转载一篇自己在公司博客上的文章
Druid 是 MetaMarket 公司研发,专为海量数据集上的做高性能 OLAP (OnLine Analysis Processing)而设计的数据存储和分析系统,目前Druid已经在Apache基金会下孵化。Druid的主要特性:
Druid常见应用的领域:
有赞作为一家 SaaS 公司,有很多的业务的场景和非常大量的实时数据和离线数据。在没有是使用 Druid 之前,一些 OLAP 场景的场景分析,开发的同学都是使用 SparkStreaming 或者 Storm 做的。用这类方案会除了需要写实时任务之外,还需要为了查询精心设计存储。带来问题是:开发的周期长;初期的存储设计很难满足需求的迭代发展;不可扩展。
在使用 Druid 之后,开发人员只需要填写一个数据摄取的配置,指定维度和指标,就可以完成数据的摄入;从上面描述的 Druid 特性中我们知道,Druid 支持 SQL,应用 APP 可以像使用普通 JDBC 一样来查询数据。通过有赞自研OLAP平台的帮助,数据的摄取配置变得更加简单方便,一个实时任务创建仅仅需要10来分钟,大大的提高了开发效率。
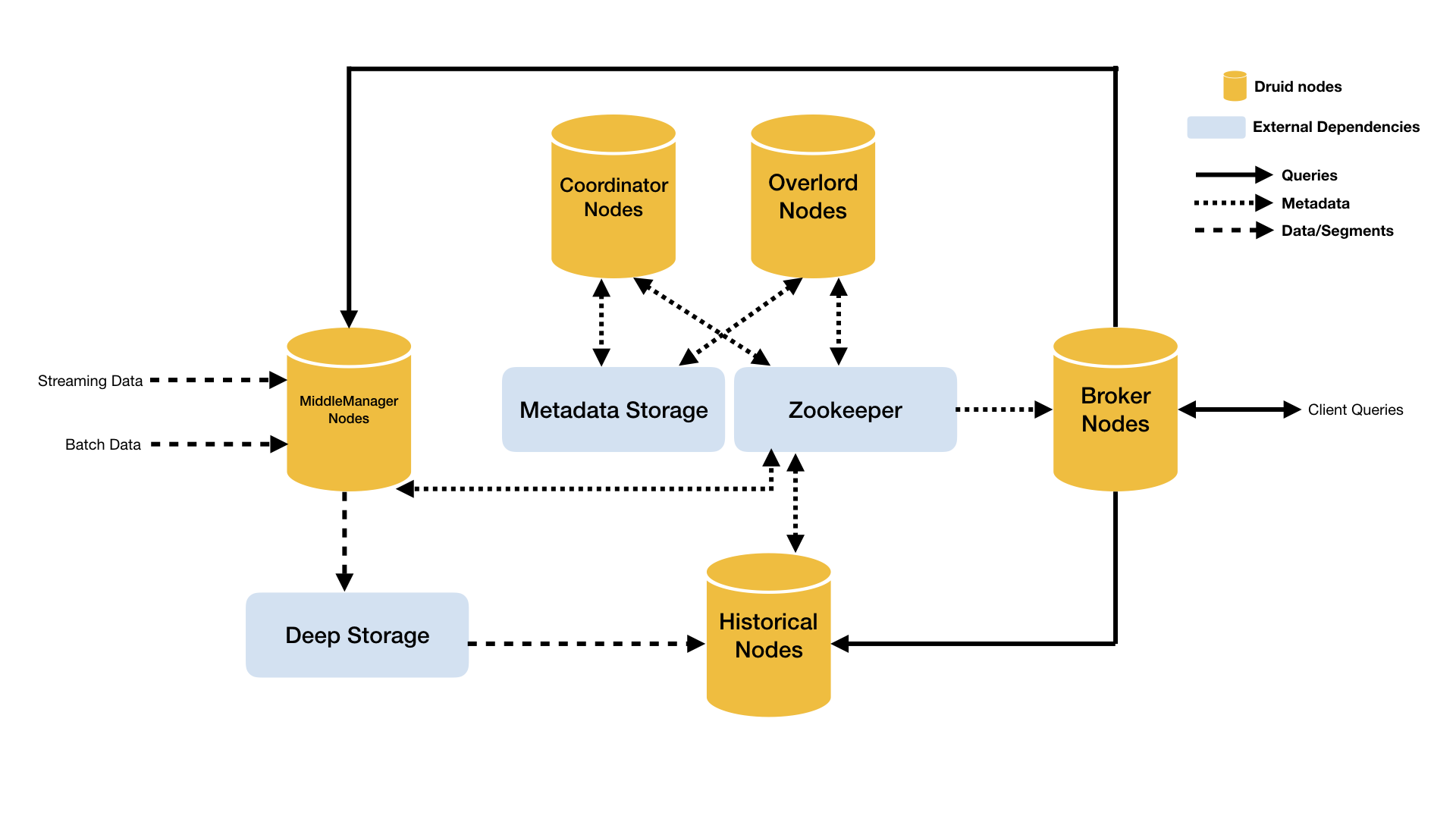
