今天大概的整理了一下java集合框架,在这里做一个小结,方便以后查阅,本博文主要参考资料为《java编程思想第四版》第11章——持有对象以及JAVA 1.6 API文档。并没有研究更深入的第17章<容器深入研究>。大概介绍了集合框架中几个比较常用的集合类。
以下为正文。
首先来看一张图,不太会用visio,画的可能不太好看
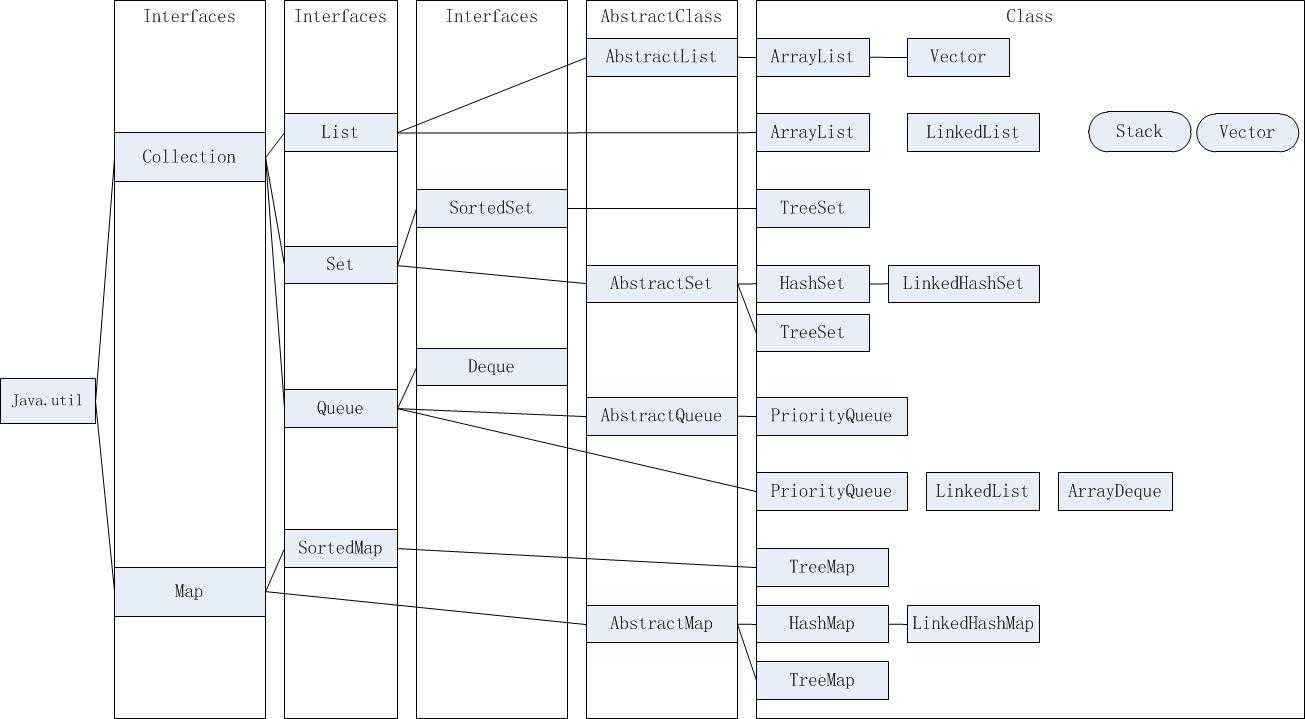
图中将接口、抽象类、实现类、淘汰类(圆角矩形)进行标注。有直线连接的类(或接口)表示是子类关系或者实现关系
由图示可以看出,集合类主要有两个集合接口:
1.Collection: 独立元素的序列。
2.Map: 成对出现的“键值对”对象序列。
Collection集合:
1.1 List(数组的升级版)
List集合即是数据结构中所讲的线性表。此接口的可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引访问元素,并搜索列表中的元素。列表通常允许重复的元素。
List有一个抽象类:AbstractList,该子接口又有两个子类:ArrayList,Vector(已废弃)
ArrayList即顺序表,其内部数据结构就是一个数组。相对于数组而言,最大的优点即支持扩容。相对于LinkedList的优点在于支持随机检索。缺点在于插入,删除节点效率低下。
LinkedList即链表,但是其内部实现是双向链表,而非单链表。相对于顺序表而言的有点在于,插入、删除节点效率高,虽然支持索引访问,但是其本质是遍历链表,因此访问效率低下。
Vector与ArrayList的区别:
1.同步性:Vector是线程安全的,也就是说是同步的,而ArrayList是线程序不安全的,不是同步的
2.数据增长:当需要增长时,Vector默认增长为原来一培,而ArrayList却是原来的一半 。
1.2 Set(主要用于检测归属性)
Set是真正数学意义上的集合。其特点即确定性、互异性、无序性。
Set接口有一个子接口SortedSet及一个抽象子类AbstractSet。
最常用的实现类有三个:HashSet、LinkedHashSet(HashSet的子类)以及TreeSet
HashSet-基于散列表的集,加进散列表的元素要实现hashCode()方法,访问速度非常快。
LinkedHashSet-同样是根据元素的hashCode值来决定元素的存储位置,但是它同时使用链表维护元素的次序。这样使得元素看起 来像是以插入顺序保存的,也就是说,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。
TreeSet-基于(平衡)树的数据结构。TreeSet是SortedSet接口的唯一实现类,TreeSet可以确保集合元素处于排序状态。TreeSet支持两种排序方式,自然排序 和定制排序,其中自然排序为默认的排序方式。
1.3 Queue(并发编程中很重要)
Queue即数据结构中所提到的“队列”,其实队列的功能完全可以由线性表实现。事实上,“队列”和“栈”也的确是有插入删除规范的线性表。java也很体贴的让LinkedList实现了Queue接口。(ArrayList并不合适)
如图中所示
Queue接口有一子接口:Deque和一抽象类AbstractQueue,并有三个常用实现类PriorityQueue,LinkedList,ArrayDeque
LinkedList自不必说。
PriorityQueue(常称为优先级队列)是不同于FIFO队列的另一种队列。其是个基于优先级堆的极大优先级队列。此队列按照在构造时所指定的顺序对元素排序,既可以根据元素的自然顺序来指定排序(参阅 Comparable),
