如何加载/保存原模型?fine-tune如何实践?如何实践transfer-learning ?
当前我的答案:https://cv-tricks.com/tensorflow-tutorial/save-restore-tensorflow-models-quick-complete-tutorial/
两个先修实践练习:(1) https://cv-tricks.com/artificial-intelligence/deep-learning/deep-learning-frameworks/tensorflow/tensorflow-tutorial/
帮助别人,回答别人比较尖锐的问题的过程中,学到的东西还是很多的,搜索的过程中,总能得到意外的收获
回到上面张凯旭这个问题:
1-如何加载/保存原模型?
目前tf(1.8)每次保存模型其实分三个文件:xxx.meta, xxx.index, xxx.data-yyy

(1)xxx.meta指的是meta graph,这是一个 protocol buffer,保存了完整的 Tensorflow 图,即所有变量、操作和集合等。(2)xxx.index和xxx.data-yyy都是一个二进制文件包含了所有权重、偏置、梯度和其他变量的值。
并且多次保存最终形成一个checkpoint文件
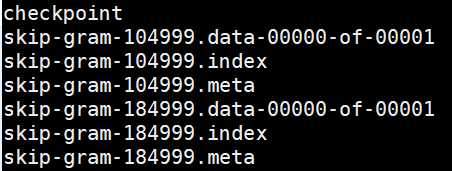
查看其内容:保存有最近若干个step保存的ckpt name,并且默认最后一次保存的ckpt为系统重新加载的model:

所以最终保存有两类信息:graph和value of variables.
import tensorflow as tf
w1 = tf.Variable(tf.random_normal(shape=[2]), name='w1')
w2 = tf.Variable(tf.random_normal(shape=[5]), name='w2')
saver = tf.train.Saver()
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# saver.save(sess, 'my_test_model')
saver.save(sess, 'my_test_model',global_step=1000) # 这种更常见,带上step
# 一些特殊设置
#saves a model every 2 hours and maximum 4 latest models are saved.
# saver = tf.train.Saver(max_to_keep=4, keep_checkpoint_every_n_hours=2)
# This will save following files in Tensorflow v >= 0.11
# my_test_model-1000.data-00000-of-00001
# my_test_model-1000.index
# my_test_model-1000.meta
# checkpoint2-如何加载预训练的模型
# 1-加载网络结构
saver = tf.train.import_meta_graph('my_test_model-1000.meta') # 将定义在.meta的网络导入到当前图中,但还没有参数值
# 2-加载参数
saver.restore(sess, tf.train.latest_checkpoint('./'))
# 总结一下:
with tf.Session() as sess:
new_saver = tf.train.import_meta_graph('my_test_model-1000.meta')
new_saver.restore(sess, tf.train.latest_checkpoint('./'))
# 再举个例子:
with tf.Session() as sess:
saver = tf.train.import_meta_graph('my-model-1000.meta') # 假设这里面有w1,w2
saver.restore(sess,tf.train.latest_checkpoint('./'))
print(sess.run('w1:0')) # 现在w1在当前sess可使用,直接使用即可
##Model has been restored. Above statement will print the saved value of w1.创建model A:
import tensorflow as tf
#Prepare to feed input, i.e. feed_dict and placeholders
w1 = tf.placeholder("float", name="w1")
w2 = tf.placeholder("float", name="w2")
b1= tf.Variable(2.0,name="bias")
feed_dict ={w1:4,w2:8}
#Define a test operation that we will restore
w3 = tf.add(w1,w2)
w4 = tf.multiply(w3,b1,name="op_to_restore")
sess = tf.Session()
sess.run(tf.global_variables_initializer())
#Create a saver object which will save all the variables
saver = tf.train.Saver()
#Run the operation by feeding input
print sess.run(w4,feed_dict)
#Prints 24 which is sum of (w1+w2)*b1
#Now, save the graph
saver.save(sess, 'my_test_model',global_step=1000)
##############################################################################
# 与上面那段程序无关,
# 是科普:如何基于graph来获取graph中的variable/Tensor/placeholders
#How to access saved variable/Tensor/placeholders
# 先获取graph: e.g. graph = tf.get_default_graph()
w1 = graph.get_tensor_by_name("w1:0")
## How to access saved operation
op_to_restore = graph.get_tensor_by_name("op_to_restore:0")restore A 并且 重新使用new_input做prediction:
import tensorflow as tf
sess=tf.Session()
#First let's load meta graph and restore weights
saver = tf.train.import_meta_graph('my_test_model-1000.meta')
saver.restore(sess,tf.train.latest_checkpoint('./'))
# Now, let's access and create placeholders variables and
# create feed-dict to feed new data
graph = tf.get_default_graph()
w1 = graph.get_tensor_by_name("w1:0")
w2 = graph.get_tensor_by_name("w2:0")
feed_dict ={w1:13.0,w2:17.0} # new_input,用来做prediction
#Now, access the op that you want to run.
op_to_restore = graph.get_tensor_by_name("op_to_restore:0")
print sess.run(op_to_restore,feed_dict)
#This will print 60 which is calculated
#using new values of w1 and w2 and saved value of b1restore A 然后 fine-tune A
import tensorflow as tf
sess=tf.Session()
#First let's load meta graph and restore weights
saver = tf.train.import_meta_graph('my_test_model-1000.meta')
saver.restore(sess,tf.train.latest_checkpoint('./'))
# Now, let's access and create placeholders variables and
# create feed-dict to feed new data
graph = tf.get_default_graph()
w1 = graph.get_tensor_by_name("w1:0")
w2 = graph.get_tensor_by_name("w2:0")
feed_dict ={w1:13.0,w2:17.0}
#Now, access the op that you want to run.
op_to_restore = graph.get_tensor_by_name("op_to_restore:0")
#Add more to the current graph
add_on_op = tf.multiply(op_to_restore,2) # 这是相比A新增的一个op
print sess.run(add_on_op,feed_dict)
#This will print 120. # 相当于在最后一个op后面再接一个op,其实在A任何地方都是可以修改的# 部分代码,有时间再改为完整的真实代码
# ......
# ......
saver = tf.train.import_meta_graph('vgg.meta')
saver.restore(sess,tf.train.latest_checkpoint('./')) # 加载预训练好的一组变量值
# Access the graph
graph = tf.get_default_graph()
## Prepare the feed_dict for feeding data for fine-tuning
#Access the appropriate output for fine-tuning
fc7= graph.get_tensor_by_name('fc7:0')
#use this if you only want to change gradients of the last layer
fc7 = tf.stop_gradient(fc7) # It's an identity function
fc7_shape= fc7.get_shape().as_list()
new_outputs=2
weights = tf.Variable(tf.truncated_normal([fc7_shape[3], num_outputs], stddev=0.05))
biases = tf.Variable(tf.constant(0.05, shape=[num_outputs]))
output = tf.matmul(fc7, weights) + biases
pred = tf.nn.softmax(output)
# Now, you run this with fine-tuning data in sess.run()
# 定义loss, 然后train_op, 然后run(train_op)进行bphttps://cv-tricks.com/tensorflow-tutorial/save-restore-tensorflow-models-quick-complete-tutorial/
两个先修实践练习:
原文:https://www.cnblogs.com/LS1314/p/10371171.html