051601135 岳冠宇 博客地址
051604103 陈思孝 博客地址
我实现了爬虫工具及wordcount的代码测试,队友实现wordcount新增功能的实现。
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 35 |
| · Estimate | · 估计这个任务需要多少时间 | 30 | 35 |
| Development | 开发 | 910 | 870 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 70 |
| · Design Spec | · 生成设计文档 | 20 | 30 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| · Design | · 具体设计 | 50 | 30 |
| · Coding | · 具体编码 | 700 | 650 |
| · Code Review | · 代码复审 | 30 | 50 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 30 |
| Reporting | 报告 | 120 | 130 |
| · Test Repor | · 测试报告 | 90 | 90 |
| · Size Measurement | · 计算工作量 | 0 | 0 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 40 |
| 合计 | 1060 | 1035 |
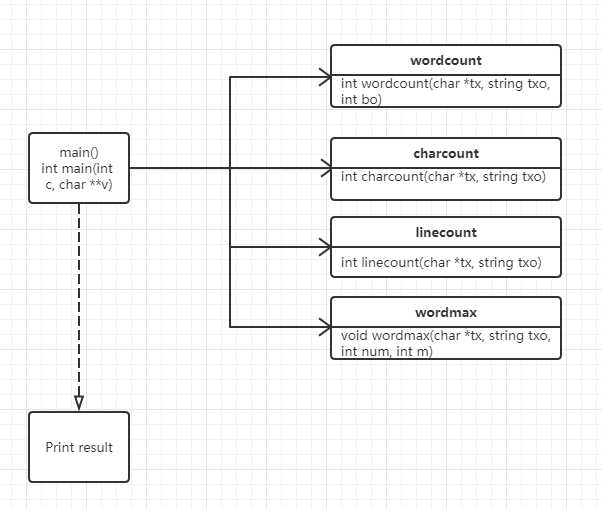
代码组织与内部实现设计(类图)

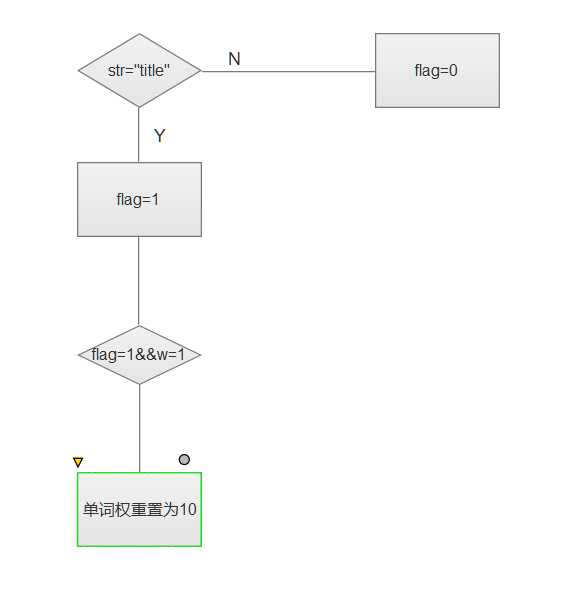
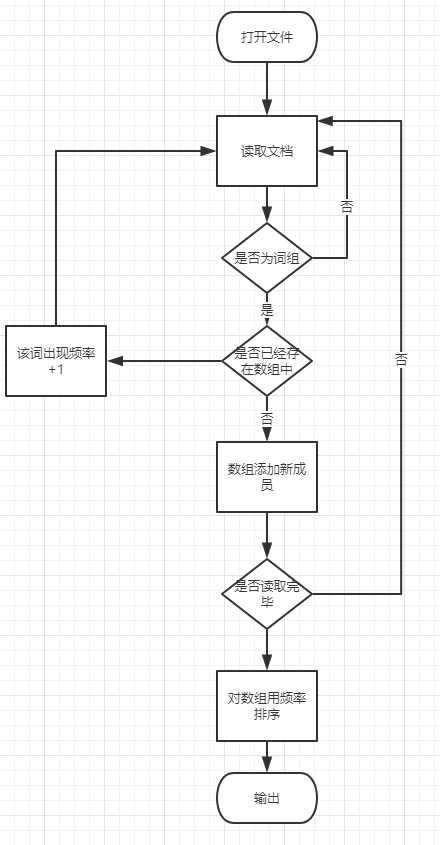
