? 并行计算八字原则:负载均衡,通信极小
? 并行计算基本形式:主从并行、流水线并行、工作池并行、功能分解、区域分解、递归分治
? MPI 主要理念:进程 (process);无共享存储;显式消息传递;松散同步 / 完全异步;SPMD 方式编程
? MPI 的主要实现版本
● MPICH,Argonne 国家实验室与 Mississippi 州立大学开发,是最早、最流行的实现
● MVAPICH,Ohio 州立大学开发,基于 MPICH,强调对各类硬件和网络的个性化支持。
● OpenMPI,Stuttgart 大学开发,多个 MPI 开源实现的合并版。
● Intel MPI,Cray MPI,HP-MPI,MS-MPI,……商业版本
? ABI 兼容(application binary interface):由 MPICH 发起,保证各个MPI 实现在底层数据类型上的兼容性
? 阻塞(blocking)与非阻塞(non-blocking)通信(其他见 MPI 部分,这里仅为补充)
● MPI_ISend() 与 MPI_IRecv(),非阻塞通信未结束,不要修改 buf 中的发送数据或使用 buf 中的接收数据
1 int MPI_Isend(void *buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm, MPI_Request *request) 2 int MPI_Irecv(void *buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Request *request)
● 取消非阻塞通信,需要传入信号标记
1 int MPI_Cancel(MPI_Request *request)
● 检测非阻塞通信是否已经结束,返回 flag==0 表示结束(即时返回)
1 int MPI_Test(MPI_Request *request, int *flag, MPI_Status *status)
● 等待非阻塞通信结束(通信结束后返回)
1 int MPI_Wait(MPI_Request *request, MPI_Status *status)
● 检测 / 等待多个非阻塞通信
1 int MPI_Testall(int count, MPI_Request requests[], int *flag, MPI_Status statuses[]) 2 int MPI_Waitall(int count, MPI_Request requests[], MPI_Status statuses[])
● 检测/等待任一个非阻塞通信