Druid 的架构是 Lambda 架构,分成实时层( Overlord、 MiddleManager )和批处理层( Broker 和 Historical )。主要的节点包括(PS: Druid 的所有功能都在同一个软件包中,通过不同的命令启动):
有赞 OLAP 平台的主要目标:
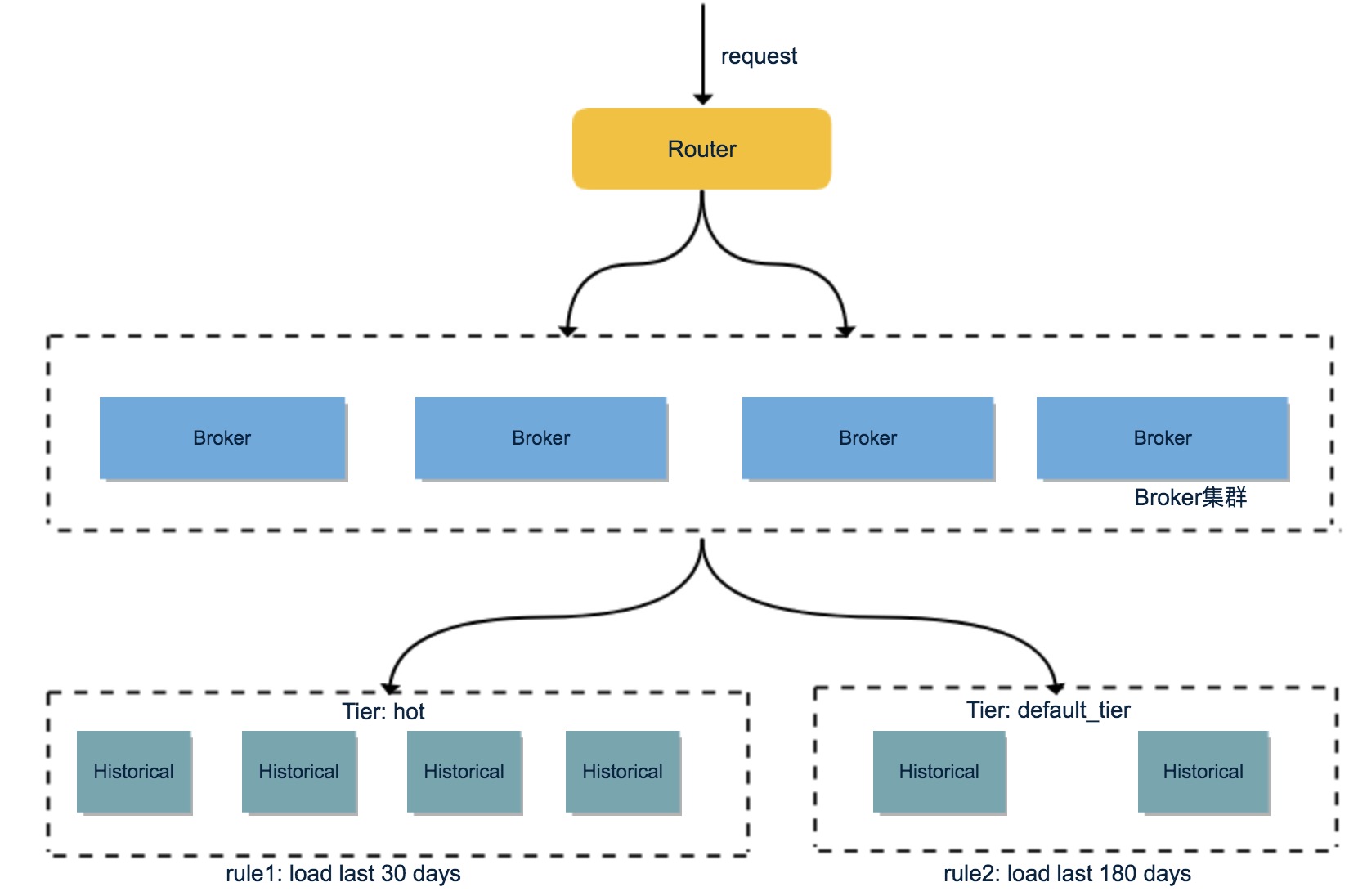
有赞 OLAP 平台架构
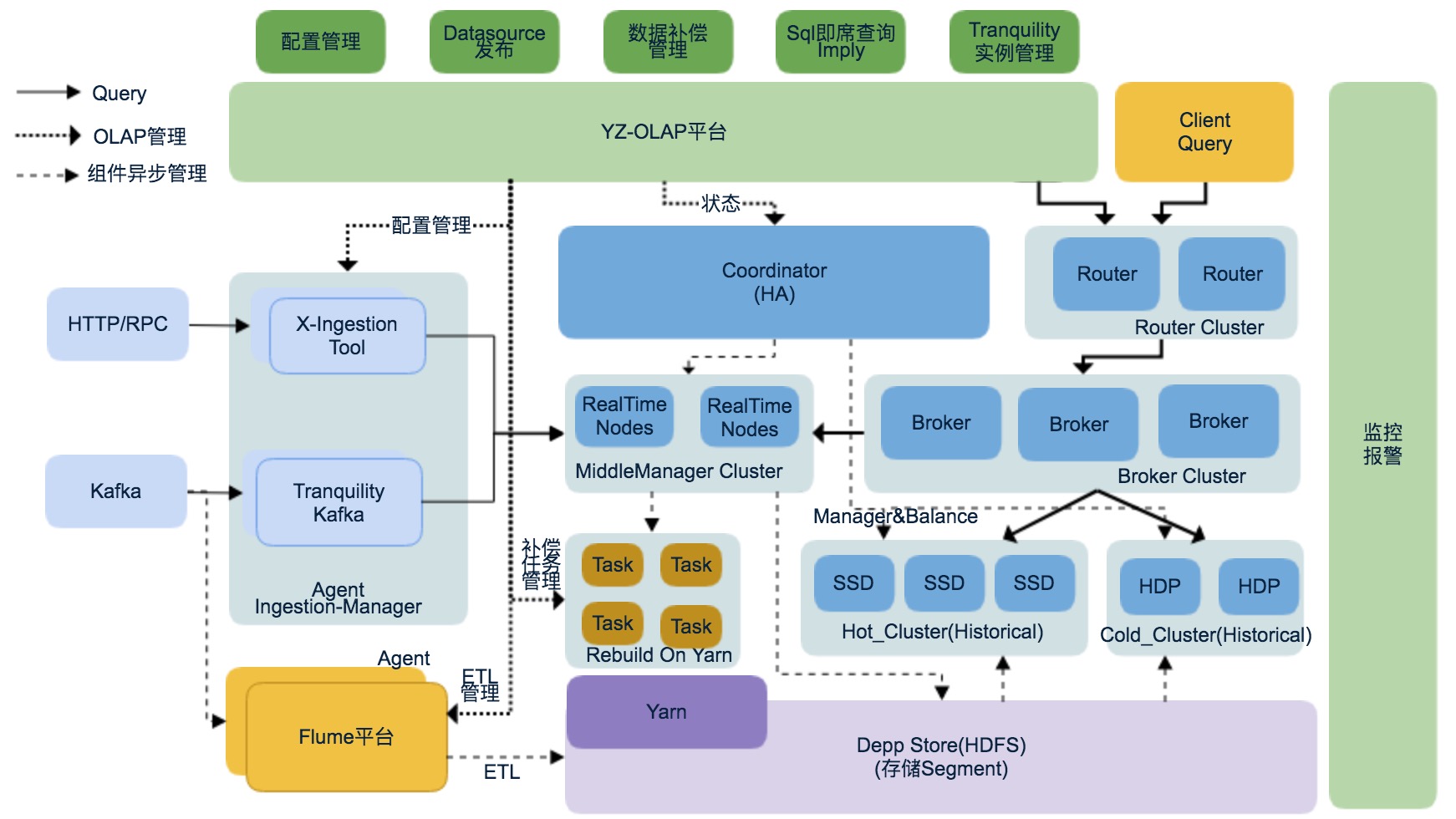
有赞 OLAP 平台是用来管理 Druid 和周围组件管理系统,OLAP平台主要的功能:
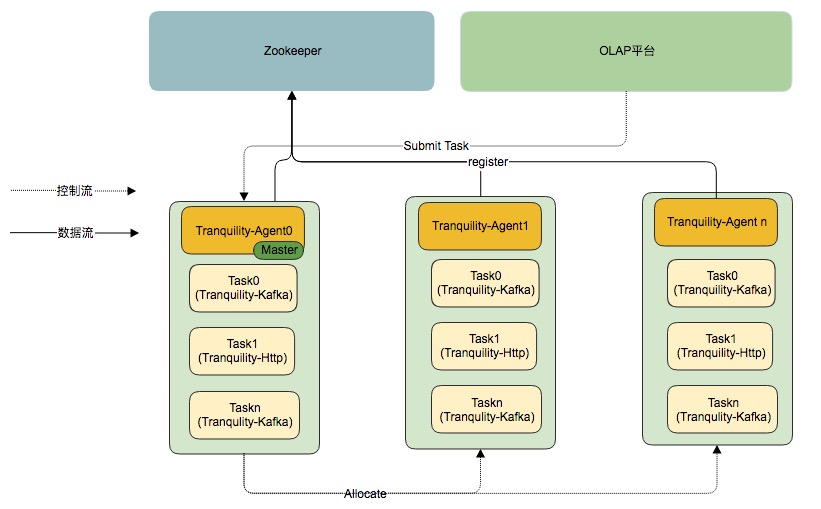
OLAP 平台采用的数据摄取方式是Tranquility工具,根据流量大小对每个 DataSource 分配不同 Tranquility 实例数量; DataSource 的配置会被推送到 Agent-Master 上,Agent-Master 会收集每台服务器的资源使用情况,选择资源丰富的机器启动 Tranquility 实例,目前只要考虑服务器的内存资源。同时 OLAP 平台还支持 Tranquility 实例的启停,扩容和缩容等功能。
