前面两周对系统调用机制进行了仔细的研究,本周将学习用来创建进程的系统调用fork。首先,必须先理解进程如何描述(pcb),其次再理解进程的创建过程和机制。此处要主要掌握进程描述符的内容、状态转换和双向链表管理
1.OS内核实现OS的三大功能对应了OS原理课程中最重要的3个抽象概念:
双向链表中的第一个节点为init_task,这是第一个进程(0号进程)的进程描述符结构体变量,它的初始化是通过硬编码方式(宏定义,#difine INIT_TASK(tsk))固定下来的 。除此之外的其他所有进程的初始化都是通过do_fork复制父进程的方式初始化的。
1.内存管理的相关代码为struct mm_struct *mm,*active_mm;,mm和active_mm是和进程地址空间、内存管理相关的数据结构指针。
2.为了抓住Linux内核中最核心的工作机制,我们不仔细分析物理地址和逻辑地址转换、MMU的具体工作,将进程的地址空间简化为每个进程都有独立的逻辑地址空间。
3.32位x86体系结构拥有4GB的进程地址空间,用户态只能访问0x00000000~0xbfffffff的地址空间,0xc00000000以上的地址空间只能在内核态下访问。内核态可以访问全部4GB的地址空间。(详细可见《庖丁解牛》P68)
在多达400+行的结构体struct task_struct代码中,进程描述符通过struct list_head tasks双向链表管理所有进程(list_head即是双向链表)
当前进程的兄弟进程:通过struct list_head sibling记录(是双向链表)
这样设计数据结构是为了方便在内核代码中快速获取当前进程的父子、兄弟进程的信息
ip:保存进程上下文中的EIP寄存器状态
此外进程描述符中还有和文件系统相关的数据结构、打开的文件描述符,有和信号处理相关以及和pipe管道相关的数据结构等。进程描述符可以在我们要研究Linux内核的某一部分的特定内容时起到提纲挈领的作用,诶我们进一步深入研究Linux内核提供了基础。
1.用户态创建进程的方法
2.fork系统调用概览
3.进程创建的主要过程
4.内核堆栈关键信息的初始化
5.通过实验跟踪分析进程创建的过程
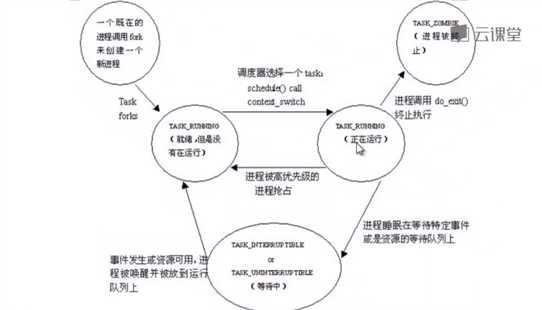
fork系统调用过程可以用一个图来在整体上展示系统调用的嵌套
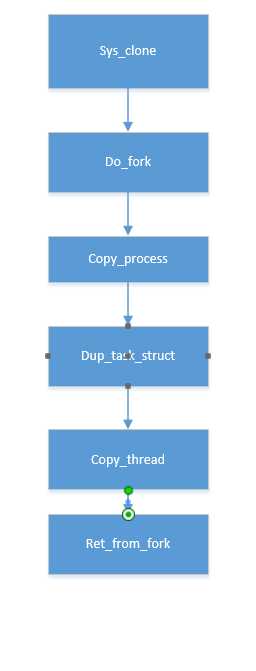
1.实验任务
struct task_struct {
volatile long state; //进程状态/* -1 unrunnable, 0 runnable, >0 stopped */
void *stack; // 指定进程内核堆栈
pid_t pid; //进程标识符
unsigned int rt_priority; //实时优先级
unsigned int policy; //调度策略
struct files_struct *files; //系统打开文件
…
}使用gdb跟踪分析一个fork系统调用内核处理函数sys_clone ,验证您对Linux系统创建一个新进程的理解,推荐在实验楼Linux虚拟机环境下完成实验。 特别关注新进程是从哪里开始执行的?为什么从那里能顺利执行下去?即执行起点与内核堆栈如何保证一致。
2018-2019-1 20189204《Linux内核原理与分析》第七周作业
原文:https://www.cnblogs.com/bowendky/p/9983166.html