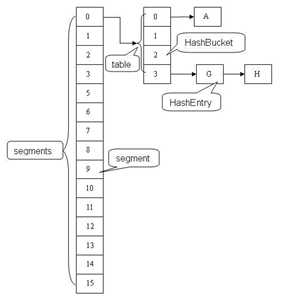
/** * The segments, each of which is a specialized hash table */ final Segment<K,V>[] segments;
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}

static final class Segment<K,V> extends ReentrantLock implements Serializable {
/**
* The number of elements in this segment‘s region.
*/
transient volatileint count;
/**
* Number of updates that alter the size of the table. This is
* used during bulk-read methods to make sure they see a
* consistent snapshot: If modCounts change during a traversal
* of segments computing size or checking containsValue, then
* we might have an inconsistent view of state so (usually)
* must retry.
*/
transient int modCount;
/**
* The table is rehashed when its size exceeds this threshold.
* (The value of this field is always <tt>(int)(capacity *
* loadFactor)</tt>.)
*/
transient int threshold;
/**
* The per-segment table.
*/
transient volatile HashEntry<K,V>[] table;
/**
* The load factor for the hash table. Even though this value
* is same for all segments, it is replicated to avoid needing
* links to outer object.
* @serial
*/
final float loadFactor;
}
public V remove(Object key) {
hash = hash(key.hashCode());
return segmentFor(hash).remove(key, hash, null);
}
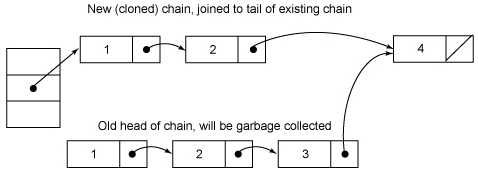
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
*for (HashEntry<K,V> p = first; p != e; p = p.next)
*newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}

V get(Object key, int hash) {
if (count != 0) { // read-volatile 当前桶的数据个数是否为0
HashEntry<K,V> e = getFirst(hash); 得到头节点
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
returnnull;
}
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
boolean containsKey(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key))
returntrue;
e = e.next;
}
}
returnfalse;
}
Java集合---ConcurrentHashMap原理分析
原文:https://www.cnblogs.com/liuyaofei/p/9989207.html