流式数据处理框架都会有时间窗口,迟于窗口期到达的数据会被丢弃。如何保证迟到的数据能被构建到 Segment 中,又避免实时任务窗口长期不能关闭。我们研发了 Druid 数据补偿功能,通过 OLAP 平台配置流式 ETL 将原始的数据存储在 HDFS 上,基于 Flume 的流式 ETL 可以保证按照 Event 的时间,同一小时的数据都在同一个文件路径下。再通过 OLAP 平台手动或者自动触发 Hadoop-Batch 任务,从离线构建 Segment。
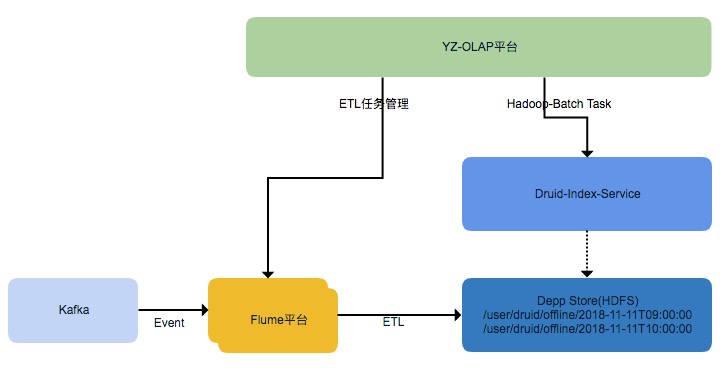
基于 Flume 的 ETL 采用了 HDFS Sink 同步数据,实现了 Timestamp 的 Interceptor,按照 Event 的时间戳字段来创建文件(每小时创建一个文件夹),延迟的数据能正确归档到相应小时的文件中。
随着接入的业务增加和长期的运行时间,数据规模也越来越大。Historical 节点加载了大量 Segment 数据,观察发现大部分查询都集中在最近几天,换句话说最近几天的热数据很容易被查询到,因此数据冷热分离对提高查询效率很重要。Druid 提供了Historical 的 Tier 分组机制与数据加载 Rule 机制,通过配置能很好的将数据进行冷热分离。
