本周学习了第10章树
一些术语
根结点是位于树顶层的唯一结点
位于树中较低层的结点是上一层结点的孩子,一个结点只有一个双亲
同一双亲的两个结点称为兄弟
根结点是树中唯一没有双亲的结点,没有任何孩子的结点称为叶子,其余为内部结点
结点的层是从根结点到该结点的路径长度
树的高度是指从根到叶子之间最远路径的长度
如果一颗n元树的所有叶子都位于同一层且每一结点要么是一片叶子要么正好有n个孩子,则称此树是满的
| 操作 | 说明 |
|---|---|
| getRoot | 返回指向二叉树根的引用 |
| isEmpty | 判定该树是否为空 |
| size | 判定树中的元素数目 |
| contains | 判定指定目标是否在该树中 |
| find | 如果找到指定元素,返回指向其的引用 |
| toString | 返回树的字符串表示 |
| iteratorInOrder | 为树的中序遍历返回一个迭代器 |
| iteratorPreOrder | 为树的前序遍历返回一个迭代器 |
| iteratorPostOrder | 为树的后序遍历返回一个迭代器 |
| iteratorLevelOrder | 为树的层序遍历返回一个迭代器 |
在所有列举的操作中 ,不存在往树中添加元素的操作。在一些树中也没有删除树元素的操作
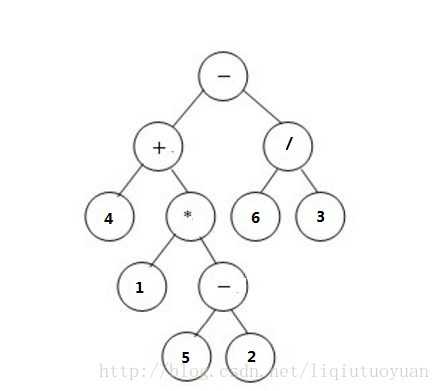
public boolean isOperator(){
return (termType == 1);
}为什么需要判断termType为一时就是运算符
private int termType;
private char operator;
private int value;结点存储只需要一个int变量存储操作数,一个char变量存储运算符。多出来的int变量termType说明就不是用于存储操作数。在这个类中,我发现termType的用处都是用来判断是否为操作数的,所以设置这个变量的意义就应该在于事先在设置结点时,就标明这个结点存储的是什么东西,如果是运算符就把termType改为1,不是就设为其他数,这样就避免了在判断时要写一长串的判断条件if (operator == "+" || operator == "-" || operator == "*" || operator == "/")的情况
public String printTree() {
UnorderedListADT<BinaryTreeNode<ExpressionTreeOp>> nodes = new ArrayUnorderedList<BinaryTreeNode<ExpressionTreeOp>>();//创建了一个存储BinaryTreeNode类的无序列表
UnorderedListADT<Integer> levelList = new ArrayUnorderedList<Integer>();//创建一个存储int变量的无序列表
BinaryTreeNode<ExpressionTreeOp> current;//设置指向无序列表的一个临时变量current
String result = "";
int printDepth = this.getHeight();//定义printDepth表示树的高度
int possibleNodes = (int) Math.pow(2, printDepth + 1);//定义possibleNodes表示可能的树的结点数量多少,possibleNodes = 2 ^ (printDepth + 1)
int countNodes = 0;
nodes.addToRear(root);//把根结点添加到无序列表末尾
Integer currentLevel = 0;
Integer previousLevel = -1;//设置两个int变量,为接下来的换行操作进行判断
levelList.addToRear(currentLevel);//currentLevel添加到levelList末尾
while (countNodes < possibleNodes) {
countNodes = countNodes + 1;
current = nodes.removeFirst();//current为nodes移除的首位
currentLevel = levelList.removeFirst();
if (currentLevel > previousLevel) {
result = result + "\n\n";//如果curreLevel大于previousLevel,就进行换行操作
previousLevel = currentLevel;
for (int j = 0; j < ((Math.pow(2, (printDepth - currentLevel))) - 1); j++)
result = result + " ";//换行之后添加空格
} else {
for (int i = 0; i < ((Math.pow(2,
(printDepth - currentLevel + 1)) - 1)); i++) {
result = result + " ";//不进行换行操作,表明是某一层中的中间的某一结点,在两个结点之间添加空格
}
}
if (current != null) {
result = result + (current.getElement()).toString();//将当前树的根结点加到result串中
nodes.addToRear(current.getLeft());
levelList.addToRear(currentLevel + 1);
nodes.addToRear(current.getRight());
levelList.addToRear(currentLevel + 1);//将前一个根结点的左右孩子都存入nodes的尾部,curreLevel+1存入levelList表示左右孩子是在根结点的下一行
} else {
nodes.addToRear(null);
levelList.addToRear(currentLevel + 1);
nodes.addToRear(null);
