(1)安装scipy,numpy,sklearn包
import numpy from sklearn.datasets import load_iris
(2)从sklearn包自带的数据集中读出鸢尾花数据集data
data = load_iris()
(3)查看data类型,包含哪些数据
print(‘数据类型:‘,type(data)) print(‘数据内容:‘,data.keys())
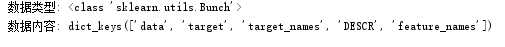
(4)取出鸢尾花特征和鸢尾花类别数据,查看其形状及数据类型
iris_feature = data[‘feature_names‘],data[‘data‘] print(‘鸢尾花数据:‘,iris_feature) iris_target = data.target,data.target_names print(‘鸢尾花形状类别:‘,iris_target)


(5)取出所有花的花萼长度(cm)的数据
sepal_length = numpy.array(list(len[0] for len in data[‘data‘])) print(‘所有花萼长度:‘,sepal_length)
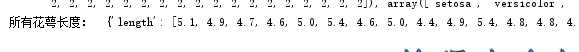
(6)取出所有花的花瓣长度(cm)+花瓣宽度(cm)的数据
petal_length = numpy.array(list(len[2] for len in data[‘data‘])) petal_length.resize(5,30) petal_width = numpy.array(list(len[3] for len in data[‘data‘])) petal_width.resize(5,30) iris_lens = (petal_length,petal_width) print(‘所有花瓣长宽:‘,iris_lens)

(7)取出某朵花的四个特征及其类别
print(‘特征:‘,data[‘data‘][0]) print(‘类别:‘,data[‘target‘][0])

(8)将所有花的特征和类别分成三组,每组50个
iris_setosa = [] iris_versicolor = [] iris_virginica = []
(9)生成新的数组,每个元素包含四个特征+类别
datas = (iris_setosa,iris_versicolor,iris_virginica) print(‘新数组分类结果:‘,datas)
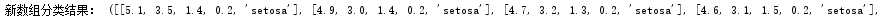
原文:https://www.cnblogs.com/zhangjij/p/9784570.html