| The First Column | The Second Column |
|---|---|
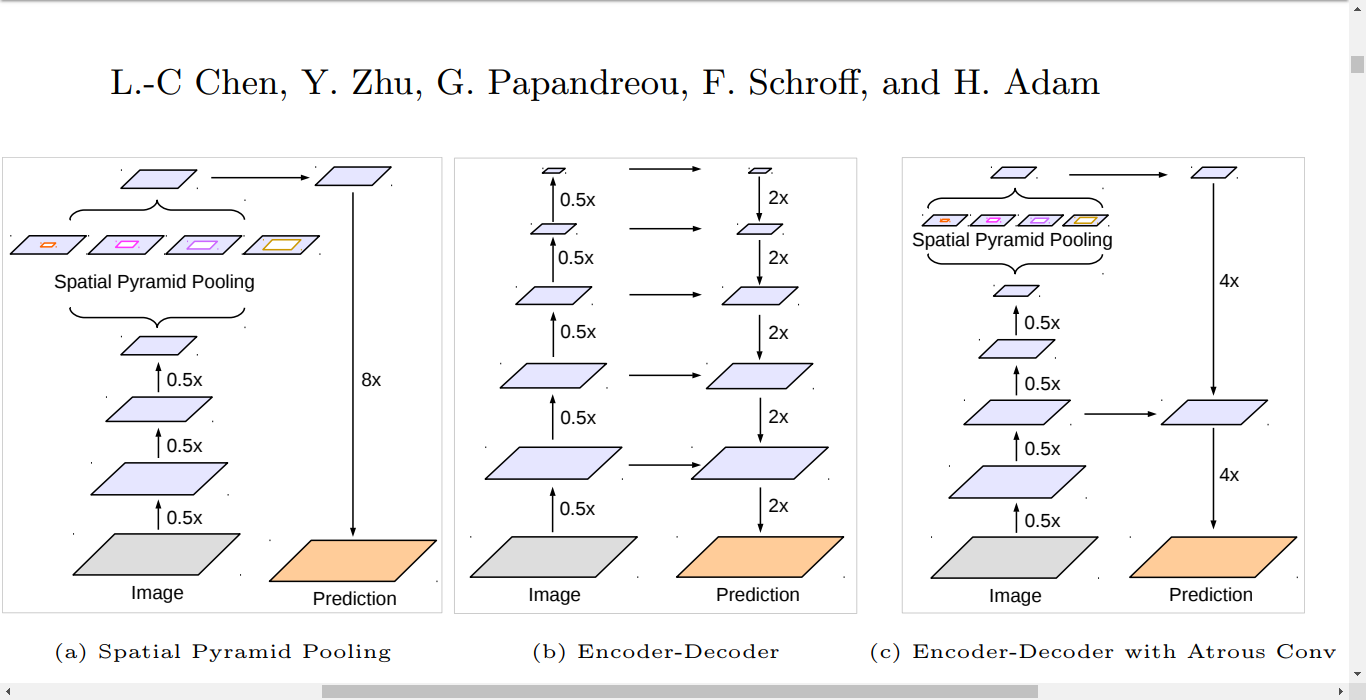
| Fig 1. SPP、 Encoder-Decoder 和 Encoder-Decoder with Atrous Conv(DeepLabV3+ ) 网络结构对比. 深度可分离卷积 结构(depthwise separable convolution) 和 group convolution 能够有效降低计算量 与参数量,同时 保持模型表现. |
 |
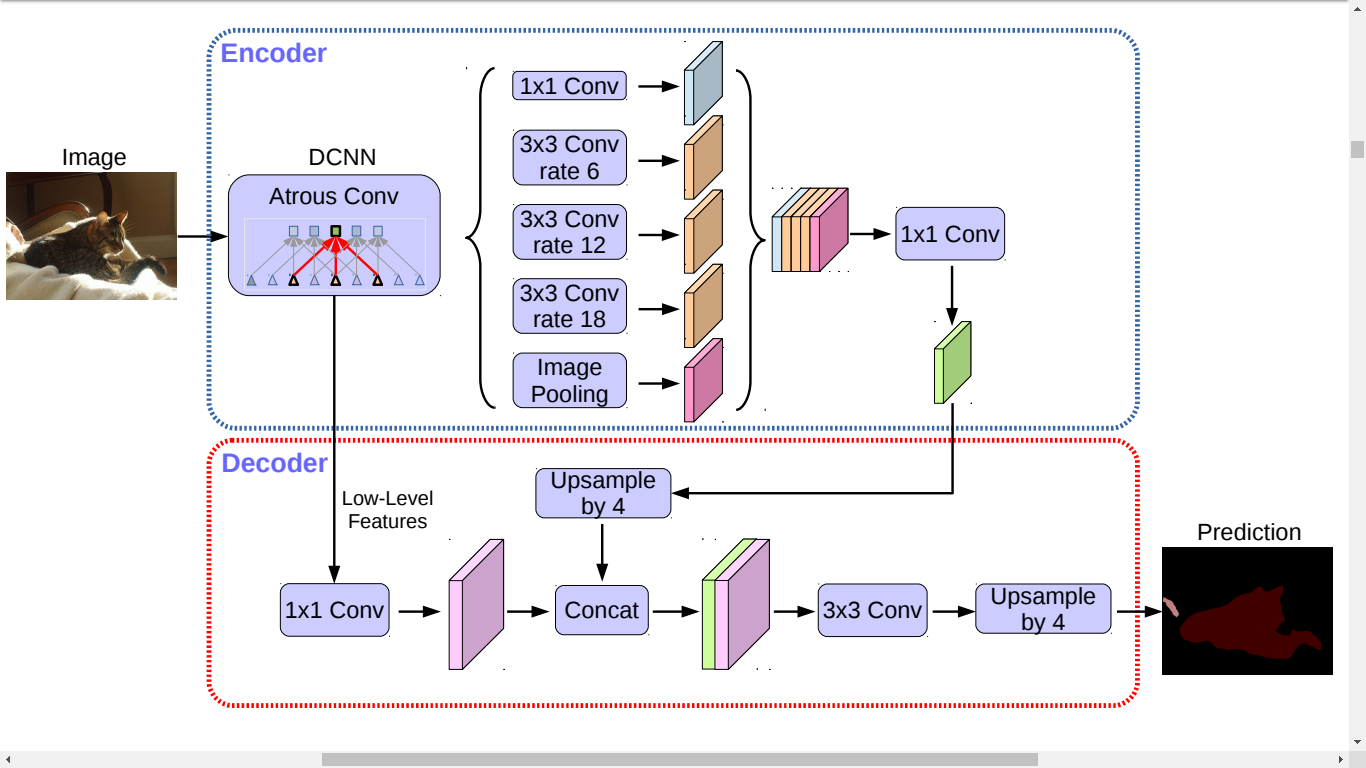
| DeepLabV3 中的 对 feature map 采用因子为 16 的双线性插值 (bilinearly upsampled)处理, 可以看做是 naive 的解码模块,但不足 以重构物体分割细节 .DeepLabV3+ 提出 的解码模块,如图 |
 |
 |
原文:https://www.cnblogs.com/hugeng007/p/10328405.html