1: 该队列是用数组实现(堆),但是数组大小可以动态增加,容量无限。2: 此实现不是同步的。不是线程安全的。如果多个线程中的任意线程从结构上修改了列表, 则这些线程不应同时访问 PriorityQueue 实例,这时请使用线程安全的PriorityBlockingQueue 类。
3: 不允许使用 null 元素。
4: 此实现为插入方法(offer、poll、remove() 和 add 方法)提供 O(log(n)) 时间(堆的调整); 为 remove(Object) 和 contains(Object) 方法提供线性时间; 为检索方法(peek、element 和 size)提供固定时间。
2. Map
Map接口不是Collection接口的继承。
Map接口用于维护键/值对。该接口描述了从不重复的键到值的映射。Map 接口提供三种collection 视图,允许以键集、值集合或键-值映射关系集的形式查看某个映射的内容:
Set keySet(): 返回映像中所有关键字的视图集
Collection values():返回映像中所有值的视图集
Set entrySet(): 返回Map.Entry对象的视图集,即映像中的关键字/值对
Map接口有一个子接口SortedMap,该接口有两个实现类:TreeMap(ConcurrentSkipListMap不常用,不作讨论)
由于TreeMap它底层采用一棵“红黑树”来保存集合中的 Entry,这意味这 TreeMap 添加元素、取出元素的性能都比HashMap 低O(lgN):当 TreeMap 添加元素时,需要通过循环找到新增 Entry 的插入位置,因此比较耗性能;当从TreeMap 中取出元素时,需要通过循环才能找到合适的 Entry,也比较耗性能。但 TreeMap、TreeSet 比HashMap、HashSet 的优势在于:TreeMap 中的所有 Entry 总是按 key 根据指定排序规则保持有序状态,TreeSet 中所有元素总是根据指定排序规则保持有序状态,对排序二叉树,若按中序遍历就可以得到由小到大的有序序列。
Map接口有一个抽象类,并有三个常用的实现子类:HashMap,LinkedHashMap(HashMap的子类)、以及TreeMap
HashMap,其中最最常用的即HashMap。在Map 中插入、删除和查找元素,HashMap 是最好的选择。但如果您要按自然顺序或自定义顺序遍历键,那么TreeMap会更好。使用HashMap要求添加的键类明确定义了hashCode()和equals()的实现。
LinkedHashMap:扩展HashMap,以插入顺序将关键字/值对添加进链接哈希映像中。象LinkedHashSet一样,LinkedHashMap内部也采用双重链接式列表。所以迭代顺序也就是插入顺序。
Collection 和 Collections的区别。
Collections是个java.util下的类,它包含有各种有关集合操作的静态方法。
Collection是个java.util下的接口,它是各种集合结构的父接口
ArrayList和Vector的区别。
一.同步性:Vector是线程安全的,也就是说是同步的,而ArrayList是线程序不安全的,不是同步的
二.数据增长:当需要增长时,Vector默认增长为原来一培,而ArrayList却是原来的一半
HashMap和Hashtable的区别
一.历史原因:Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现二.同步性:Hashtable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的
三.值:只有HashMap可以让你将空值作为一个表的条目的key或value
java集合框架小结(初级版),布布扣,bubuko.com
原文:http://www.cnblogs.com/huntfor/p/3889220.html