Evernote Export
文件和数据描述
train.csv训练数据集包括:
测试集 test.csv

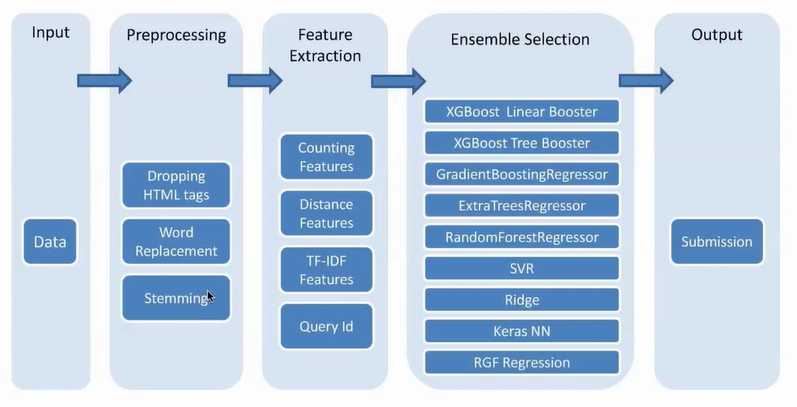
| package | model | model_select | feature | weighting |
|---|---|---|---|---|
| XGBoost | gblinear | MSE | High/Low | Yes |
| XGBoost | gblinear | COCR | High/Low | Yes |
| XGBoost | gblinear | Softmax | High/Low | Yes |
| XGBoost | gblinear | Softkappa | High/Low | Yes |
| XGBoost | gbtree | MSE | Low | Yes |
| XGBoost | gbtree | COCR | Low | Yes |
| XGBoost | gbtree | Softmax | Low | Yes |
| XGBoost | gbtree | Softkappa | Low | Yes |
| Sklearn | GradientBoostingRegressor | Low | Yes | |
| Sklearn | ExtraTreeRegressor | Low | Yes | |
| Sklearn | RandomForestRegressor | Low | Yes | |
| Sklearn | SVR | Low | Yes | |
| Sklearn | Ridge | High/Low | No | |
| Sklearn | Lasso | High/Low | No | |
| Sklearn | LogisticRegression | High/Low | No | |
| Keras | NN Regression | Low | No | |
| RGF | Regression | Low | No |
**集成学习:**是目前机器学习的一大热门方向,所谓集成学习简单理解就是指采用多个分类器对数据进行预测,从而提高整体分类器的泛化能力
三种常见框架:bagging、boosting、stacking
bagging:决定用某一种类型的分类器的时候,通过抽样的方法抽样出不同的子训练集(自助抽样)
boosting:选择基模型数据集,由基模型(弱模型)等根据权重的方式集成为强模型
stacking:堆叠集成学习方式,底层基模型不断训练给上层的模型进行预测
Bias 方差与偏差
岭回归是有偏的,但是方差结果显示更好
bagging公式
E(F)=γ?i∑m?E(fi?)=σ2?ρ+mσ2?(1?ρ)?
boosting的偏差与方差
E(F)=γ?i∑m?E(fi?)=m2?γ2?σ2
1.剔除HTML标签
1.词频数目统计
自然状态码:000,001,010,011,100,101
独热编码:000001,000010,000100,001000,010000,100000
距离特征:Jaccard coeffcient JaccardCoef(A,B)=∣A?B∣∣A?B∣?
Dice distance DiceDist(A,B)=∣A∣+∣B∣2∣A?B∣?
基本距离特征:
- D(ngram(qi?,n),ngram(ti?,n))
- D(ngram(qi?,n),ngram(di?,n))
- D(ngram(ti?,n),ngram(ti?,n))
统计距离特征
1.根据查询或者其他中位数等进行分组
Gr?=i∣ri?=r
Gq?,r=i∣qi?=q,ri?=r
其中q?qi?r?1,2,3,4
2.对于每一个样本计算一堆距离
Si?,r,n=D(ngram(ti?,n),ngram(tj?,n)∣j?Gr?,j?=i)
SQi?,r,n=D(ngram(ti?,n),ngram(tj?,n)∣j?Gq?,r,j?=i)
其中 r?1,2,3,4D(?,?)?JaccardCoef(?,?),DiceDist(?,?)
3.对于Si?,r,n和SQi?,r,n来说需要计算的值有
最小值
中位数(2分位)
最大值
平均值
标准差
其他评估标准
原文:https://www.cnblogs.com/pandaboy1123/p/10365235.html
