转载原文:https://www.cnblogs.com/chenmc/p/9516100.html
该作者本系列文章,写的很详尽
=================================================================================
在创建标准化索引的时候,我们传入的请求体如下:

{
"settings":{
"number_of_shards":5,
"number_of_replicas":1
},
"mappings":{
"novel":{
"properties":{
"id":{
"type":"integer"
},
"book_name":{
"type":"text"
},
"author":{
"type":"keyword"
},
"brief_introduction":{
"type":"text"
},
"publish_date":{
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss || yyyy-MM-dd"
},
"word_count":{
"type":"integer"
}
}
}
}
}
首先,ElasticSearch的对象模型如下:
所以,上面的请求体我们就可以这样标记:
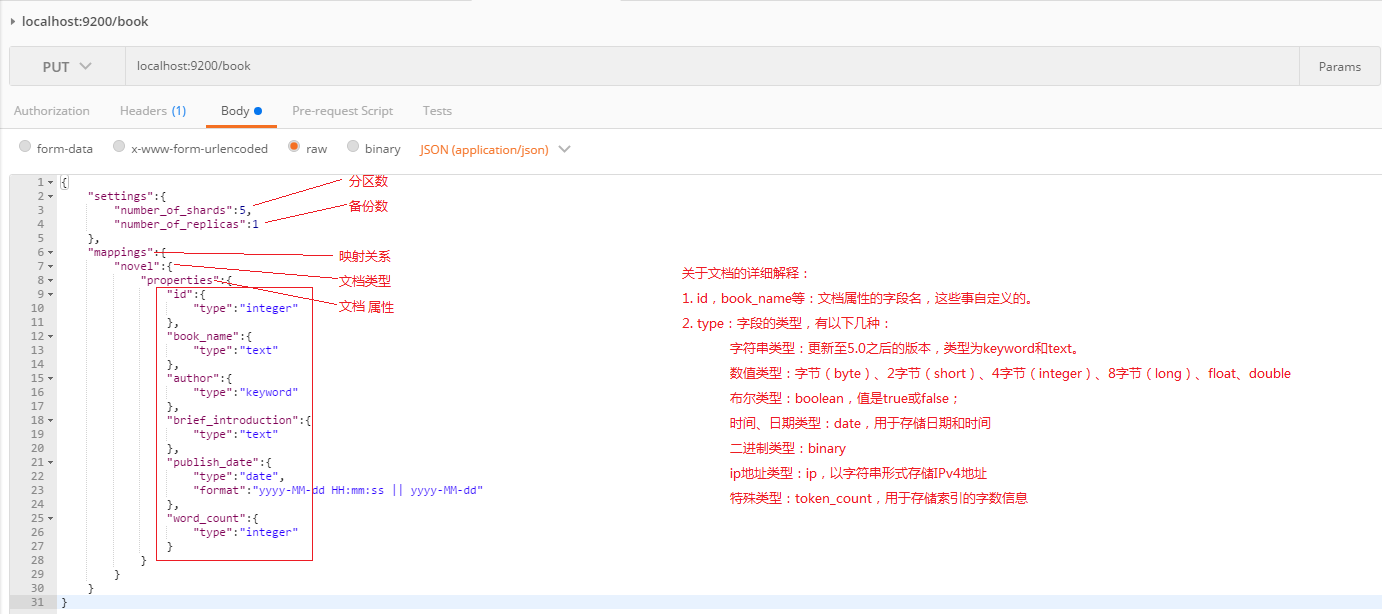
详细的解释下:
type:目前在6.0的时候,有keyword和text,区别为:
keyword:数据类型用来建立电子邮箱地址、姓名、邮政编码和标签等数据类型,不需要进行分词。可以被用来检索过滤、排序和聚合。keyword 类型字段只能用本身来进行检索。
text:Text 数据类型被用来索引长文本,这些文本会被分析,在建立索引前会将这些文本进行分词,转化为词的组合,建立索引。比如你配置了IK分词器,那么就会进行分词,搜索的时候会搜索分词来匹配这个text文档。但是:text 数据类型不能用来排序和聚合
在上篇博客中,我们提到,当我们插入数据的时候,如果有超出我们结构化的数据的时候,索引会自动更新数据,但是很多时候会出现,不是同一个人操作的时候,插入的数据各式各样的,最后导致索引无法使用!如何解决?
