作业:
1. 安装scipy,numpy,sklearn包
2. 从sklearn包自带的数据集中读出鸢尾花数据集data
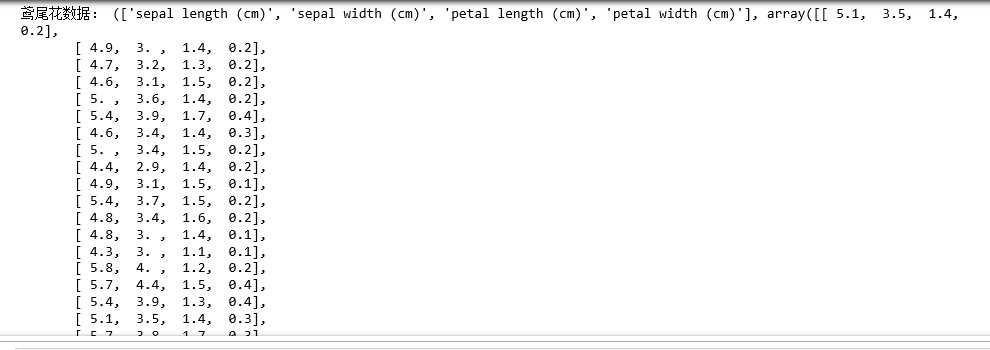
3.查看data类型,包含哪些数据
4.取出鸢尾花特征和鸢尾花类别数据,查看其形状及数据类型
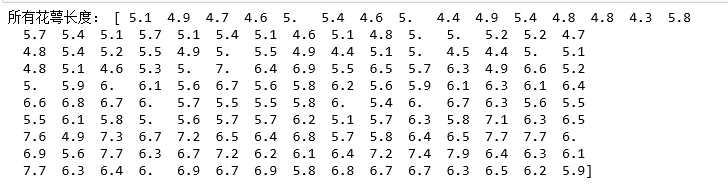
5.取出所有花的花萼长度(cm)的数据
6.取出所有花的花瓣长度(cm)+花瓣宽度(cm)的数据
7.取出某朵花的四个特征及其类别。
8.将所有花的特征和类别分成三组,每组50个
9.生成新的数组,每个元素包含四个特征+类别
1 #安装scipy,numpy,sklearn包 2 import numpy as np 3 from sklearn.datasets import load_iris 4 5 #从sklearn包自带的数据集中读出鸢尾花数据集data 6 data = load_iris() 7 8 #查看data类型,包含哪些数据 9 print(‘数据类型是:‘,type(data)) 10 print(‘包含的数据有:‘,data.keys()) 11 12 #取出鸢尾花特征和鸢尾花类别数据,查看其形状及数据类型 13 iris_feature = data[‘target‘] 14 print(‘鸢尾花的特征是:‘,iris_feature) 15 iris_target = data[‘target_names‘] 16 print(‘鸢尾花的类别数据是:‘,iris_target) 17 iris_shape = iris_feature,iris_target 18 print(‘鸢尾花的形状是:‘,iris_shape) 19 print(‘鸢尾花的数据类型是:‘,type(iris_shape)) 20 21 #取出所有花的花萼长度(cm)的数据 22 sepal_length = numpy.array(list(len[0] for len in data[‘data‘])) 23 print(‘所有花萼长度是:‘,sepal_length) 24 25 #取出所有花的花瓣长度(cm) + 花瓣宽度(cm)的数据 26 petal_length = numpy.array(list(len[2] for len in data[‘data‘])) 27 petal_length.resize(15,10) 28 petal_width = numpy.array(list(len[3] for len in data[‘data‘])) 29 petal_width.resize(15,10) 30 iris_lens = (petal_length,petal_width) 31 print(‘所有花瓣的长度+宽度是:‘,iris_lens) 32 33 #取出某朵花的四个特征及其类别。 34 print(‘特征是:‘,data[‘data‘][0]) 35 print(‘类别是:‘,data[‘target‘][0]) 36 37 #将所有花的特征和类别分成三组,每组50个 38 iris_setosa = [] #存放类别为setosa的数据组 39 iris_versicolor = [] #存放类别为versicolor的数据组 40 iris_virginica = [] #存放类别为virginica的数据组 41 ##利用for循环分类 42 for x in range(0,150): 43 if data[‘target‘][x] == 0: 44 datas = data[‘data‘][x].tolist() 45 datas.append(‘setosa‘) 46 iris_setosa.append(datas) #当target为0时,对应setosa类型,生成数据组 47 elif data[‘target‘][x] == 1: 48 datas = data[‘data‘][x].tolist() 49 datas.append(‘versicolor‘) 50 iris_versicolor.append(datas) #当target为1时,对应versicolor类型,生成数据组 51 else: 52 datas = data[‘data‘][x].tolist() 53 datas.append(‘virginica‘) 54 iris_versicolor.append(datas) #其余的对应virginica类型,生成数据组 55 56 #生成新的数组,每个元素包含四个特征 + 类别 57 iris_setosa = [] #定义三个新列表用于存放数据 58 iris_versicolor = [] 59 iris_virginica = [] 60 61 for i in range(0,150):#用for循环分类,并把target为0和1分别放入setosa类型和versicolor存放 62 if data[‘target‘][i] == 0: 63 data1 = data[‘data‘][i].tolist() 64 data1.append(‘setosa‘) 65 iris_setosa.append(data1) 66 elif data[‘target‘][i] == 1: 67 data1 = data[‘data‘][i].tolist() 68 data1.append(‘versicolor‘) 69 iris_versicolor.append(data1) 70 else: 71 data1 = data[‘data‘][i].tolist() 72 data1.append(‘virginica‘) 73 iris_virginica.append(data1 74 75 data2 = (iris_setosa,iris_versicolor,iris_virginica)#生成新的数组,每个元素包含四个特征+类别 76 print(‘新数组分类结果:‘,data2)





原文:https://www.cnblogs.com/la-vie/p/9795029.html