如果有一个低方差的模型, 通常通过增加数据集的规模,可以获得更好的结果。

但是如果数据集特别大,则首先应该检查这么大规模是否真的必要,也许只用 1000个训练集也能获得较好的效果,可以绘制学习曲线来帮助判断。
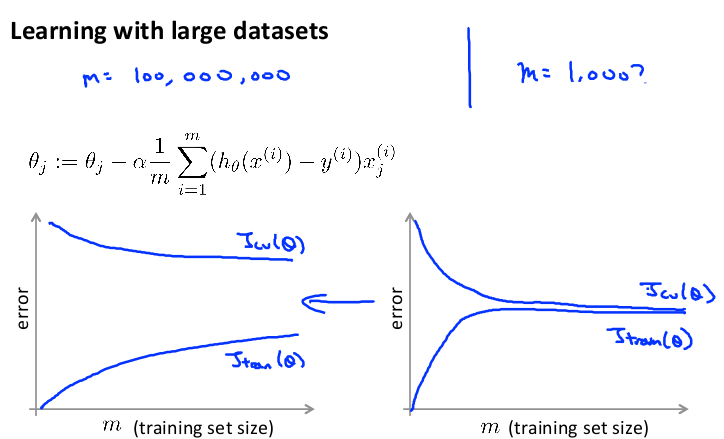
如果必须使用一个大规模的训练集,则可以尝试使用随机梯度下降法(SGD)来代替批量梯度下降法。
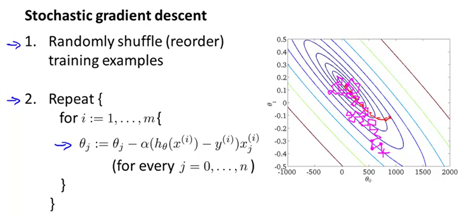
随机梯度下降算法 则首先对训练集随机“洗牌”,然后在每一次计算之后便更新参数 θ
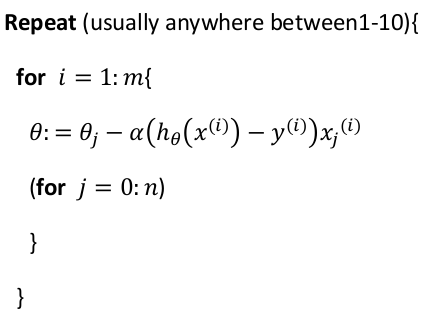
在批量梯度下降算法还没有完成一次迭代时,随机梯度下降算法便已经走出了很远。但 SGD 不是每一步都是朝着”正确”的方向迈出的。因此虽然会逐渐走向全局最小值的位置,但可能无法到达最小值点,而是在附近徘徊。不过很多时候这已经足够了。
小批量梯度下降算法,介于批量梯度下降算法和随机梯度下降算法之间,每计算常数b次训练实例,更新一次参数 θ 。
通常会令 b 在 2-100 之间。小批量梯度下降的好处在于可以用向量化的方式来循环b个训练实例,如果用的线性代数函数库能支持平行处理,那算法的总体表现将与随机梯度下降近似。

在批量梯度下降中,可以令代价函数 J 为迭代次数的函数,绘制图表判断梯度下降是否收敛。但是,在大规模的训练集下不现实,因为计算代价太大。
当数据集很大时使用随机梯度下降算法,这时为了检查随机梯度下降的收敛性,我们在每1000次迭代运算后,对最后1000个样本的cost值求一次平均,将这个平均值画到图中。

下面是可能得到的几种图像:
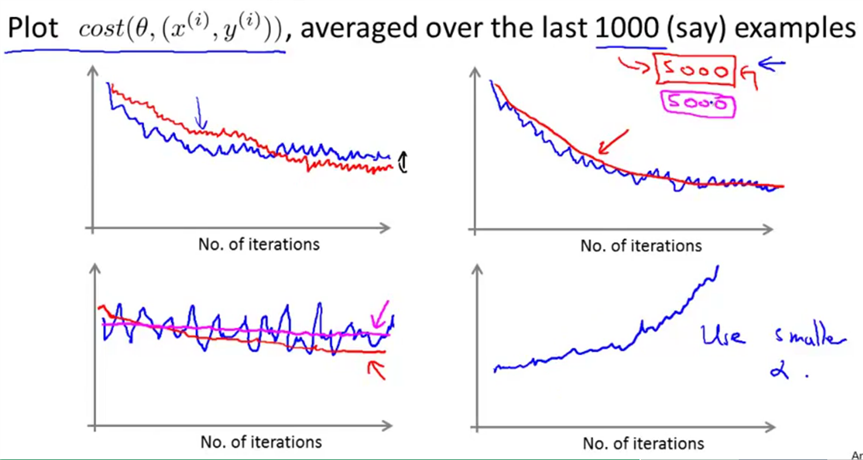
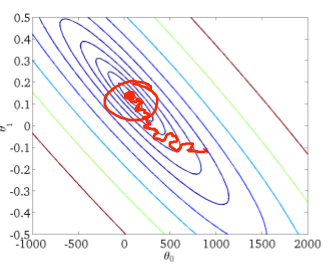
图1:红色线的学习率比蓝色线要小,因此收敛的慢,最后收敛的更好一些。
图2:红线通过对5000次迭代求平均,而不是1000个,得到更加平滑的曲线。
图3:蓝线颠簸不平而且没有明显减少。可以增大α来使得函数更加平缓,也许能使其像红线一样下降;或者可能仍像粉线一样颠簸不平且不下降,说明模型本身可能存在一些错误。
图4:如果曲线正在上升,说明算法发散。应该把学习速率α的值减小。
还可以令学习率随着迭代次数的增加而减小,例如令:
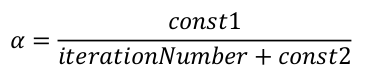
这样,随着不断地靠近全局最小值,学习率会越来越小,迫使算法收敛而非在最小值附近徘徊。
但是通常不需要这样做便能有非常好的效果,对α进行调整所耗费的计算通常不值得。
有一种大规模的机器学习机制,叫做在线学习机制。让我们可以模型化问题。它指的是针对数据流,而非针对离线静态数据集进行学习。例如,许多在线网站都有持续不断的用户流,对于每一个用户,网站希望能不将数据存储到数据库中,便顺利地进行算法学习。
在线学习的算法与随机梯度下降算法有些类似,只对单一的实例进行学习,而非对一个提前定义的训练集进行循环:
Repeat forever (as long as the website is running) {
Get (x, y) corresponding to the current user
θ: = θj − α(hθ(x) − y)xj
(for j = 0: n)
}
一旦对一个数据的学习完成,便可以丢弃它,不需要再存储。这样的好处在于可以针对用户当前行为,不断更新模型以适应该用户。慢慢地调试学习到的假设,将其调节更新到最新的用户行为。

