词去统计词组
t += ch;s = ""; now = 0;
}
if (now >= 4) {
word[++n1] = s, s = "";
ADD(n1, word, fg, w, m, cnt);
}
return cnt;
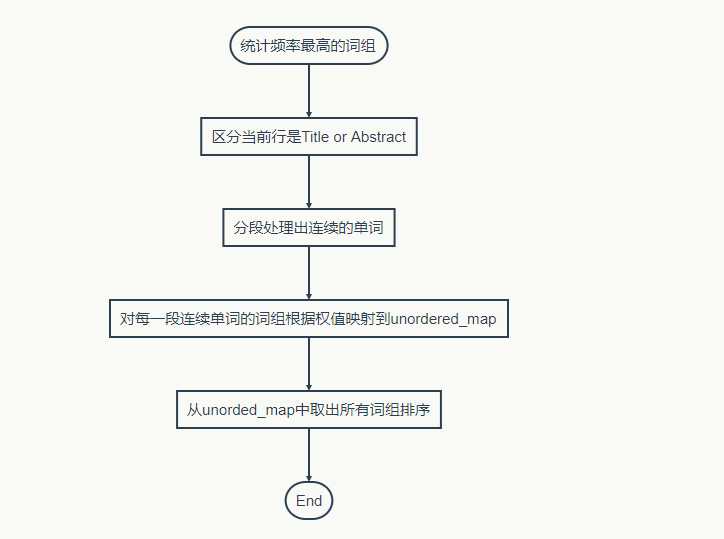
}这部分代码是在处理出一行是属于Title还是Abstract后去统计词组,由于一个词组中不能有不合法单词,相当于不合法的单词把一些合法的单词隔成了一段一段,我就是先把一段连续合法单词保存下来,再把这一段中的词组添加到unordered_map中。
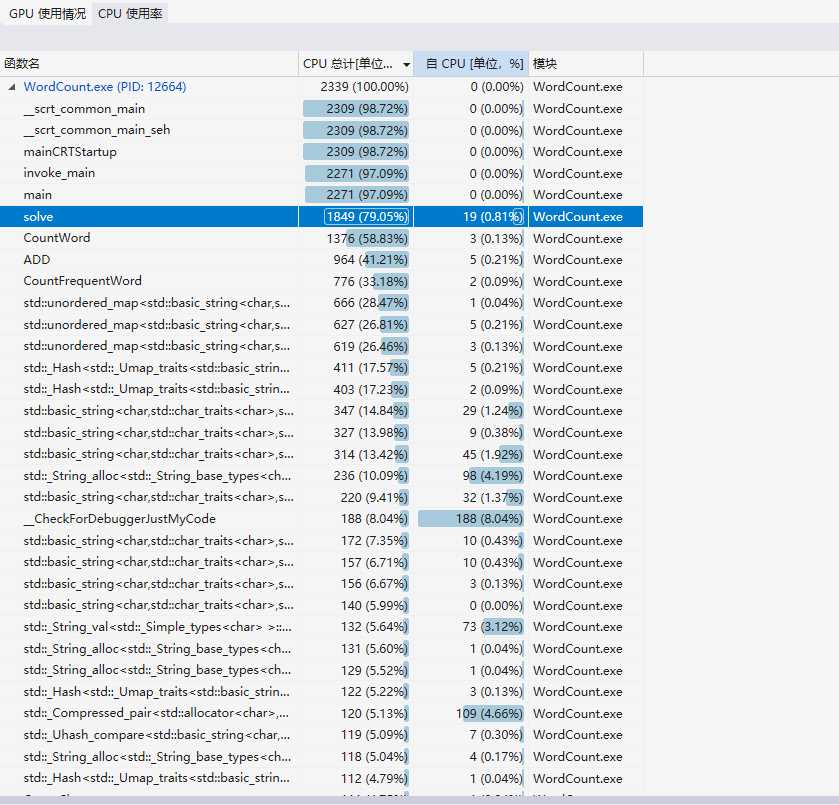
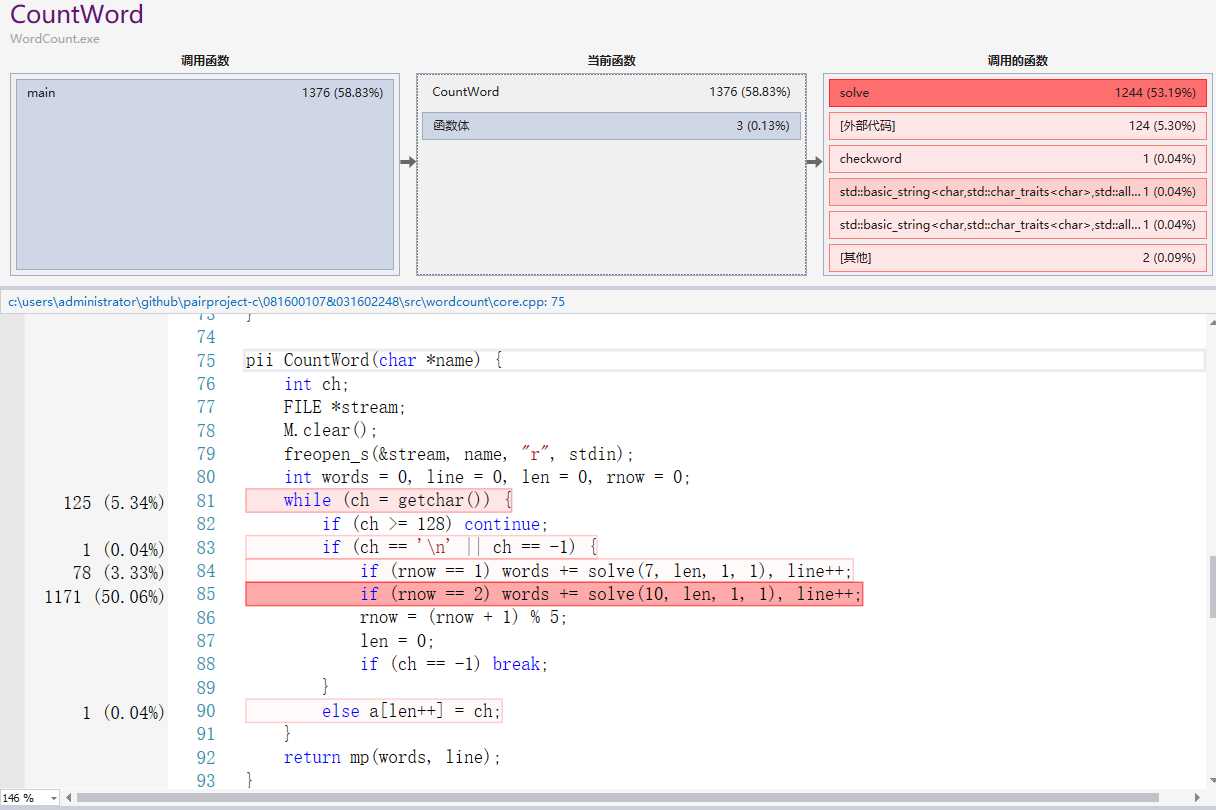
可以看出,时间消耗主要是在CountWord和CountFrequentWord部分,且主要是在其中调用unordered_map使字符串和数量映射在一起。其实CountWord部分不需要映射,因为只需要知道总单词数量即可,但我为了代码复用,可以把单词看成是长度为1的词组,所以一起用了unordered_map,如果性能要求很高的话可以在这进行改进。
对于映射的数据结构我觉得unordered_map效率已经比较高了,比map会快很多,而且代码难度比较低,我尝试用过字典树,但是由于这次是词组,所以长度会比较长,而且中间会出现非数字字母的分隔符,所以效率不高,总体来讲映射的数据结构这部分我觉得不需要改进了。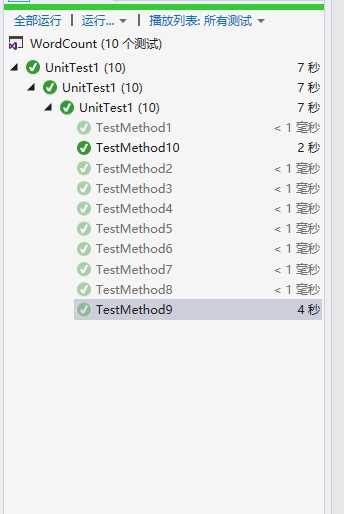
TEST_METHOD(TestMethod2)
{
char name[100];
strcpy_s(name, "../UnitTest1/test/test2.txt"); // 测试统计字符数
int count_chars = CountChar(name);
Assert::AreEqual(count_chars, 74);
}
TEST_METHOD(TestMethod4) // 测试统计单词数
{
char name[100];
strcpy_s(name, "../UnitTest1/test/test2.txt");
pii count_words = CountWord(name);
Assert::AreEqual(count_words.fi, 9);
}
TEST_METHOD(TestMethod6) // 测试统计有效行数函数
{
char name[100];
strcpy_s(name, "../UnitTest1/test/test2.txt");
pii count_words = CountWord(name);
Assert::AreEqual(count_words.se, 2);
}
// 9 和 10 用来测试数据较大时的效率和不同参数时词组频率统计