levelList.addToRear(currentLevel + 1);
result = result + " ";
}
}
return result;
}我觉得这部分代码难理解的地方在于为了输出时的图像接近于我们一般的树的结构图而进行的换行操作和添加空格的操作。
判断某个结点在第几层时运用了一个levelList的一个列表,以及两个int变量currentLevel和previousLevel分别赋值为0和-1,通过currentLevel和previousLevel的关系判断是否需要换行,例如循环到第二层时,nodes里有了左右孩子两个结点,levelList里首位和第二位此时存储的都是1,而previousLevel此时为0,首先循环时currentLevel = levelList.removeFirst,currentLevel=1>previousLevel=0,所以需要另起一行result = result + "\n\n",之后将previousLevel赋为当前的currentLevel的值previousLevel = currentLevel;,current此时为nodes首位即左孩子,加入result字符串,再将左孩子的左右孩子分别加入列表尾,它们对应的levelList里的值为currentLevel+1=2,之后将列表头右孩子赋给current,此时的currLevel=previousLevel=1,所以走else这条路,不需要换行然后进行接下来的操作,如果右孩子为叶结点,虽然没有子结点,但是依然会留有存储空间nodes.addToRear(current.getLeft());,只不过里面存放的是null,所以输出时计算机走到此处会继续执行,并不断创建新的存储空间。所以在外面需要套一层while循环,因为二叉树前n层有不高于2^(n+1)个元素,所以定义possibleNodes的值为int possibleNodes = (int) Math.pow(2, printDepth + 1);
另外关于加空格的方法不是太懂,譬如为何要这么定义j < ((Math.pow(2, (printDepth - currentLevel))) - 1)在两个结点之间添加空格。
关于两者的取值好像也不是那么严格,也就是不一定非要取0和-1,换成1和0,-1和-2之类也是可以的,只不过取值的不同会影响树结构的宽窄,或者两者的差值也不一定需要为1,差2差3好像都没有问题,只不过后面levelList.addToRear(currentLevel + 1);的方法,对应就该加2或者加3了。
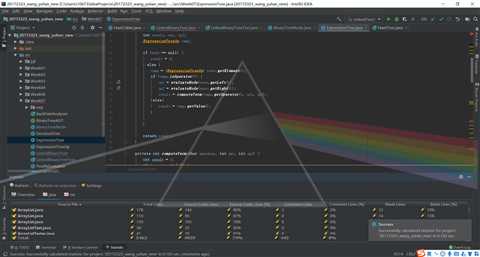
问题1:运行expressionTree类的printTree方法时,树的结构没有全部打印出来,如图
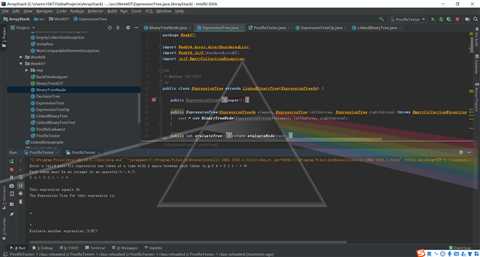
BinaryTreeNode cur = root;
int height = 0;
if (root != null){
height++;
}
cur = cur.left;
while (cur.judge() != true){
height++;
cur = cur.left;
}
height++;
return height;代码修改后的运行截图为
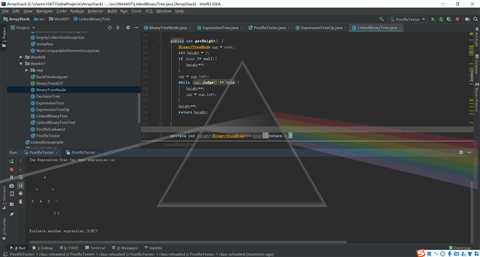
问题2:使用LinkedBinaryTree的toString方法时最终输出一串乱码
问题2解决方案:在网上寻找解决方案,然后了解到数组是没有toString方法的。
Object中的toString()方法,是将传入的参数的类型名和摘要(字符串的hashcode的十六进制编码)返回,直接对数组使用了toString()方法,就会得到 一个Ljava.lang.String;@175d6ab
其中,Ljava.lang.String 是指数据是String类型的
虽然这里给出的乱码信息是3ecf72fd,但是他给出的解决方案是使用循环的方法来输出数组中的每一个值,姑且一试
这里输出树的结构需要用到递归,然后输出时有点奇怪的就是我把右孩子放在其双亲的上面,左孩子放在双亲的下面,所以会有些不像树的形状
public void oString() {
string(root);
}
private void string(BinaryTreeNode temp){
if(temp != null){
string(temp.getRight());
System.out.println(temp.getElement() + " ");
string(temp.getLeft());
}
}输出结果如图
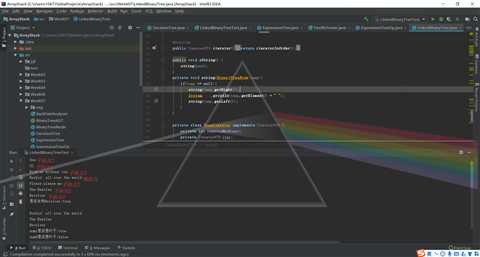
凑合也能看
上周没有错题哦
基于评分标准,我给谭鑫的博客打分:8分。得分情况如下:
正确使用Markdown语法(加1分):
模板中的要素齐全(加1分)
教材学习中的问题和解决过程, 三个问题加3分
代码调试中的问题和解决过程, 三个问题加3分
基于评分标准,我给方艺雯的博客打分:8分。得分情况如下:、
正确使用Markdown语法(加1分):
模板中的要素齐全(加1分)
教材学习中的问题和解决过程, 两个问题加2分
代码调试中的问题和解决过程, 三个问题加3分
排版精美加1分
本周的学习情况还算不错,最困难的地方不在于几个PP项目,反而在于问题中提到的那个printTree的代码的理解。不过在考试中发挥得有点糟糕,不知道怎么的错了两道不该错的题
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/1 | 8/8 | |
| 第二周 | 470/470 | 1/2 | 12/20 | |
| 第三周 | 685/1155 | 2/4 | 10/30 | |
| 第四周 | 2499/3654 | 2/6 | 12/42 | |
| 第六周 | 1218/4872 | 2/8 | 10/52 | |
| 第七周 | 590/5462 | 1/9 | 12/64 |
20172323 2018-2019-1 《程序设计与数据结构》第六周学习总结
原文:https://www.cnblogs.com/Lewandodoski/p/9843171.html