使用Solr实现电商网站中商品信息搜索功能,可以根据关键字、分类、价格搜索商品信息,也可以根据价格进行排序。
在一些大型门户网站、电子商务网站等都需要站内搜索功能,使用传统的数据库查询方式实现搜索无法满足一些高级的搜索需求,比如:搜索速度要快、搜索结果按相关度排序、搜索内容格式不固定等,这里就需要使用全文检索技术实现搜索功能。
使用Lucene实现:单独使用Lucene实现站内搜索需要开发的工作量较大,主要表现在:索引维护、索引性能优化、搜索性能优化等,因此不建议采用。
使用solr实现:基于Solr实现站内搜索扩展性较好并且可以减少程序员的工作量,因为Solr提供了较为完备的搜索引擎解决方案,因此在门户、论坛等系统中常用此方案。
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
Lucene是一个开放源代码的全文检索引擎工具包,它不是一个完整的全文检索引擎,Lucene提供了完整的查询引擎和索引引擎,目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者以Lucene为基础构建全文检索引擎。
Solr的目标是打造一款企业级的搜索引擎系统,它是一个搜索引擎服务,可以独立运行,通过Solr可以非常快速的构建企业的搜索引擎,通过Solr也可以高效的完成站内搜索功能。
Solr官方网站:http://lucene.apache.org/solr/
将solr-4.10.3.zip解压:
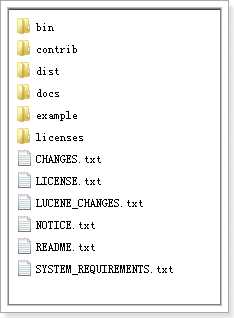
bin:solr的运行脚本
contrib:solr的一些贡献软件/插件,用于增强solr的功能。
dist:该目录包含build过程中产生的war和jar文件,以及相关的依赖文件。
docs:solr的API文档
example:solr工程的例子目录:
example/multicore:该目录包含了在Solr的multicore中设置的多个Core目录。
example/webapps:该目录中包括一个solr.war,该war可作为solr的运行实例工程。
solr 需要运行在一个Servlet容器中,Solr4.10.3要求jdk使用1.7以上,Solr默认提供Jetty(java写的Servlet容器),本教程使用Tocmat作为Servlet容器。
创建一个SolrHome目录,SolrHome是Solr运行的主目录,目录中包括了运行Solr实例所有的配置文件和数据文件,Solr实例就是SolrCore,一个SolrHome可以包括多个SolrCore(Solr实例),每个SolrCore提供单独的搜索和索引服务。
example\solr是一个solr home目录结构,如下:

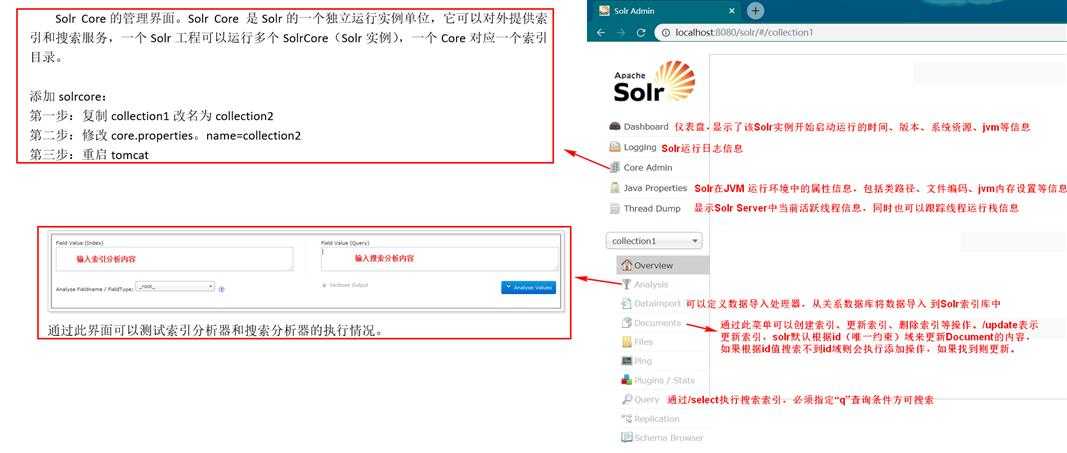
上图中“collection1”是一个SolrCore(Solr实例)目录 ,目录内容如下所示:

说明:
第一步:把\solr-4.10.3\dist\solr-4.10.3.war复制到tomcat 的webapp目录下,改名为solr.war。
第二步:solr.war解压。使用压缩工具解压或者启动tomcat自动解压。解压之后删除solr.war
第三步:把\solr-4.10.3\example\lib\ext目录下的所有的jar包添加到solr工程中
第四步:配置solrHome和solrCore
1)创建一个solrhome(存放solr所有配置文件的一个文件夹)。\solr-4.10.3\example\solr目录就是一个标准的solrhome。
2)把\solr-4.10.3\example\solr文件夹复制到D:\temp路径下,改名为solrhome,改名不是必须的,是为了便于理解。
