?. 小数据池
在说小数据池之前. 我们先看一个概念念.
什么是代码块: 根据提示我们从官?方?文档找到了这样的说法: A Python program is constructed from code blocks. A block is a piece of Python program text that is executed as a unit. The following are blocks: a module, a function body, and a class definition. Each command typed interactively is a block. A script file (a file given as standard input to the interpreter or specified as a command line argument to the interpreter) is a code block. A script command (a command specified on the interpreter command line with the ‘-c‘ option) is a code block. The string argument passed to the built-in functions eval() and exec() is a code block. A code block is executed in an execution frame. A frame contains some administrative information (used for debugging) and determines where and how execution continues after the code block’s execution has completed.
粗略的翻译:
python程序是由代码块构成的. ?一个代码块的?文本作为python程序执?行行的单元. 代码块: ?个模块, 一个函数, 一个类, 甚?至每?个command命令都是一个代码块. 一个?文件也是一 个代码块, eval()和exec()执?行行的时候也是一个代码块
二. 接下来我们来看?下小数据池
is和==的区别
1. id()
通过id()我们可以查看到?一个变量量表?示的值在内存中的地址.
s = ‘alex‘ print(id(s)) # 4326667072
例如:
id()函数可以帮我们查看一个变量的内存地址
a = 10
b = 30
print(id(a)) # 1515545088
print(id(b)) # 1515545728
使用频率最高的数据类型: 字符串,为了能够快速的创建字符串.
节省内存. 把相同的规律的字符串进行缓存,当下次创建的时候就不在创建了
把字符串的缓存-> 小数据池 -> String iterning -> 常量池 -> 字符串缓存
把字符串的缓存-> 小数据池 -> String iterning -> 常量池 -> 字符串缓存 同样的意思!!!
在创建字符串之前. 先去小数据池对比. 是否已经存在了该字符串.如果存在了.
就不创建新的了. 直接拿原来存在的数据, 省略掉反复重复创建字符串的过程. 节约内存
什么数据会被缓存
数字, 字符串, 布尔值 => 都是不可变的数据类型
1. 数字
a = 1000
b = 1000
print(id(a), id(b)) # 165830000 165830000
如果在py文件中写的字符串. 几乎都是缓存的
在黑窗口里的写的几乎都不会缓存
不同的解释器. 缓存的机制也不一样
优点: 可以帮我们快速的创建对象.节省内存.
缺点: 缓存如果过大. 响应速度会比较慢
不要纠结.
2. is和==
判断左右两端的值是否相等. 是不是?一致.
is 判断左右两端内容的内存地址是否?一致. 如果返回True, 那可以确定这两个变量量使 ?用的是同?一个对象
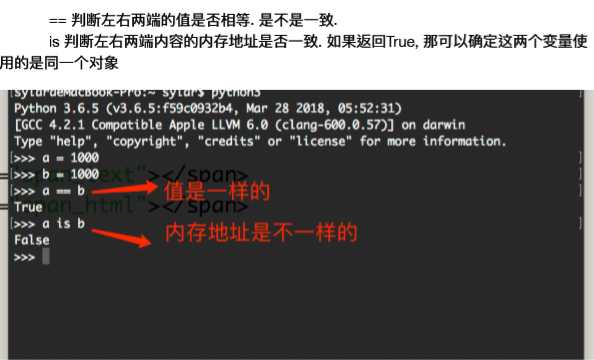
我们可以这样认为. 如果内存地址相同. 那么值?一定是相等的. 如果值相等. 则不?一定是同?一 个对象
== 比较的是数据, 外貌
is 比较的是内存地址, 比较身份证号
lst1 = [1,2,3]
lst2 = [1,2,3]
# 列表没有小数据池
print(id(lst1), id(lst2)) # 166167560 166126408
print(lst1 == lst2) # True
print(lst1 is lst2) # False
s1 = "我叫周润发"
s2 = "我叫周润发"
print(s1 == s2)
print(s1 is s2) # 小数据池
tu1 = ("周一", "周二")
tu2 = ("周一", "周二")
print(tu1 is tu2) # 地址不相等 False
print(tu1 == tu2) # 内容相等 True
== 比较的是内容
is 比较内存地址


在python中对-5到256之间的整数会被驻留留在内存中. 将?一定规则的字符串串缓存. 在使?用 的时候, 内存中只会创建?一个该数据的对象. 保存在?小数据池中. 当使?用的时候直接从?小数据 池中获取对象的内存引?用. ?而不需要创建?一个新的数据. 这样会节省更更多的内存区域.
