 tensorflow学习笔记2
tensorflow学习笔记2edit by Strangewx 2019.01.04
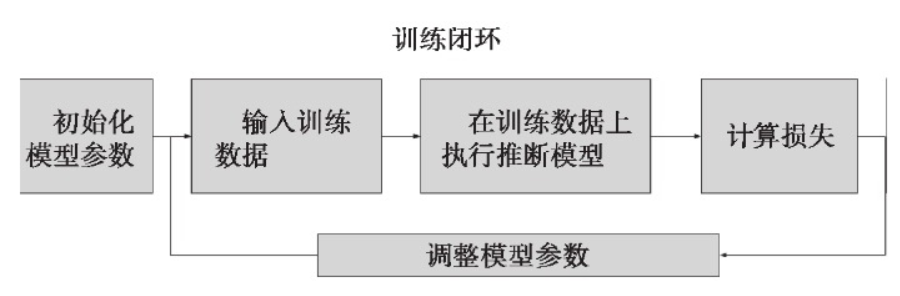
初始化模型参数:通常随机赋值,简单模型赋值0
训练数据:一般打乱。random.shuffle()
在训练数据上推断模型:得到输出
计算损失:loss(X, Y)多种损失函数
调整模型参数:最小化损失 SGD等优化方法。
评估:70%:30% 分训练集和校验集
首先模型参数初始化,
然后为每个训练闭环中的运算定义一个方法:读取训练数据input,计算推断模型inference,计算相对期望输出的损失loss,调整模型参数train,评估训练模型evaluate,
之后启动一个Session会话对象,并进行闭环训练。
模型满意之后,导出模型,用它对所需要的数据进行推断,例如:为冰激凌App用户推荐不同口味的冰激凌。
import tensorflow as tf
?
#初始化变量和模型参数,定义训练闭环中的运算
?
def inference(X):
#计算推断模型在数据X上的输出,并将结果返回。
?
def loss(X, Y):
#依据训练数据X和期望输出Y计算损失
def inputs():
#读取或生成训练数据X,期望输出Y
def train(total_loss):
#依据计算的总损失,训练或调整模型参数。
def evalute(sess, X, Y):
#队训练模型进行评估
#在一个会话对象中启动数据流图,搭建流程
with tf.Session() as sess:
tf.global_variables_initializer().run()
X, Y = inputs()
total_loss = loss(X, Y)
train_op = train(total_loss)
coor = tf.train.Coordinator()
threads = tf.train.start_queue_rnners(sess=sess, coor=coord)
#实际训练迭代轮数
training_steps = 1000
for step in range(training_steps):
sess.run([train_op])
#为了调试和学习的目的,查看损失在训练过程中的变化
if step % 100 == 0:
print("loss:",sess.run([total_loss]))
evalute(sess, X, Y)
coord.request_stop()
coord.join(thread)
sess.close()
tf.train.Saver()类
目的:
将数据流图中的变量保存到专门的二进制文件中。周期性保存所有变量,创建检查点(checkpoint)文件,并在必要时从最近的检查点恢复。
每次调用tf.train.Saver.save 方法,都会创建一个 my-model-step的检查点文件,如my-model-1000,my-model-2000等。默认情况保存近5次的文件
在上述框架稍作修改:
#模型定义代码 ...
#创建一个Saver()类
saver = tf.train.Saver()
?
#在一个会话对象中启动数据流图,搭建流程
with tf.Session() as sess:
#模型设置...
#实际的闭环训练
for step in range(training_steps):
sess.run([train_op])
if step % 1000 == 0:
saver.save(sess, ‘my-model‘, global_step=step)
#模型评估。。。
#最终模型保存
saver.save(sess, ‘my-model‘, global_step=training_steps)
sess.close()
tf.train.get_checkpoint_state
验证之前是否有检查点文件被保存下来
tf.train.Saver.restore
负责恢复变量值。
#在一个会话对象中启动数据流图,搭建流程
with tf.Session() as sess:
#模型设置...
initial_step = 0
#验证之前是否存在检查点文件
ckpt = tf.train.get_checkpoint_state(os.path.dirname(__file__))
if ckpt and ckpt.model_checkpoint_path:
#从检查点恢复模型参数
saver.restore(sess, ckpt.model_checkpoint_path)
initial_step = int(ckpt.model_checkpoint_path.split(‘-‘, 1)[1])
#实际的闭环训练
for step in range(initial_step, training_steps):
#...