说明算法的关键与关键实现部分流程图
处理新增权重的要求
先定位title和abstract标签的位置,设置flag。遇到title,flag置为1,并且w=1,后面的统计单词权重置为10,遇到abstarct,flag置为0。
int wordcnt = 0;
int k, i, j, x=1, y=1;
if (bo == 1)
y = 10;
char p,m;
while (!feof(fp))
{
char c = getc(fp);
if ((c >= ‘a‘&&c <= ‘z‘) || (c >= ‘A‘&&c <= ‘Z‘))//可能是单词
{
k = 0;//从第0位开始判断
while ((c >= ‘a‘&&c <= ‘z‘) || (c >= ‘A‘&&c <= ‘Z‘) || (c >= ‘0‘&&c <= ‘9‘&&k >= 4))//继续后几位的验证
{
if (c >= ‘A‘&&c <= ‘Z‘)//大写改小写
{
c = c + 32;
}
temp.s[k] = c;
m = temp.s[k];
k++;//下一位
c = getc(fp);
p = c;
if (c == ‘:‘&&m == ‘e‘)
temp.bl = y;
if (c == ‘:‘&&m == ‘t‘)
temp.bl = x;//改变权重
}
temp.s[k] = ‘\0‘;//结束标识
k++;//此词位数+1
j = n;
if (strlen(temp.s) >= 4)//确保大于4位英文字母
{
wordcnt++;//词频置1
if (temp.bl == y)
temp.frq = y;
if (temp.bl == x)
temp.frq = x;
}
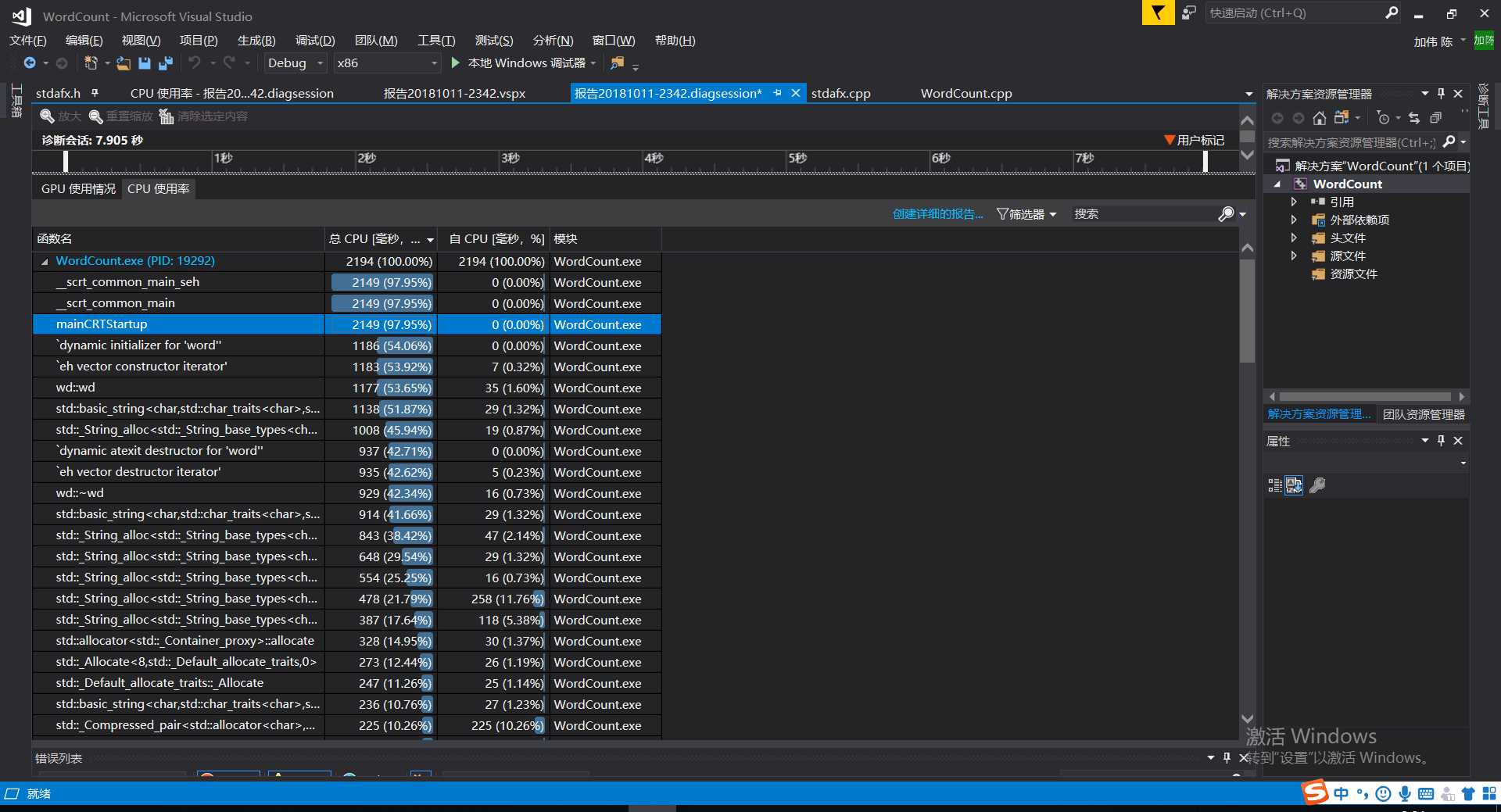
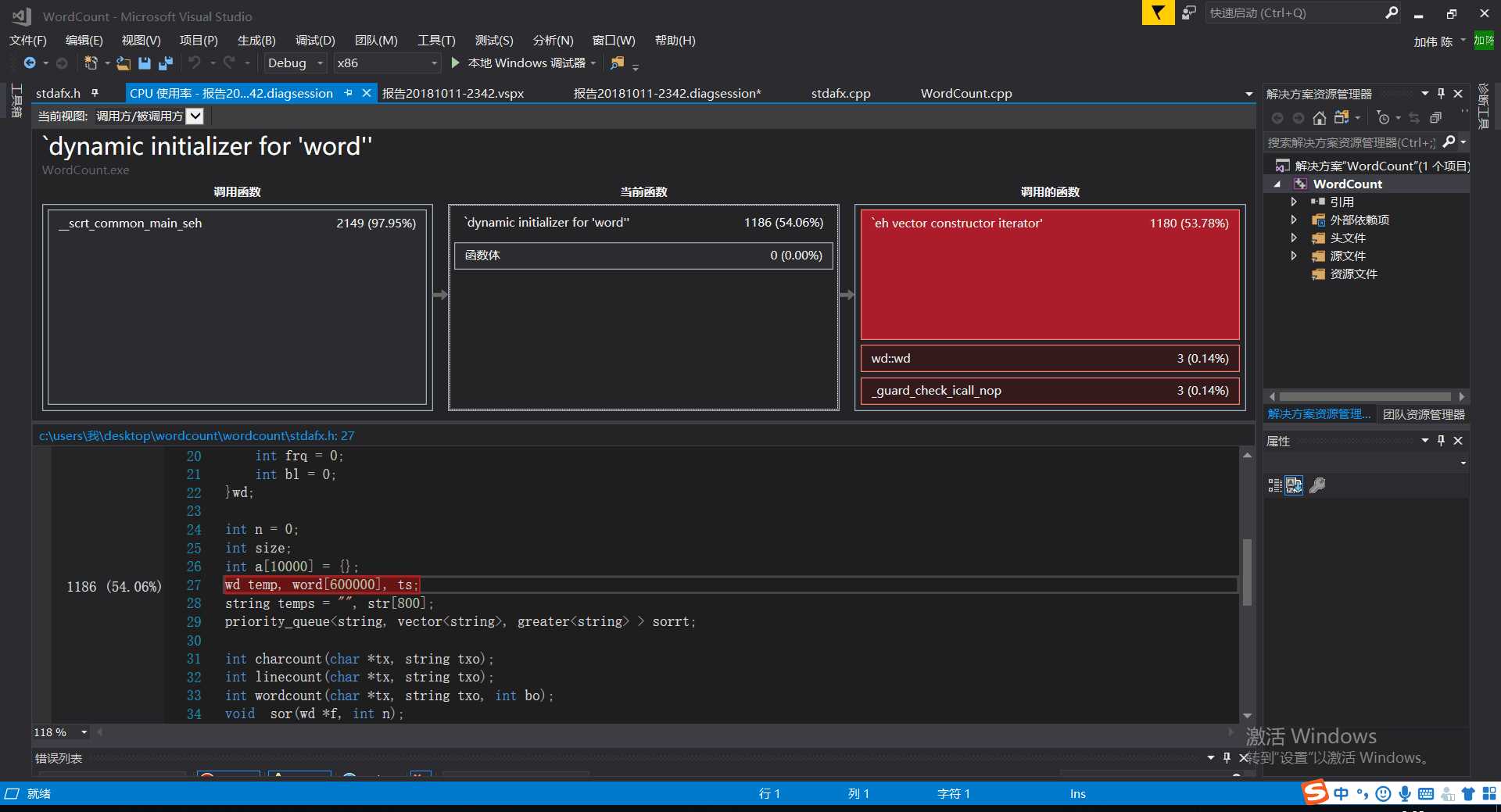