1 int MPI_Testany(int count, MPI_Request requests[], int *index, int *flag, MPI_Status *status) 2 int MPI_Waitany(int count, MPI_Request requests[], int *index, MPI_Status *status)
● 检测/等待任一些非阻塞通信
1 int MPI_Testsome(int incount, MPI_Request array_of_requests[], int *outcount, int array_of_indices[], MPI_Status array_of_statuses[]); 2 int MPI_Waitsome(int incount, MPI_Request array_of_requests[], int *outcount, int array_of_indices[], MPI_Status array_of_statuses[]);
● mpicc 的参数
1 -o # 指定输出文件名,默认为 a.out 2 -g # 调试选项,产生调试信息 3 -L # 指定链接库路径 4 -l # 指定链接库的简称,如数学库 -lm 5 -I # 指定头文件路径 6 -D # 相当于 C 语言里面的宏定义 7 -Wall # 打开警告选项 8 -std # 指定 C 标准,如 -std=c99 使用 c99 标准
? 线程与进程的关系:线程可以被看作是进程的一部分,一个进程可以开启多个线程;线程继承了进程的资源 (比如指令、内存等);线程相互独立的并发 (concurrent) 执行;对于单处理器核,多线程可以通过多任务 (multi-tasking) 亦称为时间切片 (time-slicing) 的方式由处理器轮流分时执行,此时也称为软件线程 (software threads)。
? OpenMP 要素和作用
● 运行时库(run-time library)主要包括头文件 (omp.h)、库函数的调用和链接。
■ 用途:
Setting and querying the number of threads;
Querying thread ID, ancestor’s ID, and thread team size;
Setting and querying the dynamic threads feature;
Querying if in a parallel region, and at what level;
Setting and querying nested parallelism;
Setting, initializing and terminating locks and nested locks;
Querying wall clock time and resolution
