数据结构:数据用什么样的方式组合在一起。
数据存储的常用结构有:栈、队列、数组、链表和红黑树。
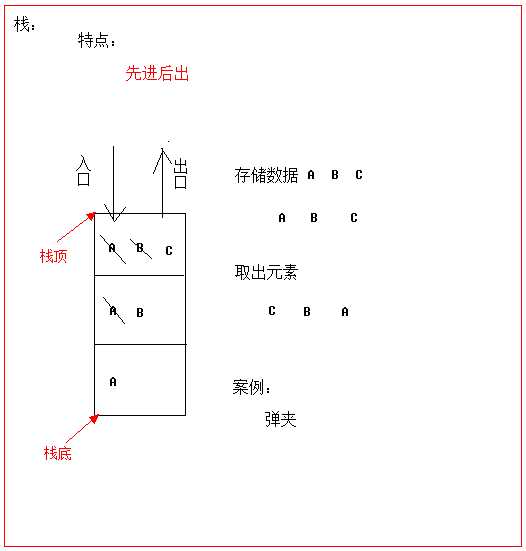
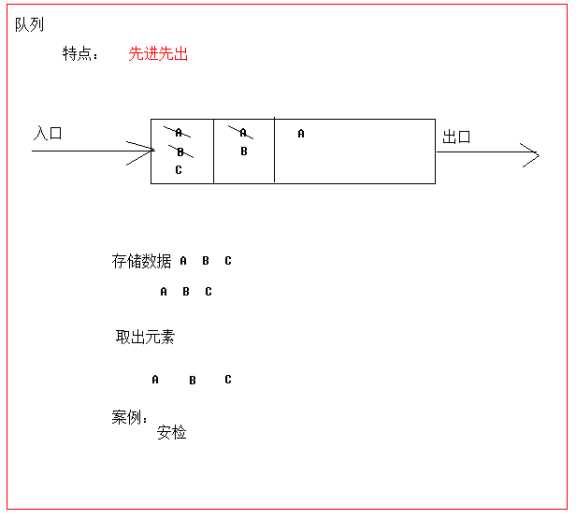
简单来说:采用该结构的集合,对元素的存取有如下的特点。
当开枪的时候,先弹出上面的子弹,然后才弹出下面的子弹。
这里需要理解两个名词:
public class MyStack {
private int[] array;
private int size;
private int top;
public MyStack(int size){
this.size = size;
array = new int[size];
top = -1;
}
//压栈
public void push(int value){
if(top < size-1){
array[++top] = value;
}
}
//弹栈
public int pop(){
return array[top--];
}
//获取栈顶数据
public int getTop(){
return array[top];
}
//判断栈是否为空
public boolean isEmpty(){
return (top == -1);
}
//判断栈是否满了
public boolean isFull(){
return (top == size-1);
}
}
代码测试:
public class Test {
public static void main(String[] args) {
MyStack stack = new MyStack(3);
stack.push(3);
stack.push(2);
stack.push(1);
System.out.println(stack.getTop());
while(!stack.isEmpty()){
System.out.println(stack.pop());
}
}
}
结果:
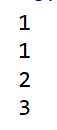



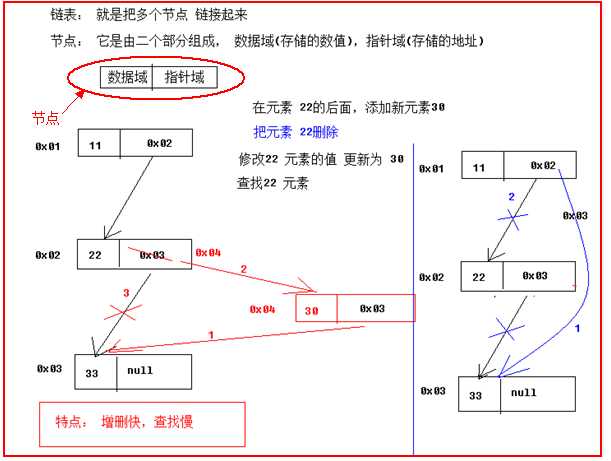
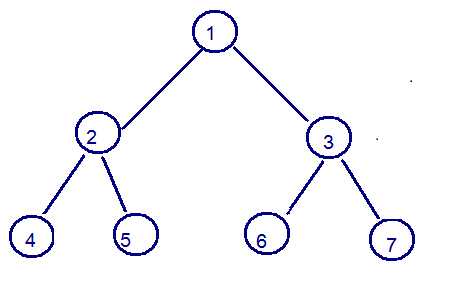
我们
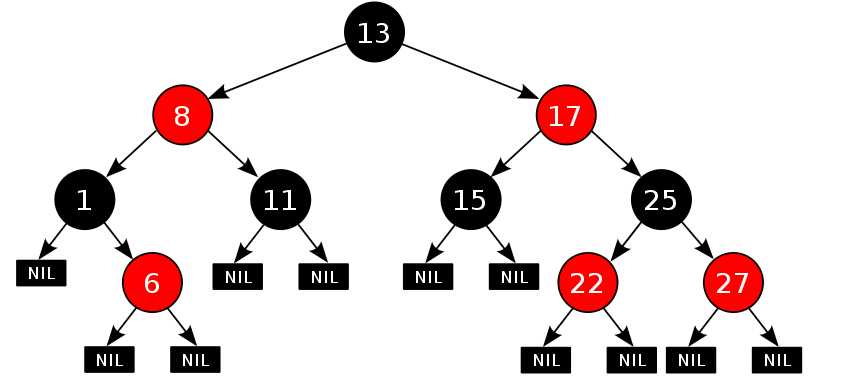
红黑树可以通过红色节点和黑色节点尽可能的保证二叉树的平衡,从而来提高效率。
什么是哈希表?
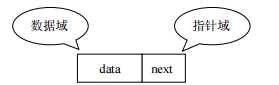
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用数组处理冲突,同意hash值的链表都存储在一个数组内。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下图所示。
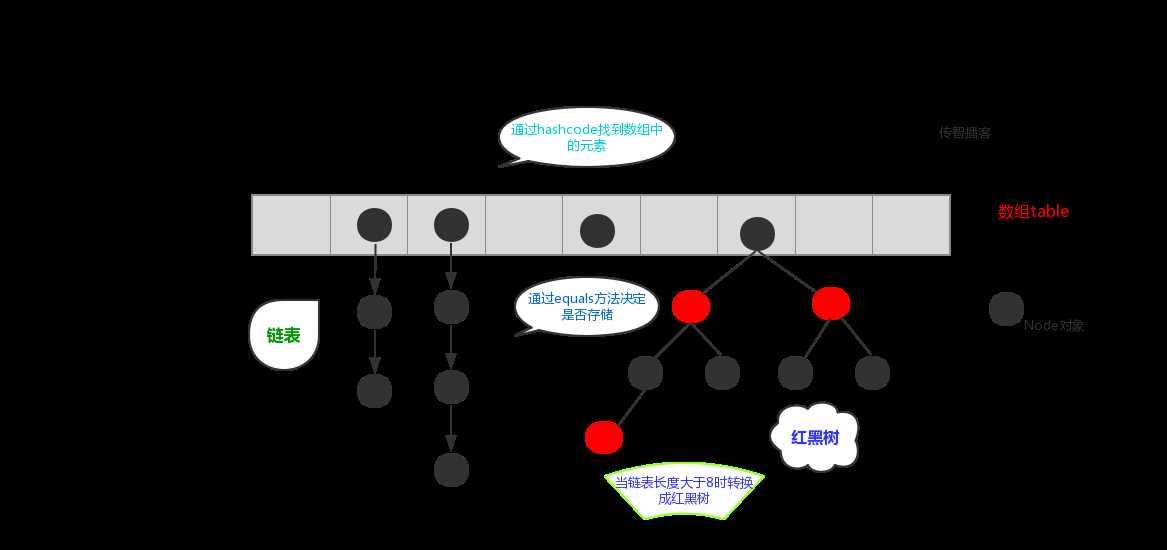
为了方便理解可以结合一个存储流程图来说明一下:
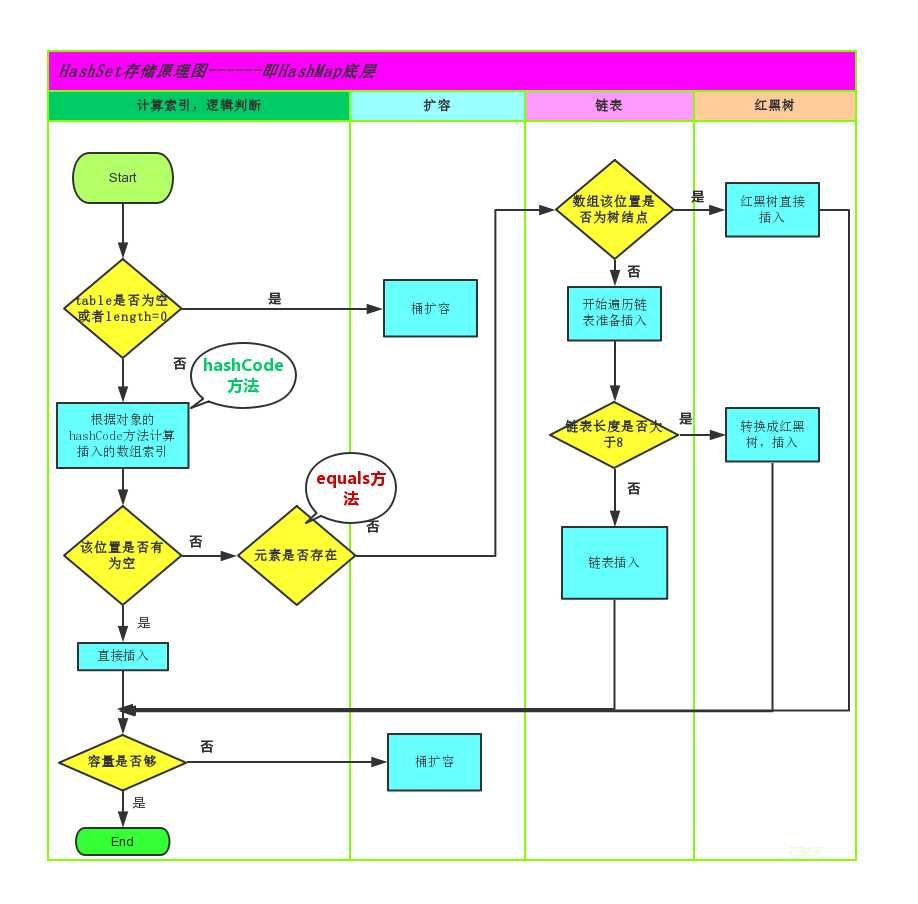
// 创建自定义学生类
public class Student {
private int age;
private String name;
private double score;
public Student() {
}
public Student(int age, String name, double score) {
this.age = age;
this.name = name;
this.score = score;
}
// 重写equal和hashCode方法,
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (!(o instanceof Student)) return false;
Student student = (Student) o;
return getAge() == student.getAge() &&
Double.compare(student.getScore(), getScore()) == 0 &&
Objects.equals(getName(), student.getName());
}
@Override
public int hashCode() {
return Objects.hash(getAge(), getName(), getScore());
}
// 重写toString方法
@Override
public String toString() {
return "Student{" +
"age=" + age +
", name=‘" + name + ‘\‘‘ +
", score=" + score +
‘}‘+"\n";
}
// get, set 方法省略。
创建测试类:
public class Demo15 {
public static void main(String[] args) {
// 创建HashSet集合,接收自定义类型数据。
HashSet<Student> hs = new HashSet<>();
Student s1 = new Student(19,"王小石",99.2);
Student s2 = new Student(20,"雷纯",99.4);
Student s6 = new Student(23,"戚少商",99.8);
Student s3 = new Student(21,"温柔",99.6);
Student s4 = new Student(22,"白愁飞",99.1);
Student s5 = new Student(23,"戚少商",99.8);
// 将数据添加到HashSet集合当中。
hs.add(s1);
hs.add(s2);
hs.add(s3);
hs.add(s4);
hs.add(s5);
hs.add(s6);
System.out.println(hs);
结果:

原文:https://www.cnblogs.com/XJP-now/p/10367622.html