Image Caption
Automatically describing the content of an image
CV+NLP
数据集:Flickr8k,Flickr30k,MSCOCO,Visual Genome
评测指标:BLEU,METEOR,CIDEr,ROUGE
Learning to Evaluate Image Captioning(CVPR 2018)
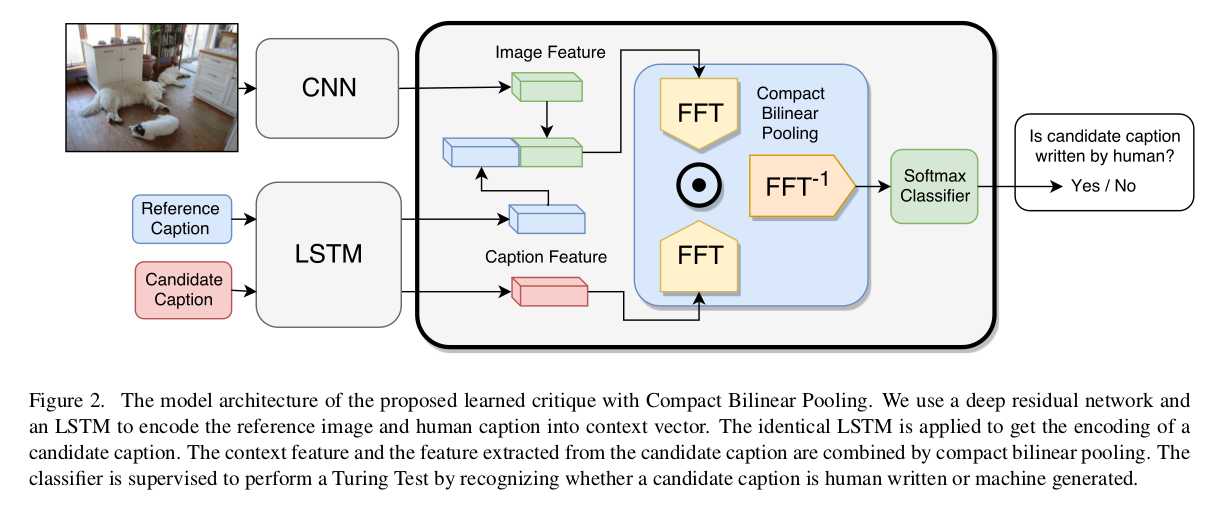

Show and Tell: A Neural Image Caption Generator(CVPR 2015)
directly maximize the probability of the correct description given the image by using the following formulation:
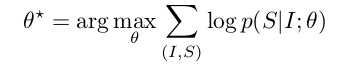
θ are the parameters of our model, I is an image, and S its correct transcription
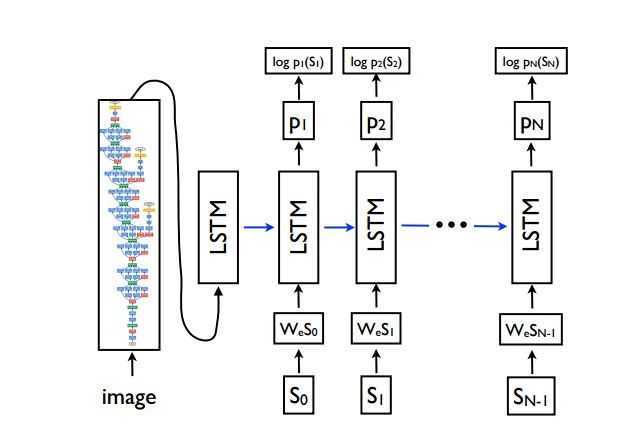
Encoder:Inception-V2
Decoder:LSTM
Inference:BeamSearch
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention (ICML 2015)
Highlight:Attention Mechnism(Soft&Hard)
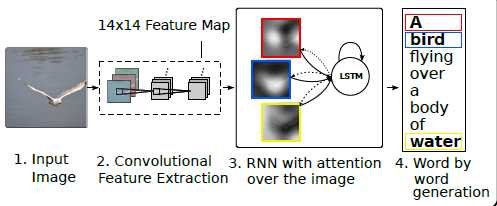
"Soft" attention:different parts,different subregions
"Hard" attention:only one subregion.Random choice
Sumary:
1.Attention involves focus of certain parts of input
2.Soft Attention is Deterministic.Hard attention is Stochastic.
3.Attention is used in NMT, AttnGAN, teaching machines to read.