TEST_METHOD(TestMethod9)
{
char name[100];
strcpy_s(name, "../UnitTest1/test/test3.txt");
int count_chars = CountChar(name);
pii tmp = CountWord(name);
int count_words = tmp.fi;
int count_lines = tmp.se;
vector<pair<string, int> > word_rank = CountFrequentWord(name, 10, 3);
Assert::AreEqual(count_words, 117998);
Assert::AreEqual(count_chars, 1196799);
Assert::AreEqual(count_lines, 1958);
Assert::AreEqual(word_rank[0].fi, string("convolutional neural networks"));
Assert::AreEqual(word_rank[0].se, 196);
Assert::AreEqual(word_rank[1].fi, string("generative adversarial networks"));
Assert::AreEqual(word_rank[1].se, 177);
Assert::AreEqual(word_rank[2].fi, string("convolutional neural network"));
Assert::AreEqual(word_rank[2].se, 159);
}
TEST_METHOD(TestMethod10)
{
char name[100];
strcpy_s(name, "../UnitTest1/test/test3.txt");
int count_chars = CountChar(name);
pii tmp = CountWord(name);
int count_words = tmp.fi;
int count_lines = tmp.se;
vector<pair<string, int> > word_rank = CountFrequentWord(name, 10, 10);
Assert::AreEqual(count_words, 117998);
Assert::AreEqual(count_chars, 1196799);
Assert::AreEqual(count_lines, 1958);
Assert::AreEqual(word_rank[0].fi, string("partially shared multi-task convolutional neural network with local constraint"));
Assert::AreEqual(word_rank[0].se, 11);
