FASTTEXT(Facebook开源技术)
二分类任务,监督学习。
自然语言
NLP自然语言处理
语料Corpus:好评和差评
分词Words Segmentation:基于HMM构建dict tree
one-hot独热编码
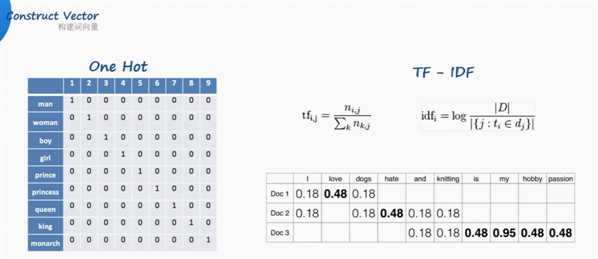
但是汉语中词太多了,独热编码的词向量随着词库中词汇的增长,会变得非常大。
而且one hot没法判断顺序
Google开山之作:TF-IDF(term frequency–inverse document frequency)
解决了频率和特殊性的关系。TF即词频(Term Frequency),IDF即逆向文档频率(Inverse Document Frequency)。
TF(词频)就是某个词在文章中出现的次数,此文章为需要分析的文本。为了统一标准,有如下两种计算方法:
(1)TF(词频) = 某个词在文章中出现的次数 / 该篇文章的总次数;
(2)TF 词频 = 某个词在文章中出现的次数 / 该篇文章出现最多的单词的次数;
IDF(逆向文档频率)为该词的常见程度,需要构建一个语料库来模拟语言的使用环境。
IDF 逆向文档频率 =log (语料库的文档总数 / (包含该词的文档总数+1));
如果一个词越常见,那么其分母就越大,IDF值就越小。
但还是有词向量长度的问题。
将独热编码当作输入,经过神经网络,判断one hot输出的是什么词
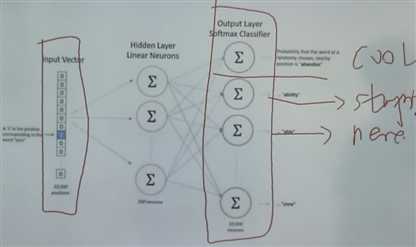
但是并没有关心输出的词是什么。隐藏层,100个隐藏神经元,100个权重。
而是将神经网络过程中的该层的权重作为了词向量。vector。
原文:https://www.cnblogs.com/wxl845235800/p/10158893.html