可以看出,时间主要消耗在了创建数组上,而且整个代码效率不高。
可以用链表STL map工具来实现这次作业,效率能高很多,而且对空间的利用恰到好处
对实现的每个功能模块进行不同情况下的测试,用assert断言判断正确与否。
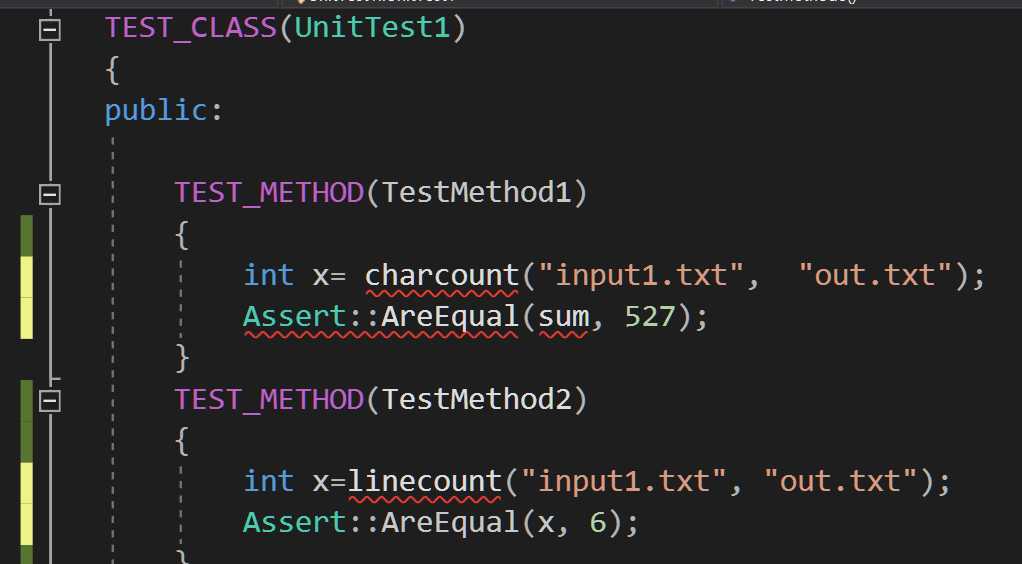
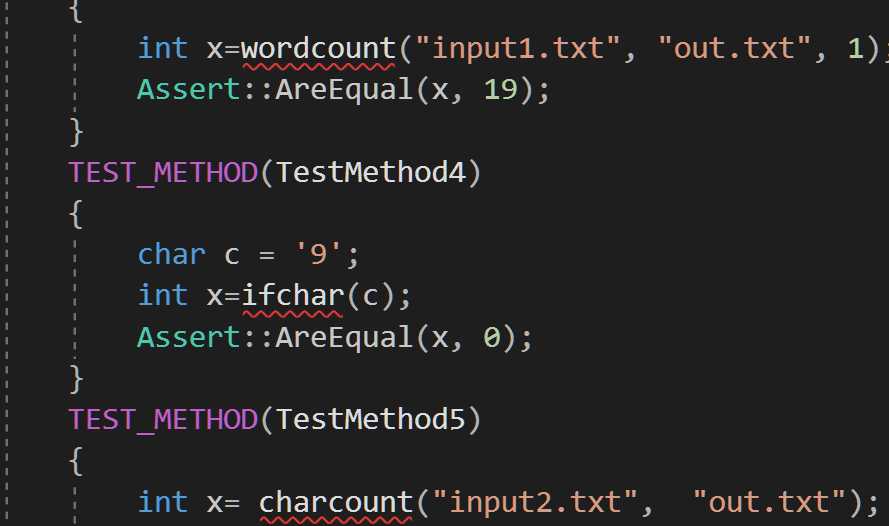
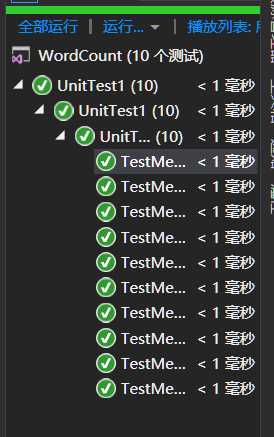
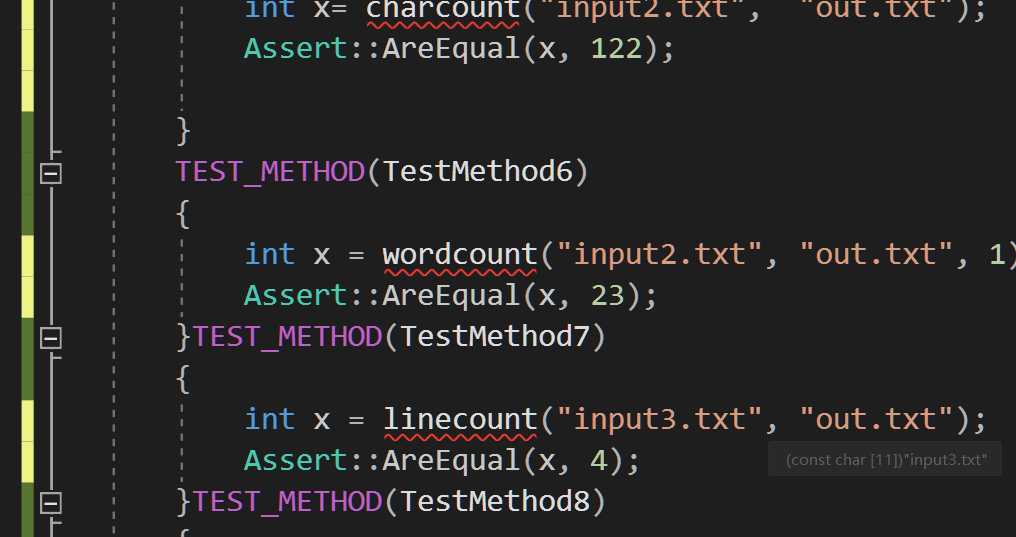
执行力强,能快速实现功能。
但解决问题的能力还需要提高。
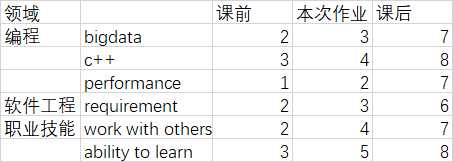
原文:https://www.cnblogs.com/void-lambda/p/9780107.html