优点:
 ?
?
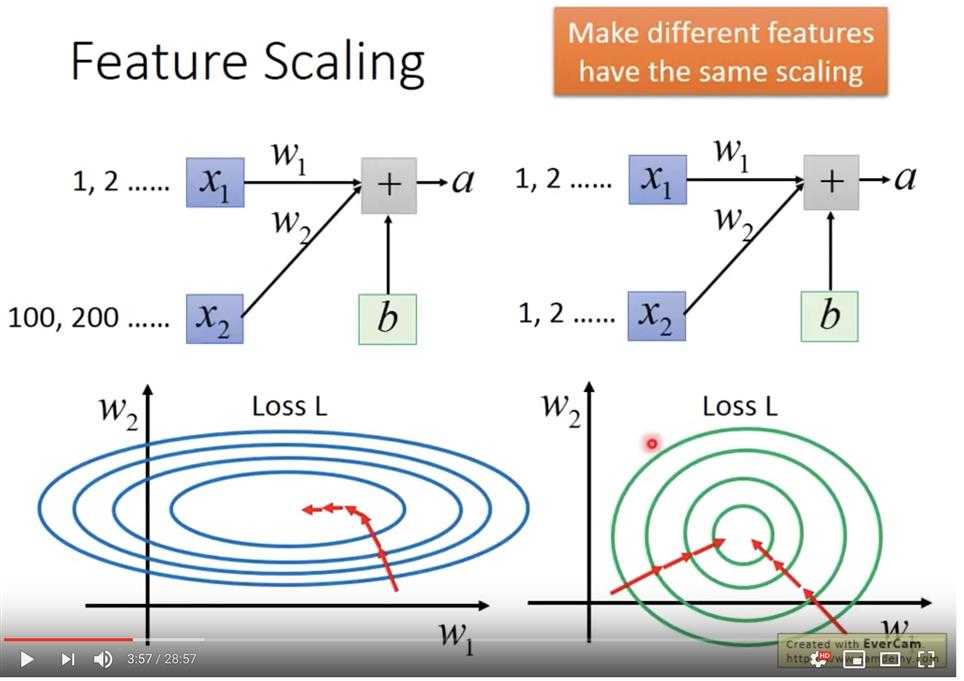
若不对输入数据作scaling,数据的量级差异会有以下麻烦:
所以将输入数据scale之后得到圆形的loss,将会容易train很多。
 ?
?
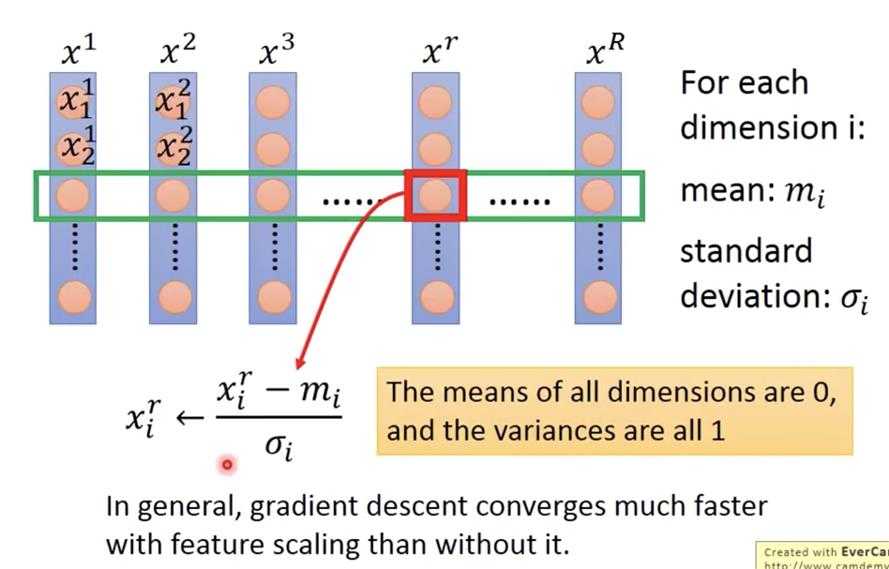
很简单,直接在每一个维度中求得各自的mean和std,然后再将每一个数据进行normalized。
 ?
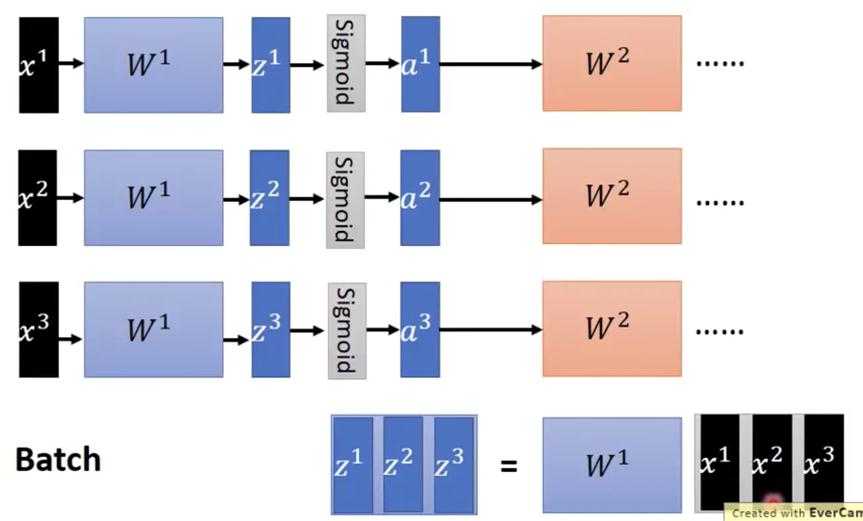
?先说一下GPU为什么比CPU快, GPU每次进行运算是将所有的输入vector(以batch为单位打包)打包成matrix,再进行matrix平行运算。
 ?