Image Captioning with Semantic Attention(CVPR 2016)
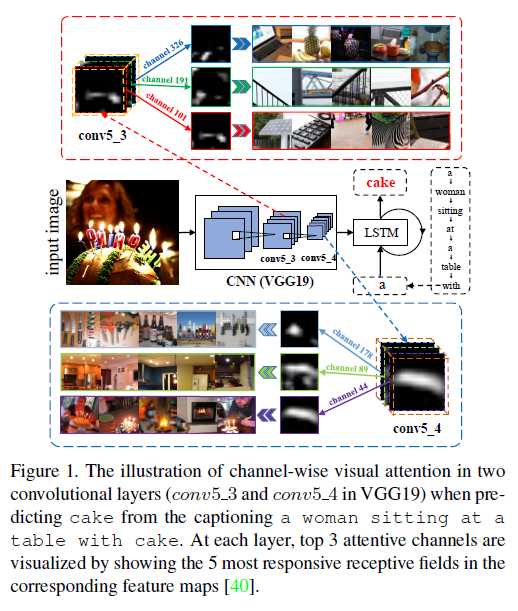
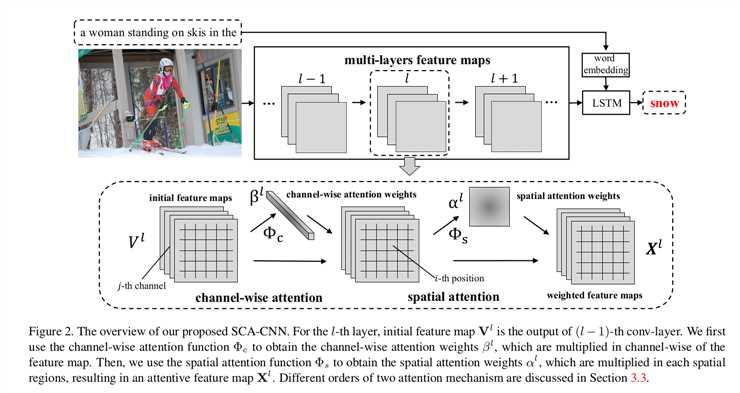
SCA-CNN: Spatial and Channel-Wise Attention in Convolutional Networks for Image Captioning(CVPR 2017)
Highlight:Spatial and Channel-Wise Attention
Knowing When to Look: Adaptive Attention via a Visual Sentinel for Image Captioning(CVPR 2017)
Hightlight:Adaptive Attention
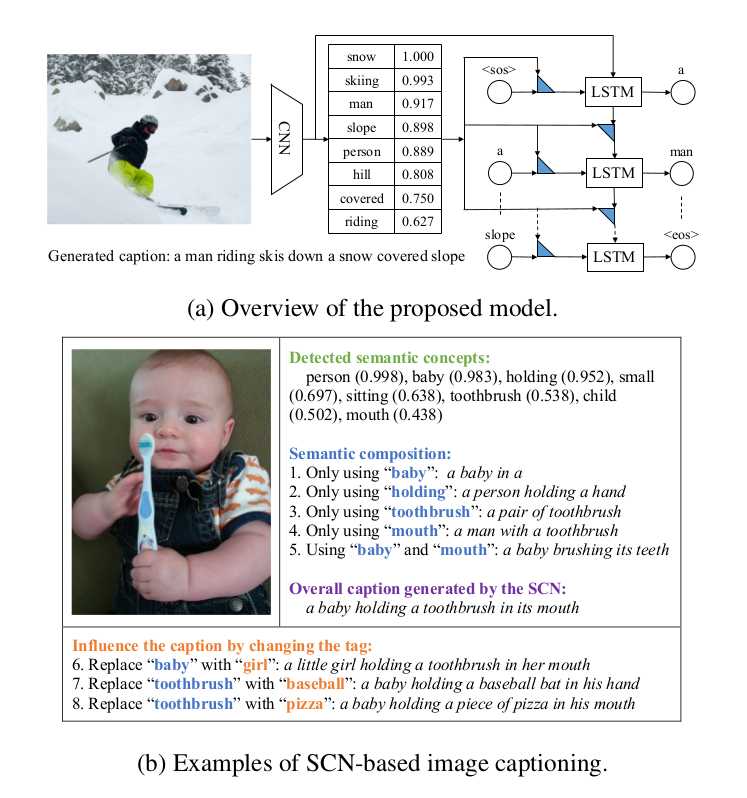
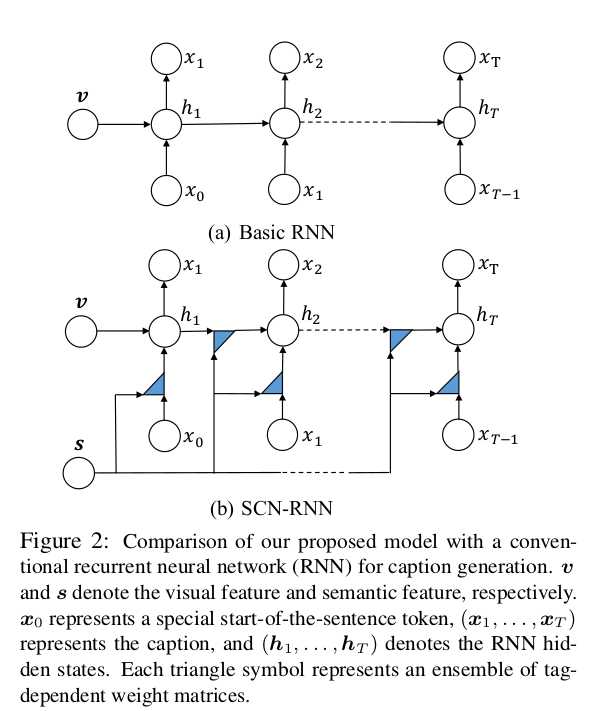
Semantic Compositional Networks for Visual Captioning(CVPR 2017)
Deep Reinforcement Learning-based Image Captioning with Embedding Reward (CVPR 2017)
A decision-making framework for image captioning.
A "policy network" and a "value network" to collaboratively generate captions.
Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering(CVPR 2018)
In the human visual system, attention can be focused volitionally by top-down signals determined by the current task(e.g.,looking for something), and automatically by bottom-up signals associated with unexpected, novel or salient stimuli.
top-down:attention mechanisms driven by non-visual or task-specific context; feature weights;
bottom-up:purely visual feed-forward attention mechanisms;based on Faster-RCNN proposes image regions (feature vector);



原文:https://www.cnblogs.com/czhwust/p/imagecaption.html