首先将 Historical 群进行分组,默认的分组是"_default_tier",规划少量的 Historical 节点,使用 SATA 盘;把大量的 Historical 节点规划到 "hot" 分组,使用 SSD 盘。然后为每个 DataSource 配置加载 Rule :
{"type":"loadByPeriod","tieredReplicants":{"hot":1}, "period":"P30D"}
{"type":"loadByPeriod","tieredReplicants":{"_default_tier":1}, "period":"P180D"}
{"type":"dropForever"}提高 "hot"分组集群的 druid.server.priority 值(默认是0),热数据的查询都会落到 "hot" 分组。
Druid 架构中的各个组件都有很好的容错性,单点故障时集群依然能对外提供服务:Coordinator 和 Overlord 有 HA 保障;Segment 是多副本存储在HDFS/S3上;同时 Historical 加载的 Segment 和 Peon 节点摄取的实时部分数据可以设置多副本提供服务。同时为了能在节点/集群进入不良状态或者达到容量极限时,尽快的发出报警信息。和其他的大数据框架一样,我们也对 Druid 做了详细的监控和报警项,分成了2个级别:
目前比较常用的数据摄取方案是:KafkaIndex 和 Tranquility 。我们采用的是 Tranquility 的方案,目前 Tranquility支持了 Kafka 和 Http 方式摄取数据,摄取方式并不丰富;Tranquility 也是 MetaMarket 公司开源的项目,更新速度比较缓慢,不少功能缺失,最关键的是监控功能缺失,我们不能监控到实例的运行状态,摄取速率、积压、丢失等信息。
目前我们对 Tranquility 的实例管理支持启停,扩容缩容等操作,实现的方式和 Druid 的 MiddleManager 管理 Peon 节点是一样的。把 Tranquility 或者自研摄取工具转换成 Yarn 应用或者 Docker 应用,就能把资源调度和实例管理交给更可靠的调度器来做。
Druid 目前并不没有支持JOIN查询,所有的聚合查询都被限制在单 DataSource 内进行。但是实际的使用场景中,我们经常需要几个 DataSource 做 JOIN 查询才能得到所需的结果。这是我们面临的难题,也是 Druid 开发团队遇到的难题。
对于 C 端的 OLAP 查询场景,RT 要求比较高。由于 Druid 会在整点创建当前小时的Index任务,如果查询正好落到新建的 Index 任务上,查询的毛刺很大,如下图所示:
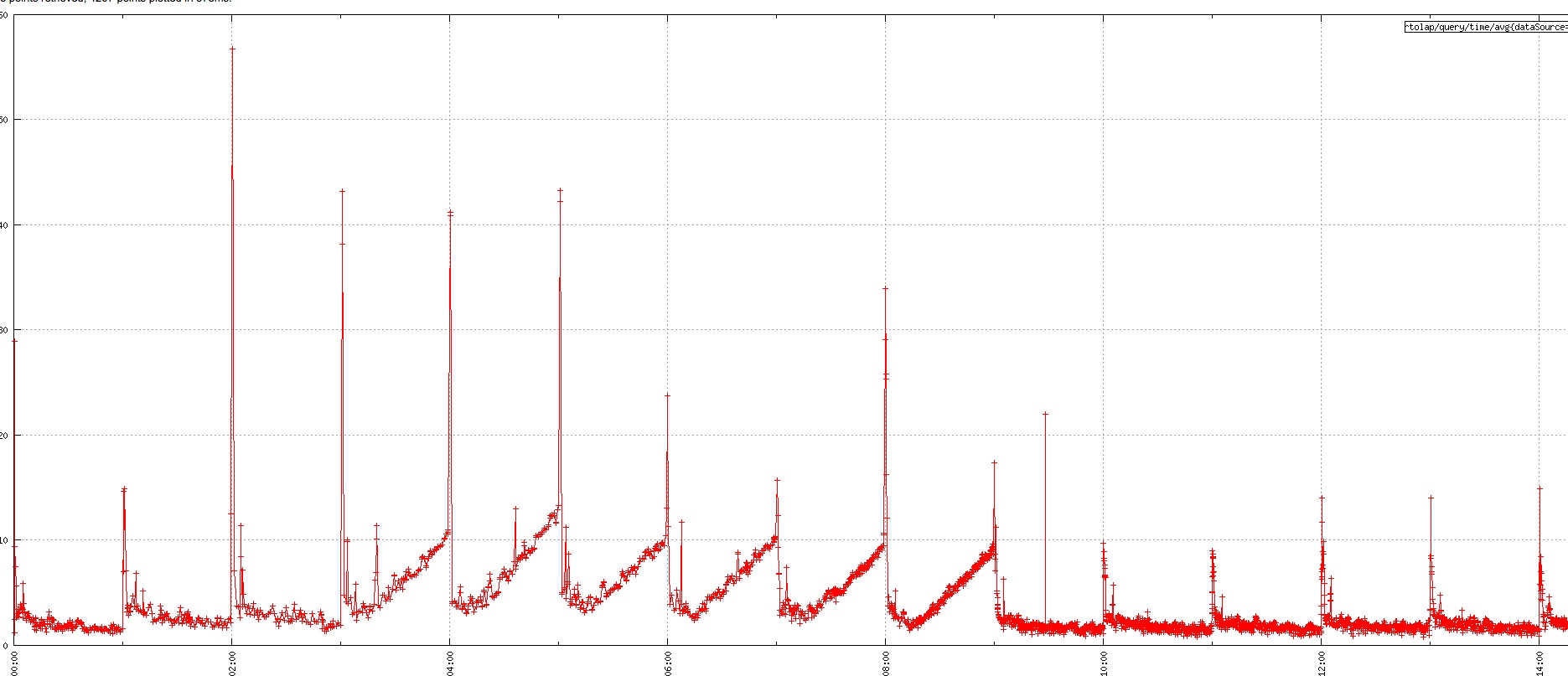
我们已经进行了一些优化和调整,首先调整 warmingPeriod 参数,整点前启动 Druid 的 Index 任务;对于一些 TPS 低,但是 QPS 很高的 DataSource ,调大 SegmentGranularity,大部分 Query 都是查询最近24小时的数据,保证查询的数据都在内存中,减少新建 Index 任务的,查询毛刺有了很大的改善。尽管如此,离我们想要的目标还是一定的差距,接下去我们去优化一下源码。
现在大部分 DataSource 的 Segment 粒度( SegmentGranularity )都是小时级的,存储在 HDFS 上就是每小时一个Segment。当需要查询时间跨度比较大的时候,会导致Query很慢,占用大量的 Historical 资源,甚至出现 Broker OOM 的情况。如果 OLAP 平台能提供一个功能自动提交 Hadoop-Batch 任务,把一周前(举例)的数据按照天粒度 Rull-Up 并且 Rebuild Index,应该会在压缩存储和提升查询性能方面有很好的效果。
原文:https://www.cnblogs.com/oldtrafford/p/10301581.html