HBase从宏观上看只有HMaster、RegionServer和zookeeper三个组件。
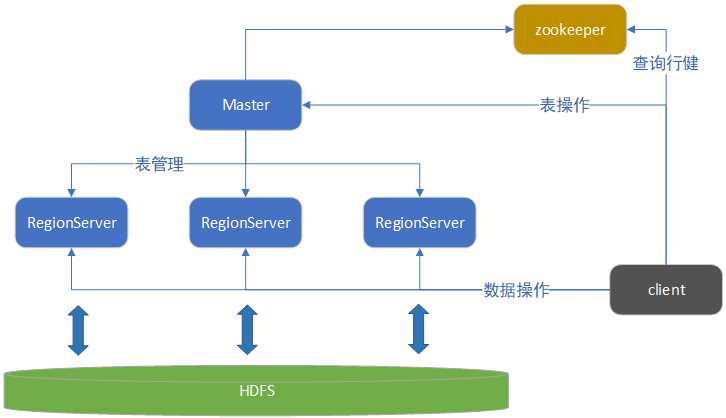
Master: 负责启动的时候分配Region到具体的RegionServer,执行各种管理操作,比如Region的分割合并。HBase的Master是不负责数据的读写的,所以它挂了集群照样可以运行并读写数据,但是无法新建删除表。
RegionServer:RegionServer上有一个或者多个Region。读写的数据就存储在Region上。
Region:表的一部分数据,HBase是个会自动分片的数据库。一个Region就相当于关系型数据库中的一个分区表中的分区。
zookeeper:HBase没有Master可以运行,但是没有zookeeper是无法运行的,在JavaAPI在读写HBase时,配置的就是zookeeper的地址,而不是HBase本身的地址。因为读取数据所需要的元数据表就存储在zookeeper上。
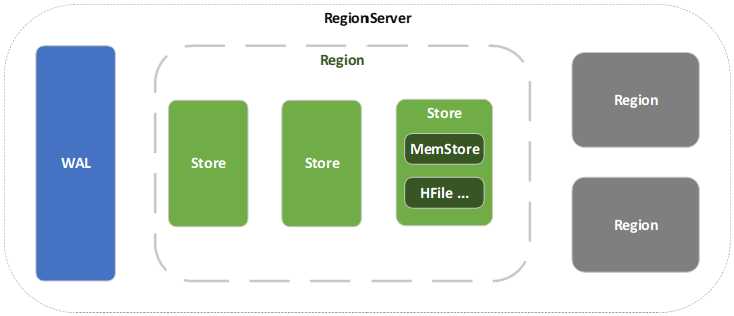
WAL,预写日志,WAL是Write-Ahead Log的缩写。当操作到达Region的时候,HBase会直接把操作写到WAL中,然后会将数据放到基于内存实现的Memstore,等数据到达一定量时才flush到HFile中,如果这个过程中服务宕机或者断电,那么数据就丢失了。WAL是一个保险机制,数据在写到Memstore之前就会写到WAL,这样WAL中的日志就是数据恢复的依据。WAL默认是开启的。一个好的软件的设计真的是连服务器的宕机都考虑进去了。
Memstore,为了让HBase中的读取效率提高,设计了Memstore,数据写入HDFS之前会先写入这里,然后数据量达到一个阀值就flush到HFile中。HBase是采用LSM树来保存数据,所以在Memstore中会先将数据整理为LSM树,然后再刷写到磁盘。
LSM树,即日志结构合并树(Log-Structured Merge-Tree)。其实它并不属于一个具体的数据结构,它更多是一种数据结构的设计思想。将数据分别放到内存和磁盘中,每次有数据更新不是必须将数据写入到磁盘中,而可以先将最新的数据驻留在内存中,等到积累到阀值后,再使用归并排序的方式将内存内的数据合并追加到磁盘队尾,因为所有待排序的树都是经过排序的,可以通过合并排序的方式快速合并到一起。
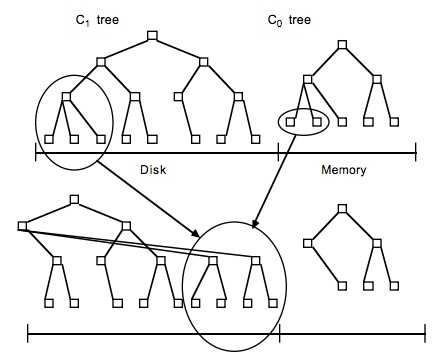
虽然新写入的数据会暂存Memstore中,但并不是读取数据的时候也是先读Memstore,再去读磁盘。
HFile , 是HBase数据真正的载体,创建所有的表、列等数据都放到HFile中。HFile也是StoreFile,有的地方也叫StoreFile。
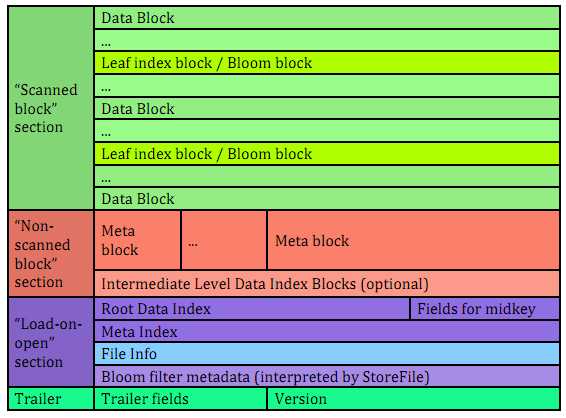
文件主要分为四个部分:Scanned block section,Non-scanned block section,Opening-time data section和Trailer。
Scanned block section:顾名思义,表示顺序扫描HFile时所有的数据块将会被读取,包括Leaf Index Block和Bloom Block以及DataBlock。(DataBlock是HBase中数据存储的最小单元。DataBlock中主要存储用户的KeyValue数据(KeyValue后面一般会跟一个timestamp)
Non-scanned block section:表示在HFile顺序扫描的时候数据不会被读取,主要包括Meta Block和Intermediate Level Data Index Blocks两部分。
Load-on-open-section:这部分数据在HBase的region server启动时,需要加载到内存中。包括FileInfo、Bloom filter block、data block index和meta block index。
Trailer:这部分主要记录了HFile的基本信息、各个部分的偏移值和寻址信息。
HFile会被切分为多个大小相等的block块,每个block的大小可以在创建表列簇的时候通过参数blocksize 进行指定,默认为64k,大号的Block有利于顺序Scan,小号Block利于随机查询,因而需要权衡。并且所有block块都拥有相同的数据结构。
原文:https://www.cnblogs.com/hello-daocaoren/p/9992554.html