1、传统方法:
这种方式就是常用的TableInputFormat和TableOutputFormat来读写hbase;
用sc.newAPIHadoopRDD根据conf中配置好的scan来从Hbase的数据列族中读取包含(ImmutableBytesWritable, Result)的RDD,随后取出rowkey和value的键值对。
2、最简单的phoenix sql读取。和jdbc读取mysql一样:
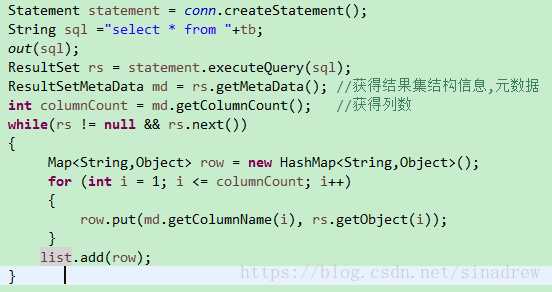
读出的数据都是存入List中,可以直接使用,也可以把List转成spark的RDD或者Dataset.
3.把hbase转成RDD,代码有点多,分为两部分,都是一个方法内的代码:先配置hbase
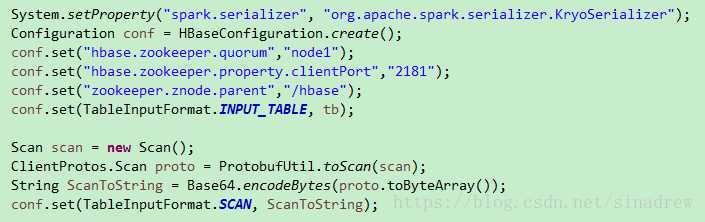
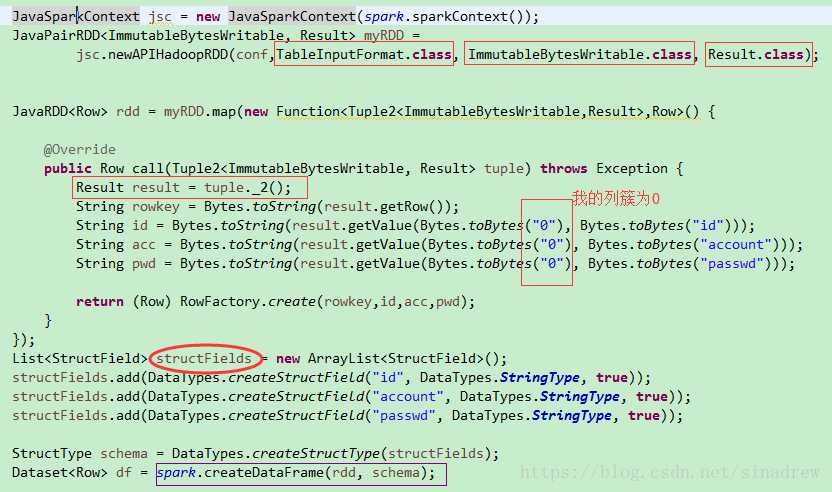
这种的话也很快,但是要求对hbase的逻辑结构比较清除才能正确的转换过来,当然还可以改进成可以动态配置schema的形式,比如说通过phoenix直接读取整个schema或者将schema写成这种形式:String str="cf1:name:sex|cf2:adress:age",然后自己再组装schema。
---------------------
作者:sinadrew
来源:CSDN
原文:https://blog.csdn.net/sinadrew/article/details/80172984
版权声明:本文为博主原创文章,转载请附上博文链接!
原文:https://www.cnblogs.com/yanxun1/p/10054577.html