前言
hive是构建在Hadoop上的数据仓库平台,其设计目标是:使Hadoop上的数据操作与传统的SQL结合,让熟悉sql的开发人员能够轻松的像Hadoop平台迁移。
Hive是Facebook的信息平台的重要组成部分,Facebook在2008年将其共献给Apache,现在Hive是Hadoop家族中一款数据仓库产品。
Hive最大的特点是:提供了类SQL的语法,封装了底层的MapReduce过程,让有SQL基础的业务人员,也可以也利用Hadoop进行大数据的操作。就是这一个点,解
决了原数据分析人员对于大数据分析的瓶颈。让我们把Hive的环境构建起来,帮助非开发人员也能更好地了解大数据。
目录
Hive起源于Facebook,它使得针对Hadoop进行SQL查询成为可能,从而非程序员也可以方便地使用。Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务运行。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
Hive包含shell环境、元数据库、解析器和数据仓库等组件,它的体系结构如下:
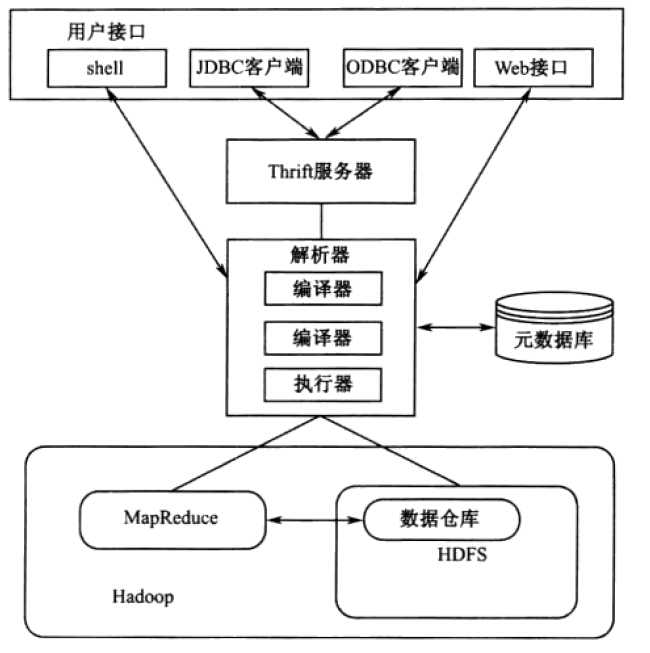
hive包括如下相关组件:
1). 帮助无开发经验的数据分析人员,有能力处理大数据
完全符合与Hive的设计理念,一直在强调,无需多言。
2). 构建标准化的MapReduce开发过程
这个方面是我们需要努力的方向。
首先,Hive已经用类SQL的语法封装了MapReduce过程,这个封装过程就是MapReduce的标准化的过程。
我们在做业务或者工具时,会针对场景用逻辑封装,这是第二层封装是在Hive之上的封装。在第二层封装时,我们要尽可能多的屏蔽Hive的细节,让接口单一化,低少灵活性,再次精简HQL的语法结构。只满足我们的系统要求,专用的接口。
在使用二次封装的接口时,我们已经可以不用知道Hive是什么, 更不用知道Hadoop是什么。我们只需要知道,SQL查询(SQL92标准),怎么写效率高,怎么写可以完成业务需要就可以了。
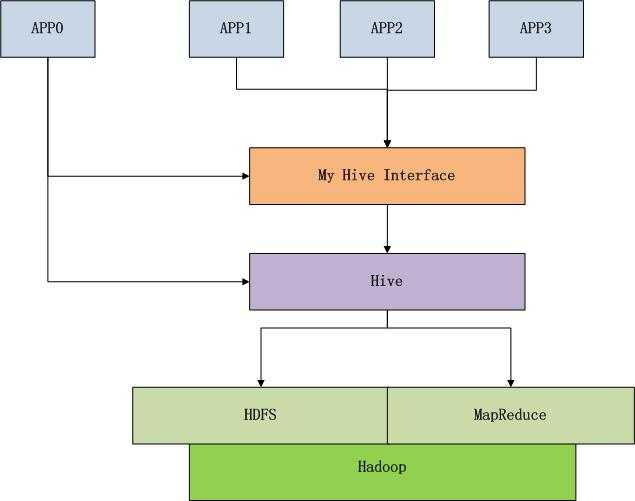
当我们完成了Hive的二次封装后,我们可以构建标准化的MapReduce开发过程。
通过上图的思路,我们可以统一企业内部各种应用对于Hive的依赖,并且当人员素质升高后,有可以剥离Hive,用更优秀的底层解决方案来替换,如果封装的接口的不变,甚至替换Hive时业务使用都不知道,我们已经替换了Hive。
这个过程是需要经历的,也是有意义的。当我在考虑构建Hadoop分析工具时,以Hive作为Hadoop访问接口是最有效的。
3). 有关Hive的运维:
因为Hive是基于Hadoop构建的,简单地说就是一套Hadoop的访问接口,Hive本身并没有太多的东西,所以运维上面我们注意下面几个问题就行了。
hive的学习入门(飞进数据仓库的小蜜蜂),布布扣,bubuko.com
原文:http://www.cnblogs.com/joqk/p/3875500.html