1、背景
MGR是个好东西,因为他从本质上解决了数据不一致的问题。不光是解决了问题,而且出自名门正派(Oracle的MySQL团队),对品质和后续的维护,我们是可以期待的。
但是在调研的过程中,发现有个严重的bug(https://bugs.mysql.com/bug.php?id=92690),在网络有延迟、丢包和数据损坏时,会导致各个节点间数据严重不一致。而上述网络情况,在跨地域部署时候,出现的概率还是比较高的,因此,必须解决上述问题。我也一直在等待官方团队的修复(该bug在2018年11月5号被提出,截止到写作这篇文章,已经3个月了),但是一直没有bug fix放出。
2、社区对于该bug的分析
a)相同gtid编号,内容不同
从这个bug submmiter的分析来看,即使是相同的gtid编号,其内容也不相同,甚至操作的表都不一样。
gr01 > show binlog events in ‘binlog.000223‘ from 11590 limit 11; +---------------+-------+-------------+-----------+-------------+------------------------------------------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +---------------+-------+-------------+-----------+-------------+------------------------------------------------------------------------+ | binlog.000223 | 11590 | Gtid | 10 | 11651 | SET @@SESSION.GTID_NEXT= ‘aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:295533‘ | | binlog.000223 | 11651 | Query | 10 | 11723 | BEGIN | | binlog.000223 | 11723 | Table_map | 10 | 11775 | table_id: 125 (db1.sbtest6) | | binlog.000223 | 11775 | Update_rows | 10 | 12185 | table_id: 125 flags: STMT_END_F | | binlog.000223 | 12185 | Table_map | 10 | 12237 | table_id: 116 (db1.sbtest5) | | binlog.000223 | 12237 | Update_rows | 10 | 12647 | table_id: 116 flags: STMT_END_F | | binlog.000223 | 12647 | Table_map | 10 | 12699 | table_id: 118 (db1.sbtest1) | | binlog.000223 | 12699 | Delete_rows | 10 | 12919 | table_id: 118 flags: STMT_END_F | | binlog.000223 | 12919 | Table_map | 10 | 12971 | table_id: 118 (db1.sbtest1) | | binlog.000223 | 12971 | Write_rows | 10 | 13191 | table_id: 118 flags: STMT_END_F | | binlog.000223 | 13191 | Xid | 10 | 13218 | COMMIT /* xid=6231928 */ | +---------------+-------+-------------+-----------+-------------+------------------------------------------------------------------------+ 11 rows in set (0.00 sec) gr02 > show binlog events in ‘binlog.000221‘ from 9912 limit 11; +---------------+-------+-------------+-----------+-------------+------------------------------------------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +---------------+-------+-------------+-----------+-------------+------------------------------------------------------------------------+ | binlog.000221 | 9912 | Gtid | 10 | 9973 | SET @@SESSION.GTID_NEXT= ‘aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:295533‘ | | binlog.000221 | 9973 | Query | 10 | 10037 | BEGIN | | binlog.000221 | 10037 | Table_map | 10 | 10089 | table_id: 108 (db1.sbtest5) | | binlog.000221 | 10089 | Update_rows | 10 | 10499 | table_id: 108 flags: STMT_END_F | | binlog.000221 | 10499 | Table_map | 10 | 10551 | table_id: 110 (db1.sbtest4) | | binlog.000221 | 10551 | Update_rows | 10 | 10961 | table_id: 110 flags: STMT_END_F | | binlog.000221 | 10961 | Table_map | 10 | 11014 | table_id: 109 (db1.sbtest10) | | binlog.000221 | 11014 | Delete_rows | 10 | 11234 | table_id: 109 flags: STMT_END_F | | binlog.000221 | 11234 | Table_map | 10 | 11287 | table_id: 109 (db1.sbtest10) | | binlog.000221 | 11287 | Write_rows | 10 | 11507 | table_id: 109 flags: STMT_END_F | | binlog.000221 | 11507 | Xid | 10 | 11534 | COMMIT /* xid=1185380 */ | +---------------+-------+-------------+-----------+-------------+------------------------------------------------------------------------+ 11 rows in set (0.00 sec)
b)相同的paxos信息编号,消息类型不同
社区内有人在MGR源码中加入日志,分析出相同编号的paxos信息,在Primary节点上是带有实际的信息(和应用相关的,比如binlog的信息),但是在Secondary节点上是空消息(noop,不会提交给应用)。因此出现了数据不一致。
c)prepare阶段出现问题
注意,这里的prepare和数据库概念无关,而是paxos中的prepare。相关概念参考这篇博客(http://mysqlhighavailability.com/the-king-is-dead-long-live-the-king-our-homegrown-paxos-based-consensus/)。下图中的Election和prepare的含义是一样的。
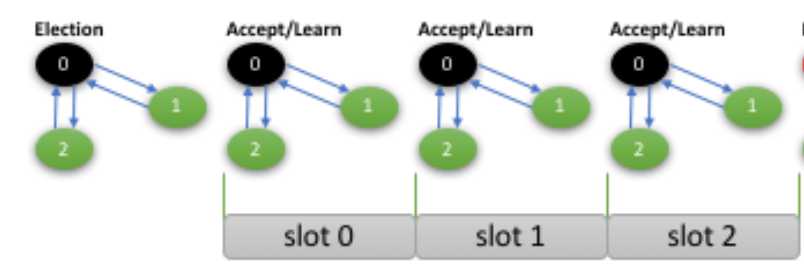
简要来说,任何一个节点在发送一个消息的时候,
1)先发送prepare消息,以确定其要发起提议的值;
2)根据上一步的结果,发送accept信息到各个参与节点;
3)如果收到多数派的回应,则发送learn信息,如果其他节点(比如节点1)收到learn信息,则消息的值,(在节点1)被确认了。
原文:https://www.cnblogs.com/youge-OneSQL/p/10388531.html