在DataFrame数据表里面提取需要的行
代码功能:
在DataFrame表格中使用loc(),得到我们想要的行,然后根据某一列元素的值进行排序
此代码中还展示了为DataFrame添加列,即直接name_DataFrame[‘diff‘]=___即可,同时可以依据新添加的列元素的值,来对dataframe进行排序
import pandas as pd unames = [‘user_id‘, ‘gender‘, ‘age‘,‘occupation‘,‘zip‘] users = pd.read_table(‘users.dat‘, sep=‘::‘,header=None, names=unames) rnames = [‘user_id‘, ‘movie_id‘, ‘rating‘, ‘timestamp‘] ratings = pd.read_table(‘ratings.dat‘, sep=‘::‘, header=None, names=rnames) mnames = [‘movie_id‘, ‘title‘, ‘genres‘] movies = pd.read_table(‘movies.dat‘, sep=‘::‘, header=None, names=mnames) data = pd.merge(pd.merge(ratings,users),movies) mean_ratings = pd.pivot_table(data,index=[‘title‘],values=‘rating‘,columns=‘gender‘) print(mean_ratings[:10]) ratings_by_title = data.groupby(‘title‘).size() print(ratings_by_title[:10]) active_titles = ratings_by_title.index[ratings_by_title >= 250] print(active_titles) active_mean_ratings = mean_ratings.loc[active_titles] top_female_ratings = active_mean_ratings.sort_index(by=‘F‘, ascending=False) active_mean_ratings[‘diff‘] = active_mean_ratings[‘M‘] - active_mean_ratings[‘F‘] sorted_by_diff = active_mean_ratings.sort_index(by=‘diff‘) print(sorted_by_diff[::-1][:15]) #注意对dataframe进行倒序访问的方法
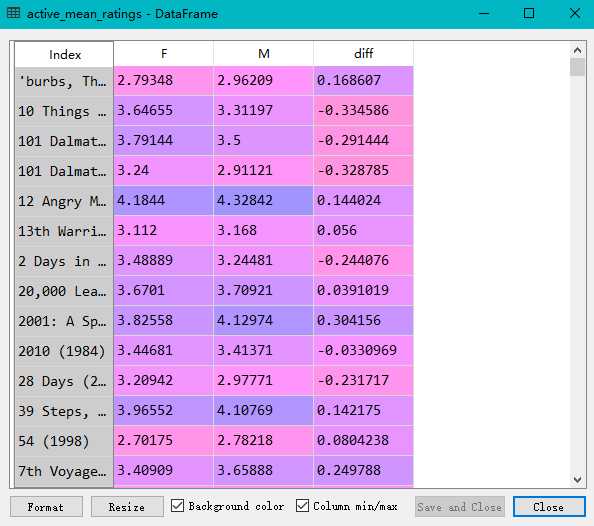
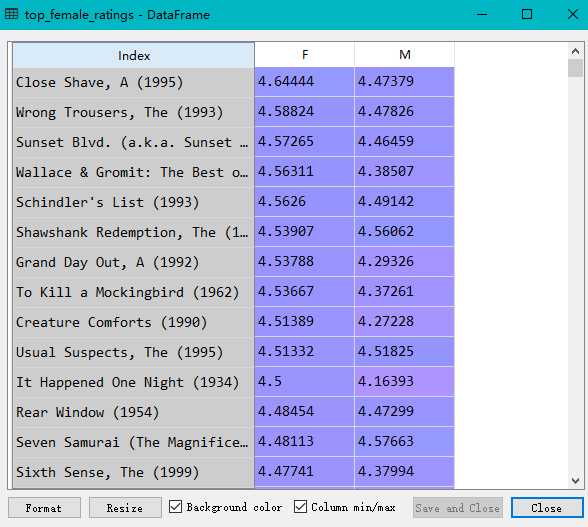
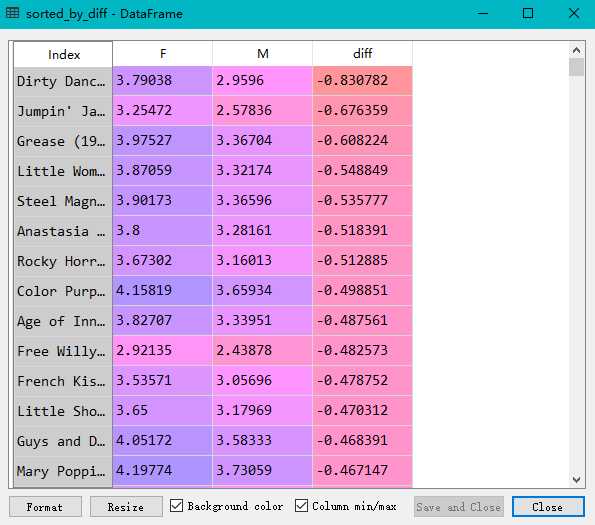
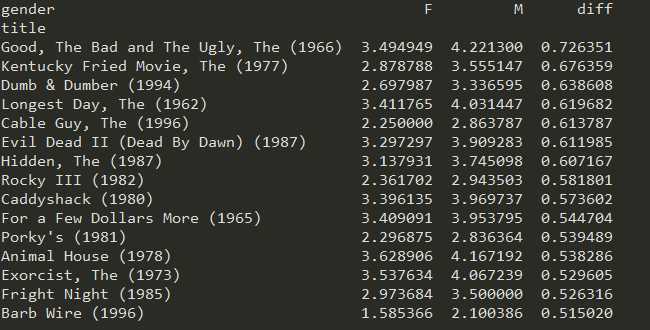
原文:https://www.cnblogs.com/chensimin1990/p/9802065.html