?
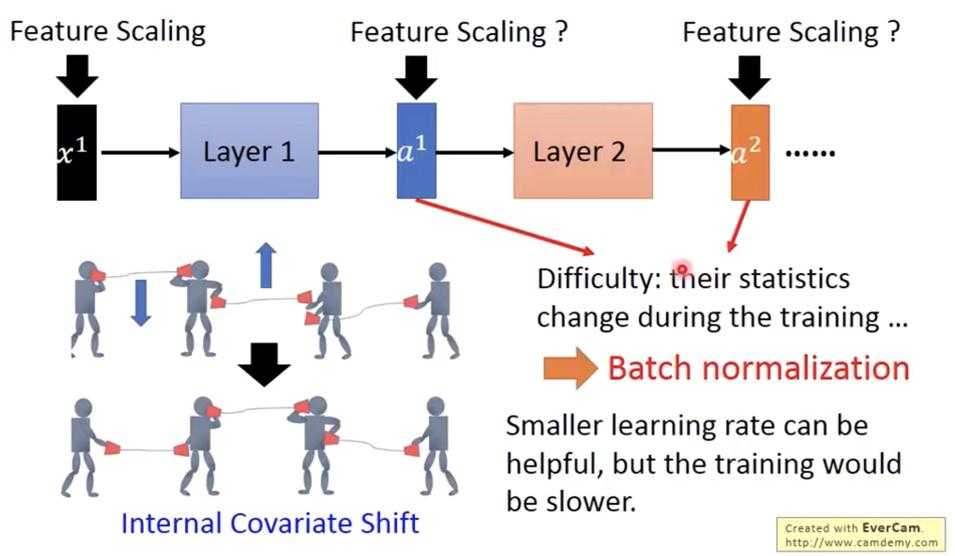
通常是将经过线性变换W之后,进入activation之前进行normalized,原因是因为activation通常都有situation area,如果input落在这个area就会出现梯度消失(gradient vanished)的问题。所以我们比较希望input落在零的附近,即梯度比较大的地方。
而进行normalized的时候,由于W是变化的,如果用整体数据来算每一次layer输入的normalized,计算量巨大,不切实际。因此就把数据切为小份,进行batch normalization。而由大数定理可知,要使得计算每一次的mean 和std都比较准确,都需要比较大量的数据,因此batch不能太小.
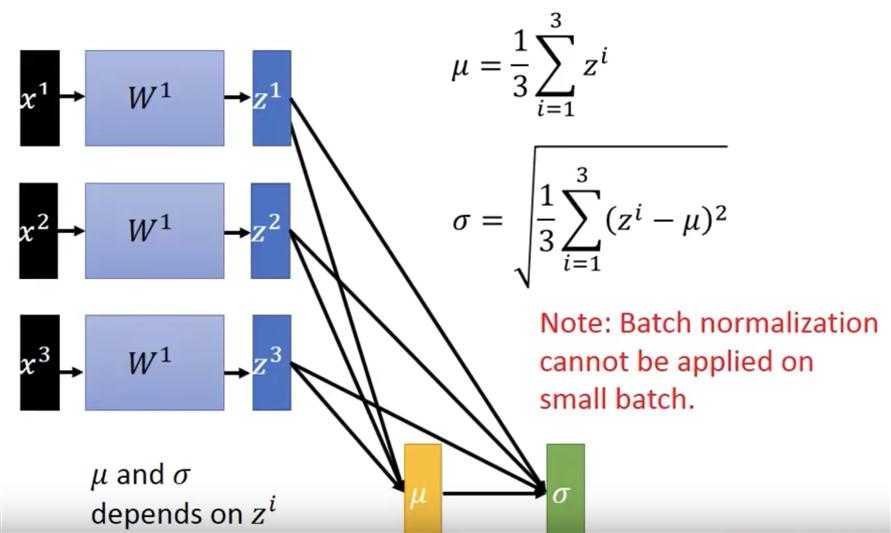 ?
?
