论文:Dual Path Networks
论文链接:https://arxiv.org/abs/1707.01629
代码:https://github.com/cypw/DPNs
MXNet框架下可训练模型的DPN代码:https://github.com/miraclewkf/DPN
算法详解:
本篇博文要介绍的duall path networks(DPN)是颜水成老师新作,前段时间刚刚在arxiv上放出,对于图像分类的效果有一定提升。我们知道ResNet,ResNeXt,DenseNet等网络在图像分类领域的效果显而易见,而DPN可以说是融合了ResNeXt和DenseNet的核心思想,这里为什么不说是融合了ResNet和DenseNet,因为作者也用了group操作,而ResNeXt和ResNet的主要区别就在于group操作。如果你对ResNeXt不大了解,可以参考博客:ResNeXt算法详解,如果你对DenseNet不大了解,可以参考博客:DenseNet算法详解。
那么DPN到底有哪些优点呢?可以看以下两点:
1、关于模型复杂度,作者的原文是这么说的:The DPN-92 costs about 15% fewer parameters than ResNeXt-101 (32 4d), while the DPN-98 costs about 26% fewer parameters than ResNeXt-101 (64 4d).
2、关于计算复杂度,作者的原文是这么说的:DPN-92 consumes about 19% less FLOPs than ResNeXt-101(32 4d), and the DPN-98 consumes about 25% less FLOPs than ResNeXt-101(64 4d).
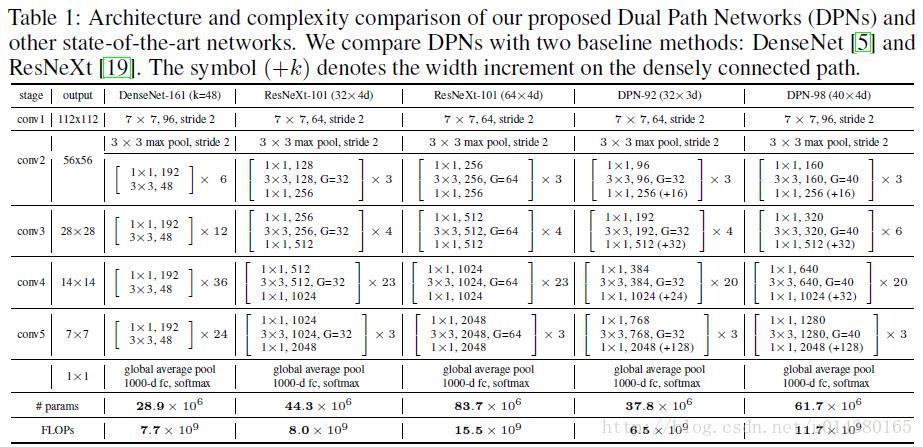
先放上网络结构Table1,有一个直观的印象。其实DPN和ResNeXt(ResNet)的结构很相似。最开始一个7*7的卷积层和max pooling层,然后是4个stage,每个stage包含几个sub-stage(后面会介绍),再接着是一个global average pooling和全连接层,最后是softmax层。重点在于stage里面的内容,也是DPN算法的核心。
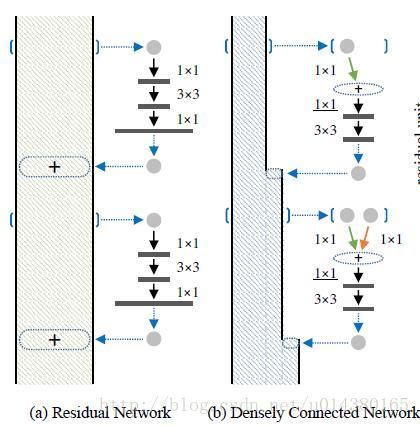
因为DPN算法简单讲就是将ResNeXt和DenseNet融合成一个网络,因此在介绍DPN的每个stage里面的结构之前,先简单过一下ResNet(ResNeXt和ResNet的子结构在宏观上是一样的)和DenseNet的核心内容。下图中的(a)是ResNet的某个stage中的一部分。(a)的左边竖着的大矩形框表示输入输出内容,对一个输入x,分两条线走,一条线还是x本身,另一条线是x经过1*1卷积,3*3卷积,1*1卷积(这三个卷积层的组合又称作bottleneck),然后把这两条线的输出做一个element-wise addition,也就是对应值相加,就是(a)中的加号,得到的结果又变成下一个同样模块的输入,几个这样的模块组合在一起就成了一个stage(比如Table1中的conv3)。(b)表示DenseNet的核心内容。(b)的左边竖着的多边形框表示输入输出内容,对输入x,只走一条线,那就是经过几层卷积后和x做一个通道的合并(cancat),得到的结果又成了下一个小模块的输入,这样每一个小模块的输入都在不断累加,举个例子:第二个小模块的输入包含第一个小模块的输出和第一个小模块的输入,以此类推。