?
包括:一般架构,训练点保存和恢复
import tensorflow as tf
?
#初始化变量和模型参数,定义训练闭环中的运算
?
def inference(X):
#计算推断模型在数据X上的输出,并将结果返回。
?
def loss(X, Y):
#依据训练数据X和期望输出Y计算损失
def inputs():
#读取或生成训练数据X,期望输出Y
def train(total_loss):
#依据计算的总损失,训练或调整模型参数。
def evalute(sess, X, Y):
#队训练模型进行评估
#--checkpoint--创建一个Saver()类
saver = tf.train.Saver()
?
#在一个会话对象中启动数据流图,搭建流程
with tf.Session() as sess:
tf.global_variables_initializer().run()
X, Y = inputs()
total_loss = loss(X, Y)
train_op = train(total_loss)
coor = tf.train.Coordinator()
threads = tf.train.start_queue_rnners(sess=sess, coor=coord)
#--checkpoint恢复--
initial_step = 0
#验证之前是否存在检查点文件
ckpt = tf.train.get_checkpoint_state(os.path.dirname(__file__))
if ckpt and ckpt.model_checkpoint_path:
#从检查点恢复模型参数
saver.restore(sess, ckpt.model_checkpoint_path)
initial_step = int(ckpt.model_checkpoint_path.split(‘-‘, 1)[1])
#实际训练迭代轮数
training_steps = 10000
for step in range(initial_step, training_steps):
sess.run([train_op])
#为了调试和学习的目的,查看损失在训练过程中的变化
if step % 100 == 0:
print("loss:",sess.run([total_loss]))
#--checkpoint--每1000次保存训练检查点
if step % 1000 == 0:
saver.save(sess, ‘my-model‘, global_step=step)
evalute(sess, X, Y)
#--checkpoint--最终模型保存
saver.save(sess, ‘my-model‘, global_step=training_steps)
coord.request_stop()
coord.join(thread)
sess.close()
Y=XW + b
实例:脂肪含量和年龄,体重的关系。
代码:
import tensorflow as tf
import numpy as np
?
#初始化变量和模型参数
W = tf.Variable(tf.zeros([2,1]), name="weights")
b = tf.Variable(0., name="bias")
?
#定义闭环训练的方法
def inference(X):
return tf.matmul(X, W) + b
?
def loss(X, Y):
#此处采用均方误差
Y_predicted = inference(X)
return tf.reduce_sum(tf.squared_difference(Y, Y_predicted))
def inputs():
#体重年龄
weight_age = [[84, 46], [73, 20], [65, 52], [70, 30],[76, 57],
[69, 25], [63, 28], [72, 36], [79, 57], [75, 44],
[27, 24], [89, 31], [65, 52], [57, 23], [59, 60],
[69, 48] ,[60, 34], [79, 51], [75, 50], [82, 34],
[59, 46], [67, 23],[85, 37], [55, 40], [63, 30]]
#血脂含量
blood_fat_content = [354, 190, 405, 263, 451, 302, 288,385, 402,
365, 209, 290, 346, 254, 395, 434, 220, 374,
308,220, 311, 181, 274, 303, 244]
?
return tf.to_float(weight_age), tf.to_float(blood_fat_content)
?
def train(total_loss):
learning_rate = 0.0000001
return tf.train.GradientDescentOptimizer(learning_rate).minimize(total_loss)
?
def evaluate(sess, X, Y):
print(sess.run(inference([[80., 25.]])))
print(sess.run(inference([[65., 25.]])))
print(sess.run(inference([[84., 46.]])))
?
with tf.Session() as sess:
tf.global_variables_initializer().run()
X, Y = inputs()
total_loss = loss(X, Y)
train_op = train(total_loss)
?