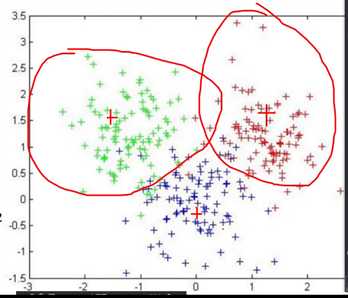
无监督-无标签
聚类,难点在于评估和调参。
kmeans最简单实用
K值:数据聚成多少类
质心:各个维度算平均数
相似度量:距离来算(欧式距离——直线距离,余弦距离)
样本之间的距离要先做标准化。(例如先都画到0-1之间)
K-mean聚类算法汇聚有用信息——学习笔记
原文:https://www.cnblogs.com/wxl845235800/p/10110927.html