优点: 能够提?高?一些字符串串, 整数的处理理速度. 省略略的创建对象的过程.
缺点: 在‘池‘中创建或者插入新的内容会花费更更多的时间.
对于数字: -5~256是会被加到?小数据池中的. 每次使?用都是同?一个对象. 对于字符串串:
1. 如果字符串串的?长度是0或者1, 都会默认进?行行缓存
2. 字符串串?长度?大于1, 但是字符串串中只包含字?母, 数字, 下划线时才会缓存
3. ?用乘法的到的字符串串. ①. 乘数为1, 仅包含数字, 字?母, 下划线时会被缓存. 如果 包含其他字符, ?而?长度<=1 也会被驻存, ②. 乘数?大于1 . 仅包含数字, 字?母, 下划 线这个时候会被缓存. 但字符串串?长度不能?大于20 4. 指定驻留留. 我们可以通过sys模块中的intern()函数来指定要驻留留的内容.
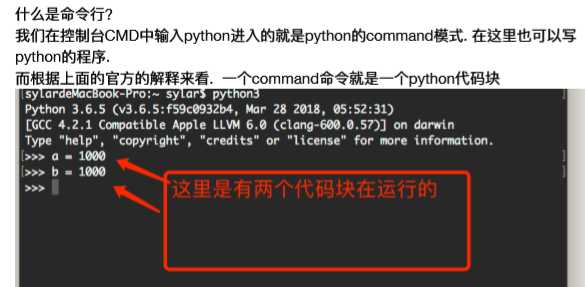
OK. 到?目前为?止. 我们已经了了解了了python的?小数据池的?一些基本情况了了. 但是!!!! 还有最后?一 个问题. ?小数据池和最开始的代码块有什什么关系呢? 同样的?一段代码在命令?行行窗?口和在py?文件中. 出现的效果是完全不?一样的.

在代码块内的缓存机制是不?一样的. 在执?行行同?一个代码块的初始化对象的命令时, 会检 查是否其值是否已经存在, 如果存在, 会将其重?用. 换句句话说: 执?行行同?一个代码块时, 遇到初始 化对象的命令时,他会将初始化的这个变量量与值存储在?一个字典中, 在遇到新的变量量时, 会先 在字典中查询记录, 如果有同样的记录那么它会重复使?用这个字典中的之前的这个值. 所以在 你给出的例例?子中, ?文件执?行行时(同?一个代码块) 会把a, b两个变量量指向同?一个对象.
如果是不同的代码块, 他就会看这个两个变量量是否是满?足?小数据池的数据, 如果是满?足 ?小数据池的数据则会指向同?一个地址. 所以: a, b的赋值语句句分别被当作两个代码块执?, 但 是他们不满足?数据池的数据所以会得到两个不同的对象, 因?而is判断返回False.
三. 编码的补充
1. python2中默认使?用的是ASCII码. 所以不?支持中?文. 如果需要在Python2中更更改编码. 需要在?文件的开始编写:
# -*- encoding:utf-8 -*
2. python3中: 内存中使?用的是unicode码. 编码回顾:
1. ASCII : 最早的编码. ?里里?面有英?文?大写字?母, ?小写字?母, 数字, ?一些特殊字符.
没有中?文, 8个01代码, 8个bit, 1个byte
2. GBK: 中?文国标码, ?里里?面包含了了ASCII编码和中?文常?用编码.
16个bit, 2个byte
3. UNICODE: 万国码, ?里里?面包含了了全世界所有国家?文字的编码.
32个bit, 4个byte, 包含了了 ASCII
4. UTF-8: 可变?长度的万国码. 是unicode的?一种实现. 最?小字符占8位
1.英?文: 8bit 1byte 2.欧洲?文字:16bit 2byte 3.中?文:24bit 3byte
综上, 除了了ASCII码以外, 其他信息不能直接转换. 在python3的内存中. 在程序运?行行阶段. 使?用的是unicode编码. 因为unicode是万国码. 什什么内 容都可以进?行行显?示. 那么在数据传输和存储的时候由于unicode比较浪费空间和资源. 需要把 unicode转存成UTF-8或者GBK进?行行存储. 怎么转换呢. 在python中可以把?文字信息进?行行编码. 编码之后的内容就可以进?行行传输了了. 编码之后的数据是bytes类型的数据.其实啊. 还是原来的 数据只是经过编码之后表现形式发?生了了改变?而已.