因此如果用了BN,在BP的时候还要考虑mean和std,因此BP考虑的是整个batch 数据,而不是传统的单个数据。所以打印torch的model参数会出现running_mean和running_var。
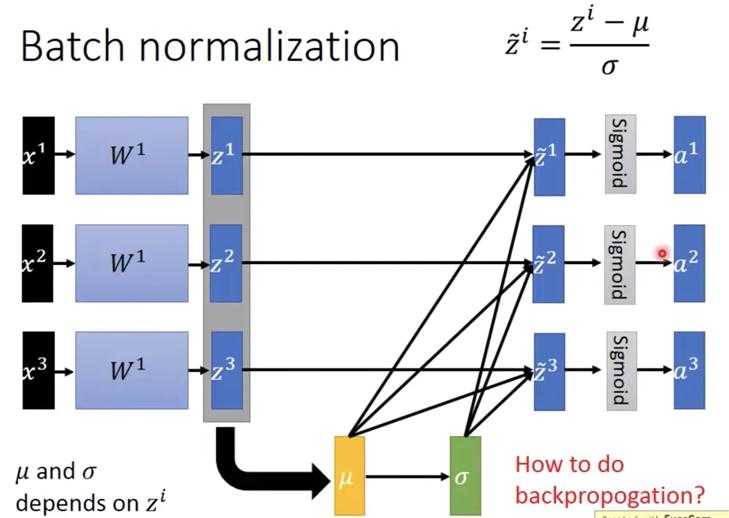 ?
?
如果某些activation要求输入数据的Mean和std的不是0和1,可以再加一层线性变换\beta和/gamma,这两个参数也是网络自己学出来的。(有的人会有疑问如果beta等于mean,gamma等于std的时候,输入到activation的数据不就是原本的数据了吗?首先这种巧合不太可能。其次在这里beta和gamma是自己学出来的,与输入数据没有直接关系,而mean和theta是与输入数据有直接关系的)
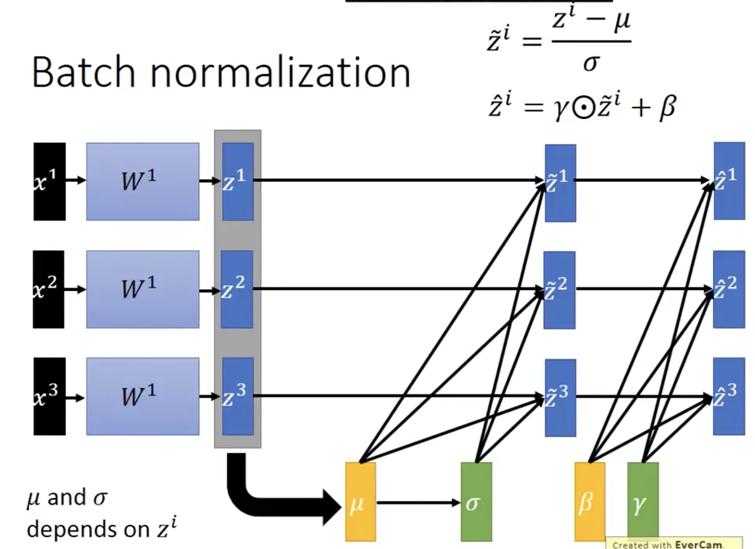 ?
?
Test Stage
由于testing的时候不是batch test的,所以无法计算test的输入数据normalized。
1) 一个理想的方案:因为已经train完了,所以可以直接用所有数据输入到网络计算每一层的mean和std。但又有问题:数据量太大则无法进行。
2) 一个可行的方案:每次计算mean的时候都保存起来,再求mean的mean,继而求std。但因为train的时候,由于weight在不断变化,mean的也在变化,因此越后期的mean越为准确。所以计算mean的mean时,可以给更大的权重给后期的mean。
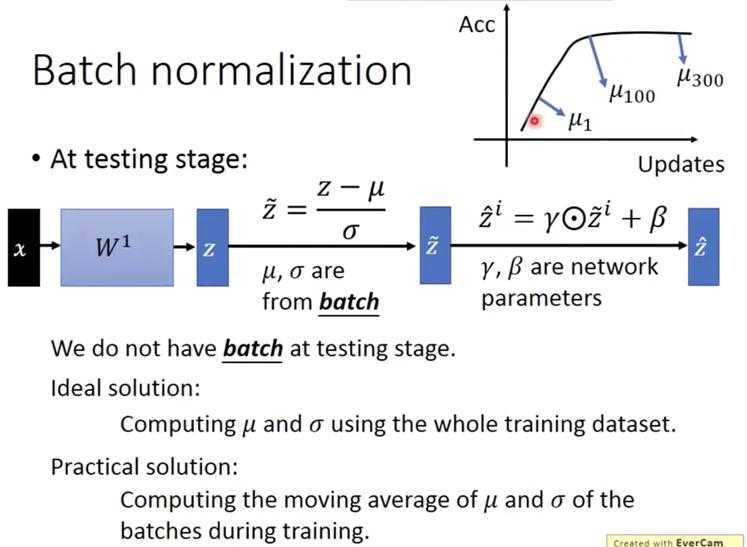 ?
?
 ?
?
 ?
?
 ?
?
https://pytorch.org/docs/stable/nn.html#batchnorm2d
感谢李宏毅老师的视频讲解。链接:https://www.youtube.com/watch?v=BZh1ltr5Rkg
原文:https://www.cnblogs.com/bourne_lin/p/Batch-Normalization.html