3)在solrhome下有一个文件夹叫做collection1这就是一个solrcore。就是一个solr的实例。一个solrcore相当于mysql中一个数据库。Solrcore之间是相互隔离。
<!-- solr服务依赖的扩展包,默认的路径是collection1\lib文件夹,如果没有就创建一个 --> <lib dir="${solr.install.dir:../../..}/contrib/extraction/lib" regex=".*\.jar" /> <lib dir="${solr.install.dir:../../..}/dist/" regex="solr-cell-\d.*\.jar" /> <lib dir="${solr.install.dir:../../..}/contrib/clustering/lib/" regex=".*\.jar" /> <lib dir="${solr.install.dir:../../..}/dist/" regex="solr-clustering-\d.*\.jar" /> <lib dir="${solr.install.dir:../../..}/contrib/langid/lib/" regex=".*\.jar" /> <lib dir="${solr.install.dir:../../..}/dist/" regex="solr-langid-\d.*\.jar" /> <!-- 配置了索引库的存放路径。默认路径是collection1\data文件夹,如果没有data文件夹,会自动创建。--> <dataDir>${solr.data.dir:}</dataDir> <!-- name="/select":查询时使用的URL --> <requestHandler name="/select" class="solr.SearchHandler"> <lst name="defaults"> <str name="echoParams">explicit</str> <int name="rows">10</int> <str name="df">text</str> </lst> </requestHandler> <!-- name="/update":维护索引时使用的URL --> <requestHandler name="/update" class="solr.UpdateRequestHandler"> <!-- See below for information on defining updateRequestProcessorChains that can be used by name on each Update Request --> <!-- <lst name="defaults"> <str name="update.chain">dedupe</str> </lst> --> </requestHandler>
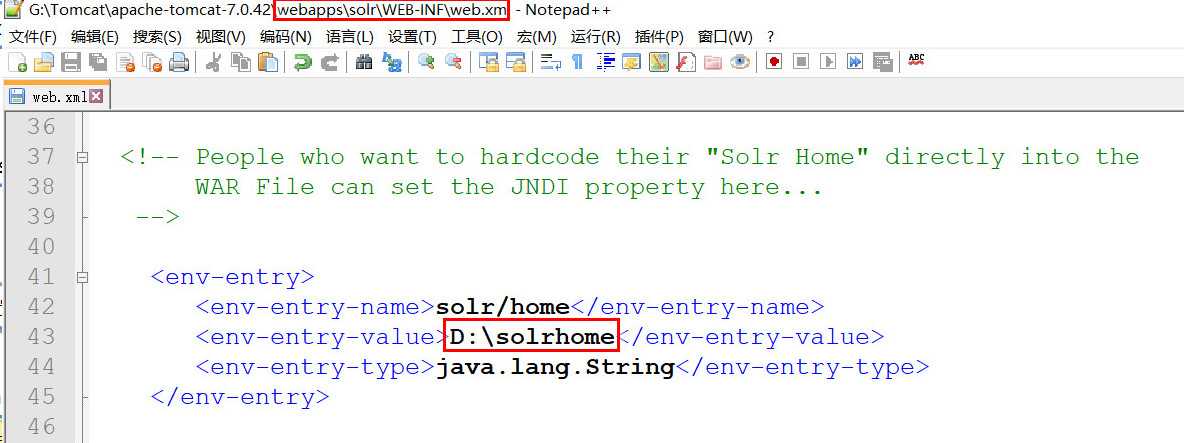
第五步:告诉solr服务器配置文件也就是solrHome的位置。修改solr项目的web.xml。
第六步:启动tomcat
第七步:访问http://localhost:8080/solr/,进入solr后台管理
schema.xml,在SolrCore的conf目录下,它是Solr数据表配置文件,它定义了加入索引的数据的数据类型的。主要包括FieldTypes、Fields和其他的一些缺省设置。
原文:https://www.cnblogs.com/yft-javaNotes/p/10105639.html