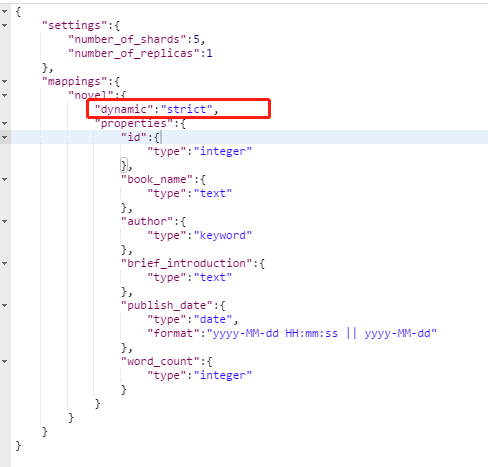
dynamic属性有三个值:
true:默认,可以自动创建索引,插入数据字段不符合的话就创建新的索引。
false:不自动创建索引,当插入数据不符合默认属性的时候,忽略新插入的不符合的字段的值。
strict:精确的,不允许插入不符合默认属性的值,如果不符合,直接报错。
我们可以在创建索引的时候,指定索引是绝对的,精确的,就可以避免因为写错而更新了新的字段,如下图:当然我们也可以设置当插入字段和我们预先定义的映射不符的话,忽略这些新插入的字段,但是这样的话后期查找问题可能会比较麻烦。
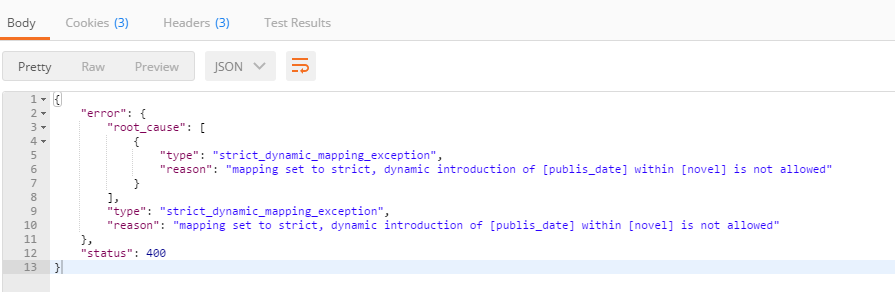
这样的话,当你插入不符合标准化索引的时候,就会提示错误而导致无法插入,当然这样也有麻烦的地方,如果插入数据出错,可能会导致数据丢失,所以如果在项目中你需要这样做的话,最好可以将失败的数据写入日志文件或者直接写入数据库,这样就可以避免数据的丢失了,也可以重新拿到失败的数据进行重新索引。
文档属性定义了文档类型的共用属性,适用于文档的所有字段。当然也可以指定字段属性,只适用于某个特定的字段。
字段的数据类型由字段的属性type指定,ElasticSearch支持的基础数据类型主要有:
1.4.3 字符串类型常用的其他属性
分析器(analyzer)把analyzed string 字段的值,转换成标记流(Token stream),例如,字符串"The quick Brown Foxes",可能被分解成的标记(Token)是:quick,brown,fox。这些词(term)是该字段的索引值,这使用对索引文本的查找更有效率。字段的属性 analyzer 用于指定在index-time和search-time时,ElasticSearch引擎分解字段值的分析器名称。
在使用ElasticSearch的时候,我们会牵扯到很多的请求方法,比如GET,POST,PUT,DELETE等等,这些方法使用的都是Restful的调用风格,我们来简单介绍下这些方法
【elasticsearch】关于elasticSearch的基础概念了解【转载】
原文:https://www.cnblogs.com/sxdcgaq8080/p/10207262.html