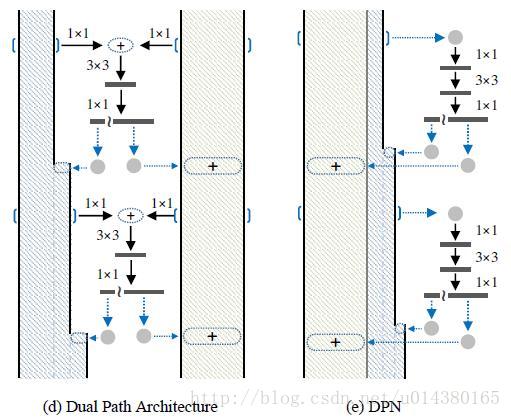
DPN是怎么做呢?简单讲就是将Residual Network 和 Densely Connected Network融合在一起。下图中的(d)和(e)是一个意思,所以就按(e)来讲吧。(e)中竖着的矩形框和多边形框的含义和前面一样。具体在代码中,对于一个输入x(分两种情况:一种是如果x是整个网络第一个卷积层的输出或者某个stage的输出,会对x做一个卷积,然后做slice,也就是将输出按照channel分成两部分:data_o1和data_o2,可以理解为(e)中竖着的矩形框和多边形框;另一种是在stage内部的某个sub-stage的输出,输出本身就包含两部分:data_o1和data_o2),走两条线,一条线是保持data_o1和data_o2本身,和ResNet类似;另一条线是对x做1*1卷积,3*3卷积,1*1卷积,然后再做slice得到两部分c1和c2,最后c1和data_o1做相加(element-wise addition)得到sum,类似ResNet中的操作;c2和data_o2做通道合并(concat)得到dense(这样下一层就可以得到这一层的输出和这一层的输入),也就是最后返回两个值:sum和dense。以上这个过程就是DPN中 一个stage中的一个sub-stage。有两个细节,一个是3*3的卷积采用的是group操作,类似ResNeXt,另一个是在每个sub-stage的首尾都会对dense部分做一个通道的加宽操作。
作者在MXNet框架下实现了DPN算法,具体的symbol可以看:https://github.com/cypw/DPNs/tree/master/settings,介绍得非常详细也很容易读懂。
实验结果:
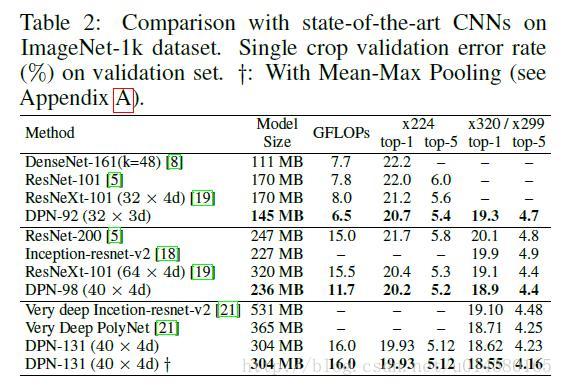
Table2是在ImageNet-1k数据集上和目前最好的几个算法的对比:ResNet,ResNeXt,DenseNet。可以看出在模型大小,GFLOP和准确率方面DPN网络都更胜一筹。不过在这个对比中好像DenseNet的表现不如DenseNet那篇论文介绍的那么喜人,可能是因为DenseNet的需要更多的训练技巧。
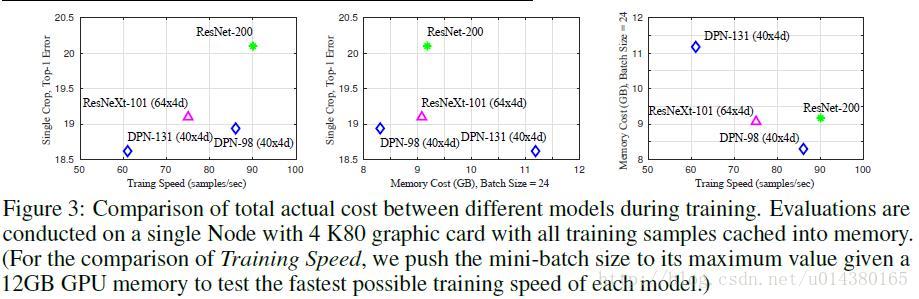
Figure3是关于训练速度和存储空间的对比。现在对于模型的改进,可能准确率方面的提升已经很难作为明显的创新点,因为幅度都不大,因此大部分还是在模型大小和计算复杂度上优化,同时只要准确率还能提高一点就算进步了。
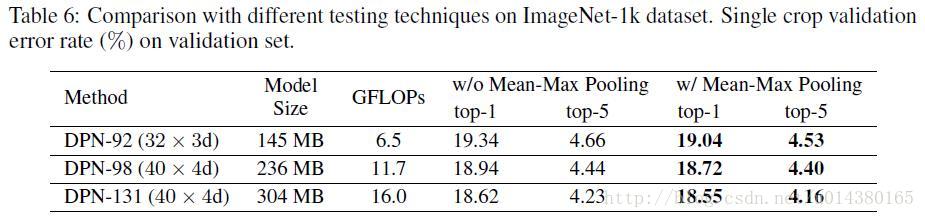
作者的最后提到一个如果在测试阶段,在网络结构后面加上mean-max pooling 层可以提高准确率,如下图:
更多实验结果可以看论文。
总结:
作者提出的DPN网络可以理解为在ResNeXt的基础上引入了DenseNet的核心内容,使得模型对特征的利用更加充分。原理方面并不难理解,而且在跑代码过程中也比较容易训练,同时文章中的实验也表明模型在分类和检测的数据集上都有不错的效果。
[Network Architecture]DPN(Dual Path Network)算法详解(转)
原文:https://www.cnblogs.com/kk17/p/9998406.html