bytes的表现形式:
1. 英?文 b‘alex‘ 英?文的表现形式和字符串串没什什么两样
2. 中?文 b‘\xe4\xb8\xad‘ 这是?一个汉字的UTF-8的bytes表现形式


记住: 英?文编码之后的结果和源字符串串?一致. 中?文编码之后的结果根据编码的不同. 编码结果 也不同. 我们能看到. ?一个中?文的UTF-8编码是3个字节. ?一个GBK的中?文编码是2个字节. 编码之后的类型就是bytes类型. 在?网络传输和存储的时候我们python是保存和存储的bytes 类型. 那么在对?方接收的时候. 也是接收的bytes类型的数据. 我们可以使?用decode()来进?行行解 码操作. 把bytes类型的数据还原回我们熟悉的字符串:
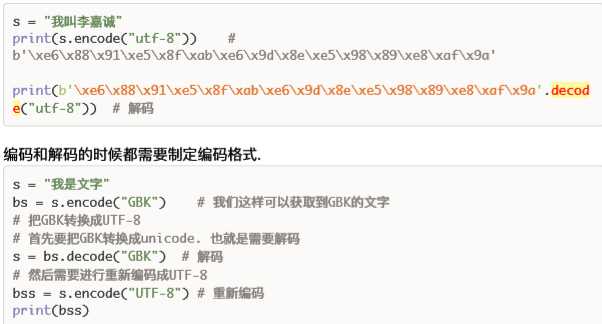
s = "我今天非常的困" # 21个utf-8
bs = s.encode("gbk") # 把字符串转化成utf-8格式bytes
# bytes不是给人看的. 给机器用的
# 14个字节 gbk
# b‘\xce\xd2\xbd\xf1\xcc\xec\xb7\xc7\xb3\xa3\xb5\xc4\xc0\xa7‘
# 21个字节 utf-8
# b‘\xe6\x88\x91\xe4\xbb\x8a\xe5\xa4\xa9\xe9\x9d\x9e\xe5\xb8\xb8\xe7\x9a\x84\xe5\x9b\xb0‘
print(bs)
utf-8和gbk是不能直接转换的, 必须使用unicode来转换
bs = b‘\xe6\x88\x91\xe4\xbb\x8a\xe5\xa4\xa9\xe9\x9d\x9e\xe5\xb8\xb8\xe7\x9a\x84\xe5\x9b\xb0‘
# 把字节转化回字符串
s = bs.decode("utf-8")
print(s)
b‘\xe6\x88\x91\xe4\xbb\x8a\xe5\xa4\xa9\xe9\x9d\x9e\xe5\xb8\xb8\xe7\x9a\x84\xe5\x9b\xb0‘
把这个bytes转化成gbk的bytes
bs = b‘\xe6\x88\x91\xe4\xbb\x8a\xe5\xa4\xa9\xe9\x9d\x9e\xe5\xb8\xb8\xe7\x9a\x84\xe5\x9b\xb0‘
# 解码
s = bs.decode("utf-8")
print(s)
# 编码
bss = s.encode("gbk")
print(bss)
关于bytes, 非ascii中的内容. 展示的时候都是\x.. 如果是ascii中的内容. 原样输出
name = "alex昨天吃多了"
bs = name.encode("gbk") # b‘alex\xd7\xf2\xcc\xec\xb3\xd4\xb6\xe0\xc1\xcb‘
print(bs)
bss = name.encode("utf-8") # b‘alex\xe6\x98\xa8\xe5\xa4\xa9\xe5\x90\x83\xe5\xa4\x9a\xe4\xba\x86‘
print(bss)
小数据池 (常量池 -> 字符串缓存) is和==的区别 重新看编码 以及编码之间相互转化
原文:https://www.cnblogs.com/H1050676808/p/10061352.html