import requests
import json
def getHTMLText(url):
try:
r =requests.get(url,timeout=30)
r.raise_for_status()
r.encoding= ‘utf-8‘
return json.loads(r.text)
except:
print("错误")
url="https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1543742054481"
getHTMLText(url)
csv=‘‘
for item in json_data[‘data‘]:
csv +=str(item[‘StudentNo‘])+‘\t‘+‘,‘+item[‘RealName‘]+‘,‘+item[‘Title‘]+‘,‘+item[‘DateAdded‘].replace(‘T‘,‘ ‘)+‘\t‘+‘,‘+item[‘Url‘]+‘\n‘
with open(‘hwlist.csv‘,‘w‘) as f:
f.write(result)
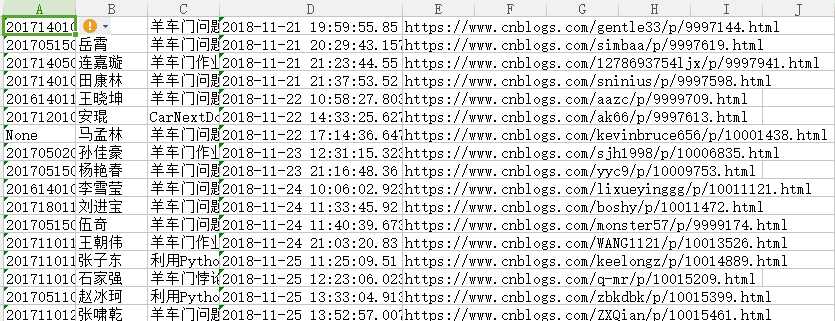
生成的文件内容如下:
import os
import requests
import json
folder = os.path.exists("hwFolder")
if not folder:
os.mkdir("hwFolder")
else:
os.chdir("hwFolder")
for item in json_data[‘data‘]:
os.mkdir(str(item[‘StudentNo‘]))
os.chdir(str(item[‘StudentNo‘]))
try:
rr=requests.get(item[‘Url‘],timeout=30)
rr.raise_for_status()
rr.encoding= ‘utf-8‘
except:
print("错误")
with open("str(item[‘StudentNo‘])"+".html","w+b") as fp:
fp.write(rr.content)
os.chdir(os.path.pardir)
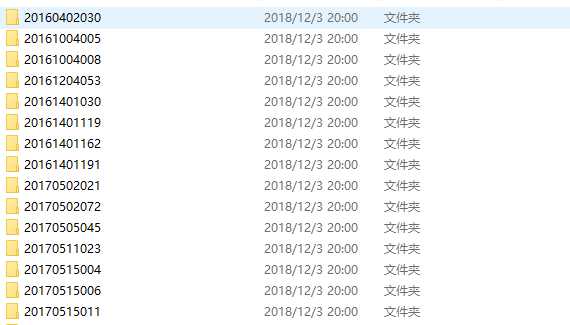
部分结果如下:
https://www.cnblogs.com/lauhp/p/7999662.html
https://www.cnblogs.com/sangern/p/7766394.html
以及各位大佬。。。
原文:https://www.cnblogs.com/lixueyinggg/p/10060723.html