# 保存模型 model.save(file_path)
model_name = ‘{}/{}_{}_{}_v2.h5‘.format(params[‘model_dir‘],params[‘filters‘],params[‘pool_size_1‘],params[‘pool_size_2‘])
model.save(model_name)
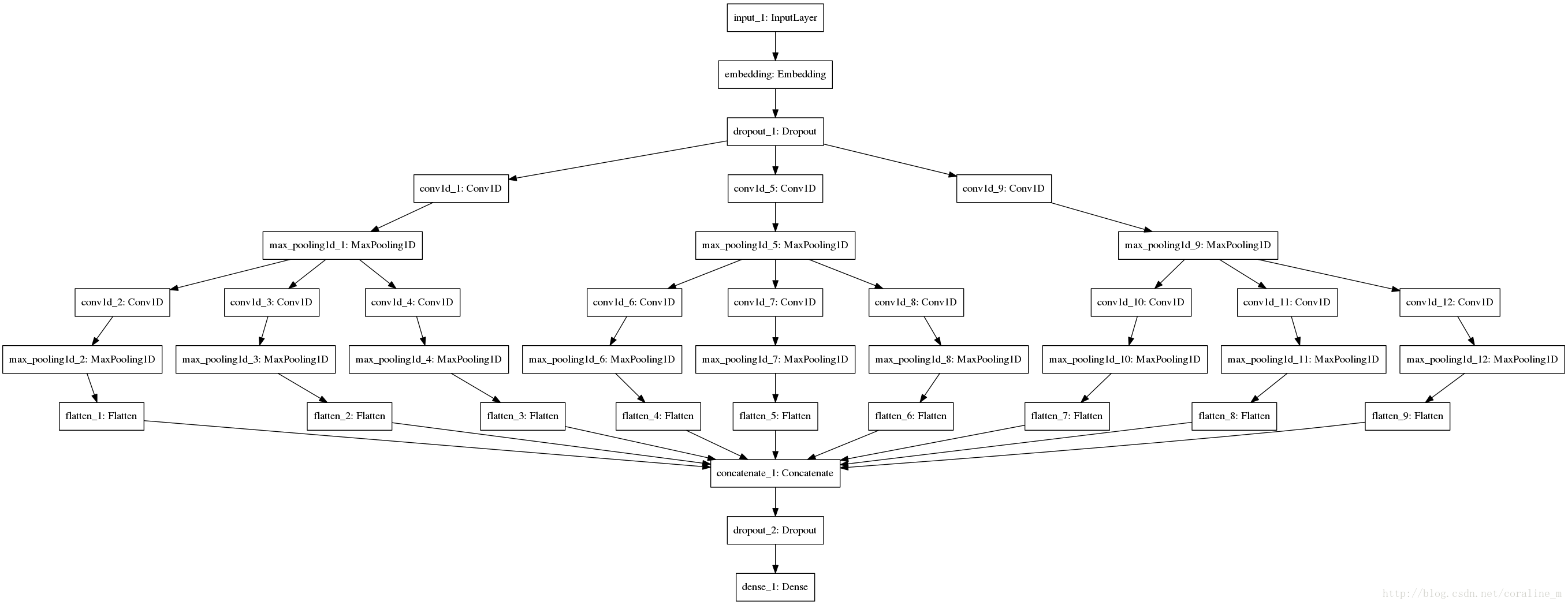
# 保存模型图
from keras.utils import plot_model
# 需要安装pip install pydot
model_plot = ‘{}/{}_{}_{}_v2.png‘.format(params[‘model_dir‘],params[‘filters‘],params[‘pool_size_1‘],params[‘pool_size_2‘])
plot_model(model, to_file=model_plot)
from keras.models import load_model model_path = ‘../docs/keras/100_2_3_v2.h5‘ model = load_model(model_path)
优势和弊端
优势一在于模型保存和加载就一行代码,写起来很方便。
优势二在于不仅保存了模型的结构和参数,也保存了训练配置等信息。以便于从上次训练中断的地方继续训练优化。
劣势就是占空间太大,我的模型用这种方式占了一个G。【红色部分就是上述模型采用第一种方式保存的文件】本地使用还好,如果是多人的模块需要集成,上传或者同步将会很耗时。

保存模型图部分和方式一相同。
import yaml import json # 保存模型结构到yaml文件或者json文件 yaml_string = model.to_yaml() open(‘../docs/keras/model_architecture.yaml‘, ‘w‘).write(yaml_string) # json_string = model.to_json() # open(‘../docs/keras/model_architecture.json‘, ‘w‘).write(json_string) # 保存模型参数到h5文件 model.save_weights(‘../docs/keras/model_weights.h5‘)
import yaml import json from keras.models import model_from_json from keras.models import model_from_yaml # 加载模型结构 model = model_from_yaml(open(‘../docs/keras/model_architecture.yaml‘).read()) # model = model_from_json(open(‘../docs/keras/model_architecture.json‘).read()) # 加载模型参数 model.load_weights(‘../docs/keras/model_weights.h5‘)

原文:https://www.cnblogs.com/Mjerry/p/9939561.html