● 环境变量(environment variable)预定义变量,运行时控制程序的行为。
■ 用途:
Setting the number of threads;
Specifying how loop interations are divided;
Binding threads to processors;
Enabling/disabling/setting nested parallelism;
Enabling/disabling dynamic threads;
Setting thread stack size and wait policy
● 编译制导语句(compiler directive)特殊格式的注释来实现功能,否则忽略。
■ 用途:
Spawning a parallel region;
Dividing blocks of code among threads;
Distributing loop iterations between threads;
Serializing sections of code;
Synchronization of work among threads
? if 从句:表达式为真则按照并行方式执行并行区,否则主线程串行执行并行区
?按照优先级从低到高,并行区中的线程数按照下面的顺序确定:
● if 从句
● num_threads 从句设定
● omp_set_num_threads 库函数设定
● OMP_NUM_THREADS 环境变量设定
● 系统默认(一般是可用的处理器核数)
? 考虑程序可以并行的条件。任给两个程序 P1,P2,及各自输入和输出 I(P1),I(P2),O(P1),O(P2),有 Bernstein 条件:
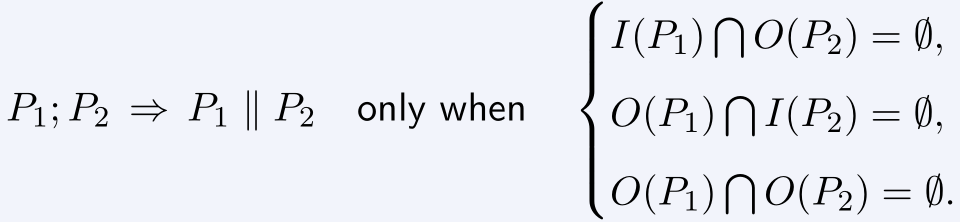
? 串行一致性(sequential consistency)调整并行程序的语句顺序,使得输入不变时输出也不变,则称这种调整满足串行一致性
? 基本依赖定理(Fundamental Theorem of Dependence)当且仅当程序中所有不可消除的数据依赖都得以满足的条件下,并行程序的执行满足串行一致性(一个需要排除的特例:规约)
● 三种基本数据依赖关系
■ 流依赖 (flow dependence):RAW = Read After Write,唯一一种不可消除的依赖
■ 反依赖 (anti-dependence): WAR = Write After Read
■ 输出依赖 (output dependence): WAW = Write After Write
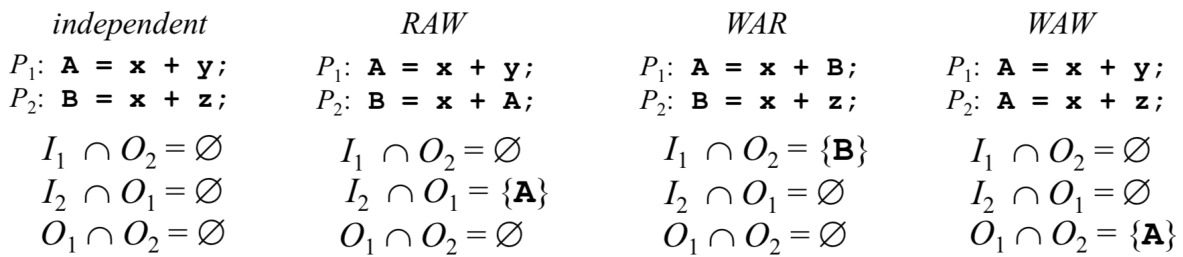
● 消除数据依赖:变量消去、变量私有化、变量替换、循环倾斜(loop skewing,调整每个循环内的操作,可能会有部分操作移到循环头部或尾部以外)
