集合点:
简单来理解一下,虽然我们的“性能测试”理解为“多用户并发测试”,但真正的并发是不存在的,为了更真实的实现并发这感念,我们可以在需要压力的地方设置集合点,每到输入用户名和密码登录时,所有的虚拟用户都相互之间等一等,然后,一起访问。
注意:
1.JMeter里面的集合点通过添加定时器来完成。
2.Synchronizing timer仅作用于同一个JVM中的线程。
集合点
1) 启动路径
2)用法
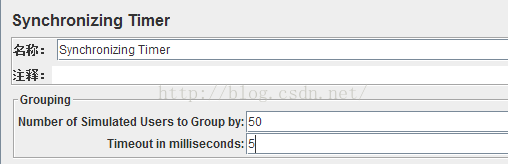
Number of Simulated Users to Group by:集合多少人后再执行请求(也就是执行的线程数)
注意:等同于设置为线程租中的线程数,一定要确保设置的值不大于它所在线程组包含的用户数。
Timeout in milliseconds:指定人数 多少秒没集合到算超时(设置延迟时间以毫秒为单位)
注意:如果设置Timeout in milliseconds为0,表示无超时时间,会一直等下去。
线程数量无法达到"Number of Simultaneous Users to Group by"中设置的值,那么Test将无限等待,除非手动终止。
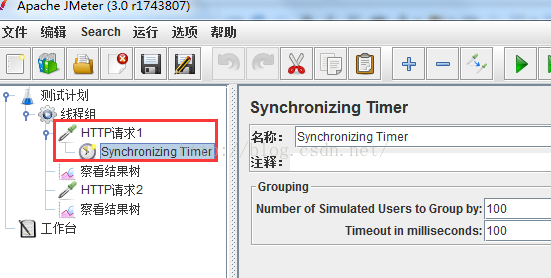
3)如果希望定时器仅应用于其中一个sampler,则把该定时器作为子节点加入,如下图
定时器仅仅对HTTP请求1起作用,即仅在HTTP请求1执行前执行定时器,和HTTP请求2无关。
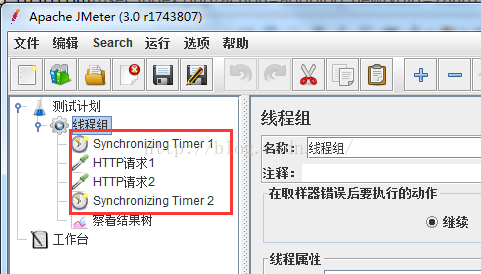
3)如果你希望synchronizing timer应用于多个sampler.
如下,执行HTTP请求1和HTTP请求2前都会执行同步定时器1、2。当执行一个sampler之前时,和sampler处于相同作用域的定时器都会被执行;
注意点:
-----集合点的位置一定要在Sample(采样器)之前才能生效吗???”
在Jmeter中,timer是在sampler之前执行的。不管这个定时器的位置放在sampler之后,还是之前。当然,如果有多个timer的时候,在相同作用域下,会按上下顺序执行timer,这个就需要慎重放置timer的顺序;不过,为了更好的可读性,还是建议将timer放在对应的sampler前面 或 子节点中;
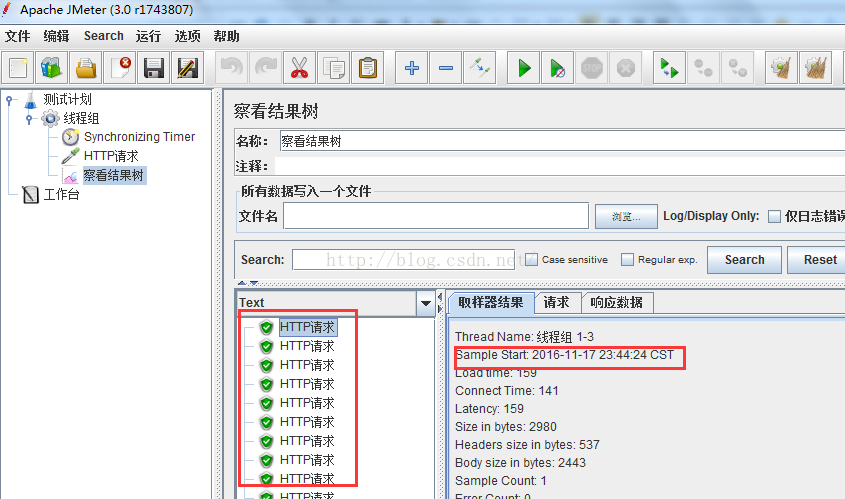
5) 进行必要设置后,运行查看效果,通过结果树可以看到,请求是批量执行的。
可以观察开始执行的脚本,观察请求的增加数量趋势;或对比请求的发送时间.
补充: Synchronizing timer 仅作用于同一个JVM中的线程。
试想:
a.如果分布式测试时,synchronizing timer作用于所有jvm,那么jvm之间或者说监控jvm工作的部件就需要频繁通讯,确定线程的数量及状态等,然后集结了足够的线程后,又要发送信号让Jmeter来发送测试请求,中间存在延时,这样就无法模拟更真实的高并发了,而且这个东西还会消耗测试机器的一部分性能,会给测试结果带来负面影响;所以暂时是只支持控制单个jvm,如果后面有办法解决上面那些问题后,就可以实现控制多个jvm,控制总并发量;
b.如果分布式测试,并使用了Synchronizing timer,且设置的值是小于单个jvm的线程数量;但是,较难确保所有jvm都在同一时间点集结了同样数量的线程数,这样就很难下测试结论了,因为都不知道是多少并发下的性能表现;当然了,可以将线程的启用时间拉长,并将超时时间延长,这样就很可能会与同一时刻集结到足够的线程,达到超高并发的测试;所以,分布式测试与Synchronizing timer一般不是同时使用的;如果非要用,则需要慎重设置相关参数
---------------------
作者:ZJQ2016
来源:CSDN
原文:https://blog.csdn.net/zjq001x/article/details/53107159
版权声明:本文为博主原创文章,转载请附上博文链接!
原文:https://www.cnblogs.com/kaibindirver/p/10247678.html