Assert::AreEqual(word_rank[1].fi, string("beyond holistic object recognition: enriching image understanding with part states"));
Assert::AreEqual(word_rank[1].se, 10);
Assert::AreEqual(word_rank[2].fi, string("blazingly fast video object segmentation with pixel-wise metric learning"));
Assert::AreEqual(word_rank[2].se, 10);
}
我构造的单元测试1-8每两个测试一个功能:统计字符,统计单词,统计有效行数,统计词组频率,最后9和10用来测试总的爬下来的数据,同时测试效率和不同指令的功能。



爬虫部分:
1、`UnicodeEncodeError: ‘gbk‘ codec can‘t encode character ‘\xbb‘ in position 0: illegal multibyte sequence
解决方法:参考https://www.jb51.net/article/64816.html
data=open("D:\data.txt", ‘w+‘,encoding=‘utf-8‘) #打开输出文件并改为标准输出编码
2、<urlopen error [WinError 10060] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。>
解决方法:参考https://www.cnblogs.com/lliuye/p/8406267.html
没采取措施,在第二次爬取数据时没有出现此问题,顺利完成。
队友:wordcount部分
问题描述
一开始的时候我打算用字典树去存储得到的字符串,但是再指令m比较大的时候,每个词组会比较长,导致效率比较低,而且有时还会runtime error,应该是数组访问越界。
解决方案
我把所有字符输出来看后发现有些不在ASCII码的范围内,比如é这种,然后我就把它先过滤掉了,之后我尝试了一下改用unordered_map,发现效率比较高,我就马上改了,感觉之前用字典树在这种情况下完全不如unordered_map。
体会
让我对数据结构的选取更加有经验了,而且知道了要更细致地考虑输入数据,可能会有一些不合法的输入要过滤掉,使程序的鲁棒性更好。
评价傅滨:
队友很强,行动力很强,分工明确,完成的快!
| 日期 | 10月8日 | 10月9日 | 10月10日 |
|---|---|---|---|
| 完成任务 | 完成主函数和字符统计功能 | 完成词频统计功能 | 完成单元测试 |
| 完成爬虫 | 学习爬虫 |
原文:https://www.cnblogs.com/Zzwena/p/9768881.html