? section 导语:对并行区内非循环任务多线程并行执行,每个程序段被执行一次,无法提前得知线程分配到的任务
1 #pragma omp sections [clause1 clause2 ...] 2 { 3 #pragma omp section 4 code1(); 5 #pragma omp section 6 code2(); 7 ... 8 }
? single 从句:对并行区内任务单线程执行,无法提前得知执行的线程,其他线程等待该线程执行完毕后进行同步,一般用于处理非线程安全(thread safe)的任务,如 I/O、共享变量赋值等
1 { 2 #pragma omp single [clause] 3 code(); 4 }
? nowait 从句:去掉工作共享构造末尾的隐式栅栏同步,可以用于 for、sections、single
? order 从句:串行执行 for 循环
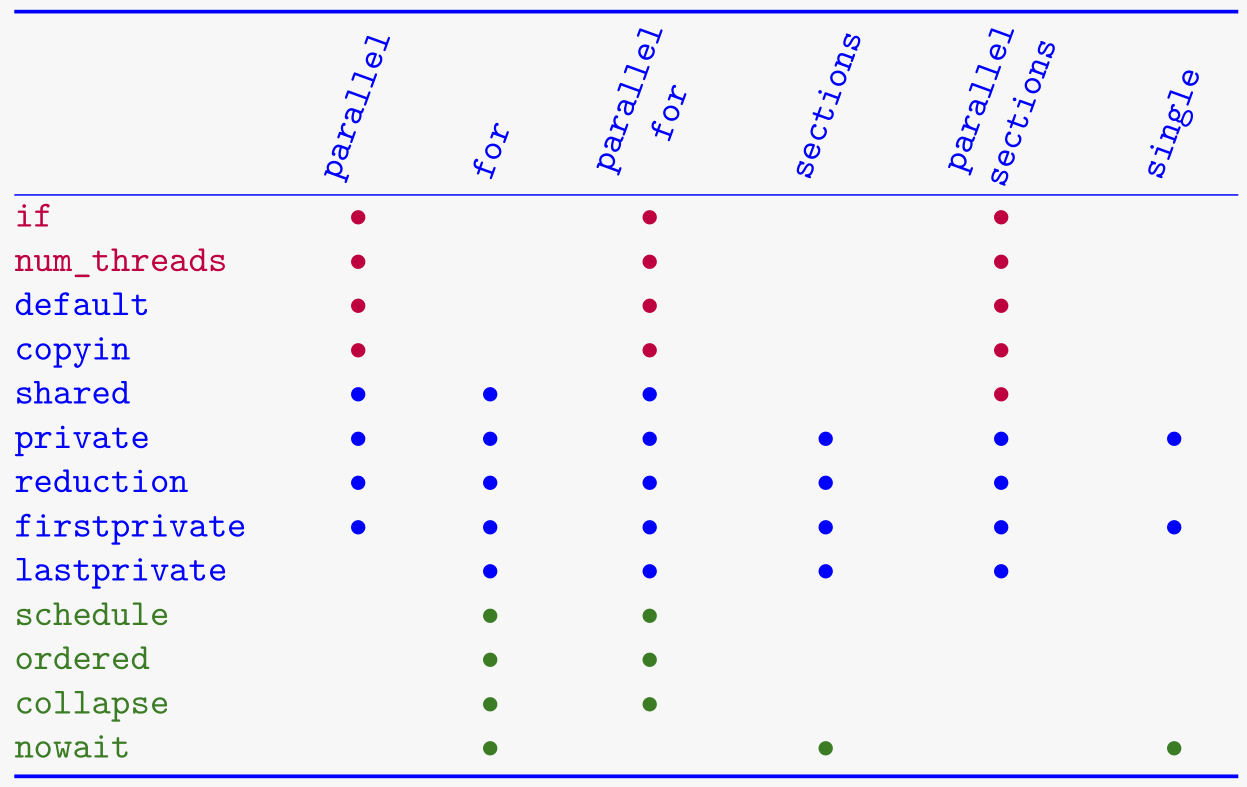
? 从句支持
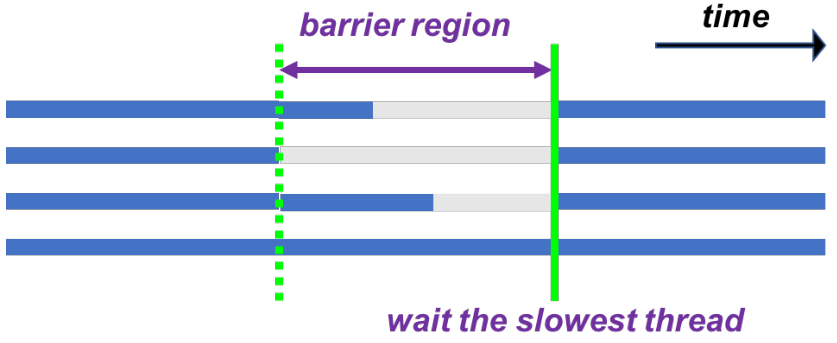
? 同步构造
● barrier 构造:栅栏同步
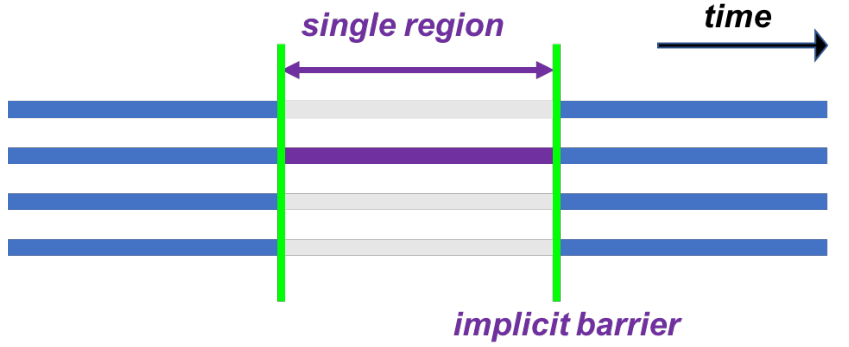
● single 构造:单线程执行,有同步
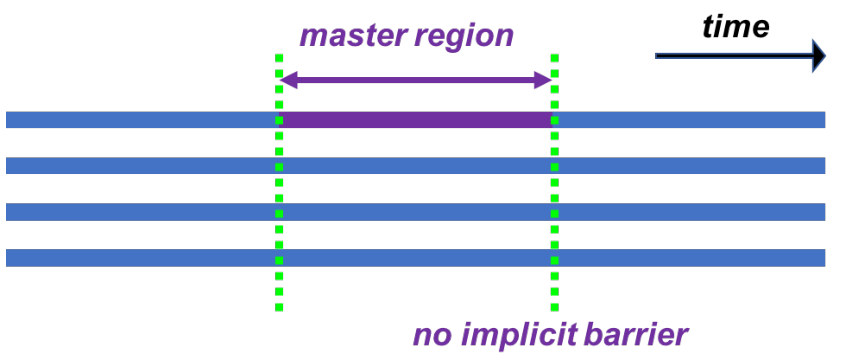
● master 构造:主线程执行,无同步
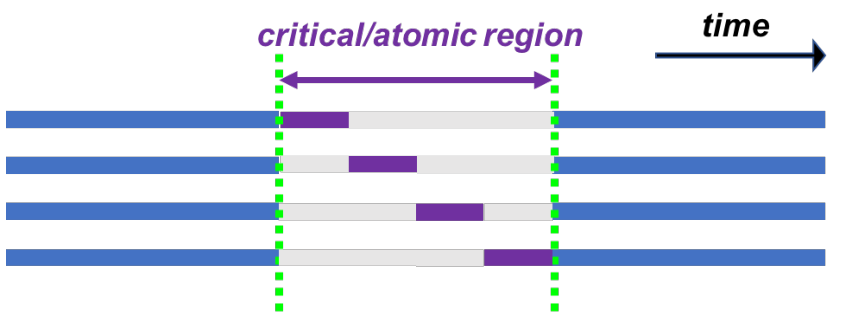
● critical 构造:依次执行,程序片段
● atomic 构造:依次执行,单一指令
? 松弛一致性 (relaxed consistency)
● OpenMP 的共享变量在本地缓存中的修改并不随时更新到内存,flush 从句用于手动更新当前线程本地缓存中的数据。
● OpenMP 的一些同步操作隐含包含了 flush,如并行区 / critical 区入出口(注意工作共享构造的入口不隐含 flush),显式 / 隐式的 barrier 操作等
● flush 一般置于共享变量的写操作后或读操作前
● 合理的算法设计一般不需要显式 flush
? 程序的遗孤 (orphaning)(?)
● 遗孤:“工作共享” 和 “同步” 可以放在并行区静态范围外;如果在动态范围之内,则等同于非遗孤情况;否则,制导语句不起作用
● sections 构造不支持遗孤
? OpenMP 工作共享构造的缺陷
● 任务必须可数(for 循环或者 section 区块),链表、递归等无法支持
原文:https://www.cnblogs.com/cuancuancuanhao/p/10220527.html