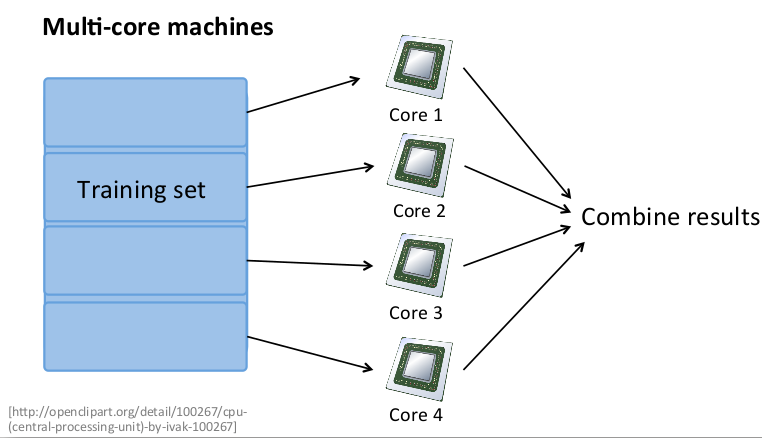
映射化简和数据并行对于大规模机器学习问题而言非常重要。之前提到,批量梯度下降算法计算代价非常大。如果能将数据集分配给多台计算机,让每一台计算机处理数据集的一个子集,然后将结果汇总求和,这样的方法叫做映射简化。
例如有 400 个训练实例,可以将批量梯度下降的求和任务分配给 4 台计算机进行处理:
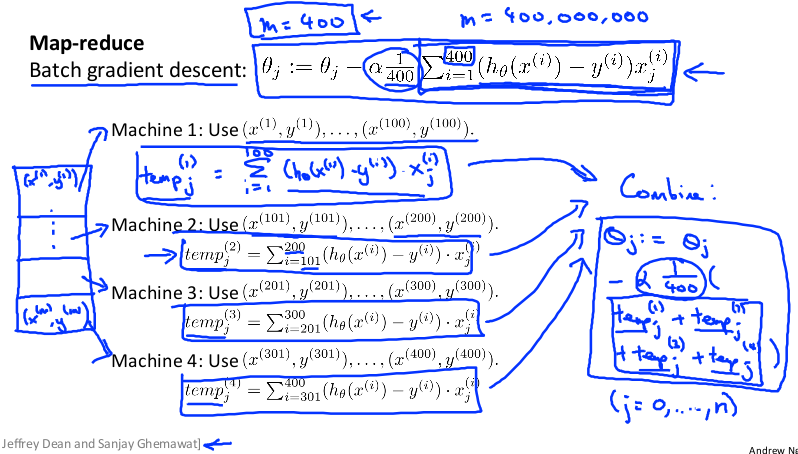
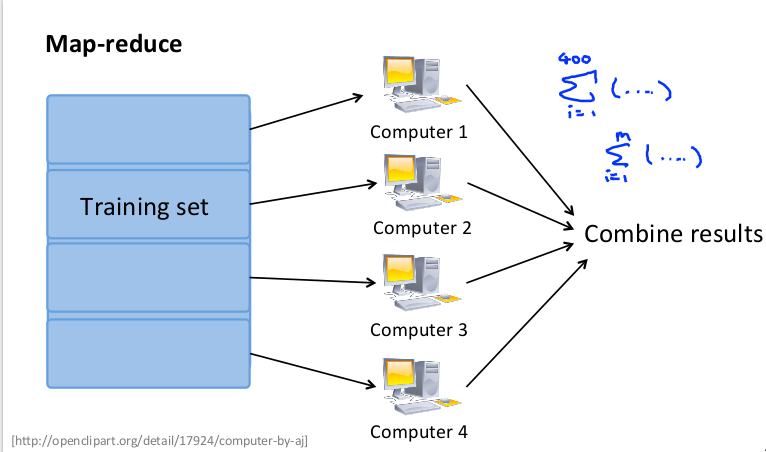
如果任何学习算法能够表达为对训练集函数的求和,那么便能将这个任务分配给多台计算机(或者同一台计算机的不同 CPU 核心),以达到加速处理的目的。例如逻辑回归:

很多高级的线性代数函数库能够利用多核 CPU 的来并行地处理矩阵运算,这也是算法的向量化实现如此重要的缘故(比调用循环快)。
【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 17—Large Scale Machine Learning 大规模机器学习
原文:https://www.cnblogs.com/maxiaodoubao/p/10222170.html