引自:《手把手教你写网络爬虫》
通过 F12, Ctrl+Shift+C 快捷键从网页中直接抓取数据


代码如下:
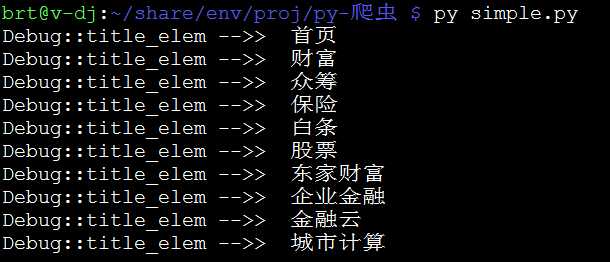
from urllib.request import urlopen from bs4 import BeautifulSoup html = urlopen("http://jr.jd.com") html_content = html.read() html.close() # 关闭url # 利用bs4解析html文本 bsoup = BeautifulSoup(html_content, "html.parser") # 解析全部class="nav-item-primary"的<a>标签 bs_elem_set = bsoup.find_all("a", "nav-item-primary") # <class ‘bs4.element.ResultSet‘> for elem_tag in bs_elem_set: # print(type(elem_tag)) # <class ‘bs4.element.Tag‘> print("Debug::title_elem -->> ", elem_tag.get_text())
测试结果:
案例:我们想从网易歌单 https://music.163.com/#/discover/playlist 中查询播放次数超过500万的全部歌单,查找关键字
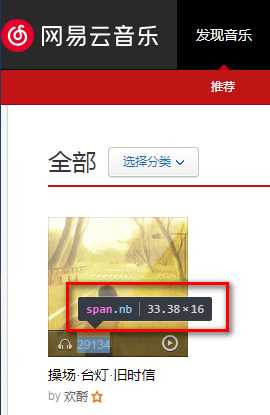
但事实上,通过 <span class="nb">29135</span> 我们什么也没有提取到……

从网页源码中我们可以知道,该网页通过javascript动态更新数据,我们得到的 nb=29135 数据行在 urlopen() 时尚未被js代码更新……
用Python 解决这个问题只有两种途径:
通过 Selenium 运行Js脚本,模拟浏览器载入动态网页。代码如下:
from selenium import webdriver browser = webdriver.PhantomJS() # deprecated... replace by webdriver.Chrome() or Firefox() browser.get("https://music.163.com/#/discover/playlist") browser.switch_to.frame("contentFrame") list_elems = browser.find_element_by_id("m-pl-container") .find_elements_by_tag_name("li") for elem in list_elems: # print(type(elem)) # <class ‘selenium.webdriver.remote.webelement.WebElement‘> str_nb = elem.find_element_by_class_name("nb").text print(str_nb) # I don‘t care the name, but just print the <nb> browser.close()
首先需要 pip3 install selenium 模块;加载动态网页用的是 Headless 的 PhantomJS 浏览器,需要单独安装:choco install PhantomJS。
ps:最新版本的 selenium 弃用了 PhantomJS,呃...不过忽略那个报警,我们这里还是可以继续执行的。
PhantomJS
原文:https://www.cnblogs.com/brt3/p/10122951.html