import requests import json url="https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1543656520026" def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status() #如果状态不是200,引发异常 r.encoding=‘utf-8‘ #无论原来什么编码都改成utf-8 datas=json.loads(r.text)[‘data‘] except: print(‘error‘) else: result=" " for item in datas: result += str(item[‘StudentNo‘])+‘,‘+item[‘RealName‘]+‘,‘+item[‘DateAdded‘].replace(‘T‘,‘ ‘)+‘,‘+item[‘Title‘]+‘,‘+item[‘Url‘]+‘\n‘ f=open(‘D:\hwlist.csv‘,‘w‘) f.write(result) f.close()
结果
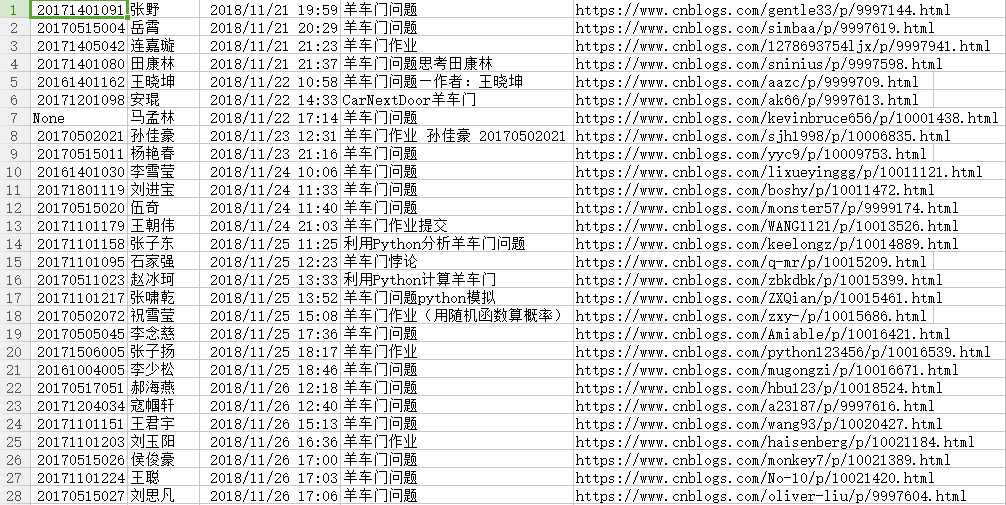
原文:https://www.cnblogs.com/wendy-onlooker/p/10050812.html