随着支撑的内部业务系统越来越多,向着服务化架构进化,在整个迭代过程中,会逐渐暴露出以下问题。
传统依赖于应用服务器日志等手段的排除故障原因的复杂度越来越高,传统的监控服务已经无法满足需求。
终端--> Nginx --> IIS --> Asp.net 管道 --> [数据缓存]->[HTTP调用]->[DB读写] 在以上调用链路上,我们以往勉强能从 Nginx 日志中分析出 客户端调用时长,Nginx 调用API服务时长。 但是到了应用程序代码,对于[数据缓存]->[HTTP调用]->[DB读写]等操作,变成了链路调用黑盒。
在分析整个应用调用链路,不能清晰、直观的分析展现。
Logging,Metrics 和 Tracing 有各自专注的部分。
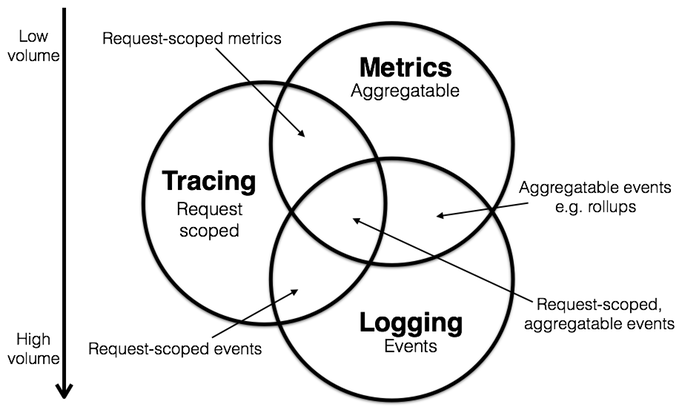
详细阅读,参考度量(Metrics),跟踪(Tracing),日志(Logging)
这三者的交集,才是对于我们分析应用程序运行状态及调用链路分析,有这直观重要的意义。
日志(Logging),可以使用ELK技术栈,解决我们的应用程序日志查询分析的大部分需求。
度量(Metrics),可以使用AppMetrics 和 Prometheus 来满足一部分需求。
跟踪(Tracing),全链路的调用分析追踪,目前解决方案大部分也是商业解决方案,如Application Insights、OneAPM、听云、Datadog等,开源方案,如SkyAPM (.net core适用)
目前,针对 .net 平台下探针的解决方案进行调研,大部分是付费,开源方案大部分针对 .net core。
有没有一种可能,我们使用开源技术,搭建自己的全链路调用分析的解决方案,这是本篇博文需要探索的议题。
我们将带着以下几个问题,进行探索解决方案
- 代码级定位性能问题
- 记录应用错误过程
- 检测慢SQL语句
- 检测外部调用API耗时
- 检测调用外部HTTP请求耗时,请求信息记录
- 请求/RPC 调用关系拓扑
OpenTracking 为监测提供了一组标准的框架无关、厂商无关的标准规范,这意味着开发者能够很方便的添加/切换跟踪系统
简单说,OpenTracking 提供了一组规范,也是分布式跟踪系统的标准的抽象,来解决不同的分布式追踪系统的API标准的不兼容问题。OpenTracing 是一个轻量级的标准化层,它位于应用程序/类库和追踪或日志分析程序之间。
更多关于 OpenTracing 数据模型的知识,请参考 OpenTracing语义标准。
分布式追踪系统,由追踪器(Tracker)、追踪信息收集代理(Agent)、追踪信息存储分析服务(APM Server)组成。
追踪器(Tracker):负责应用程序监控(代码级别执行时间、异常调用)
追踪信息收集代理(Agent):负责应用程序监控信息上报
追踪信息存储分析服务(APM Server):负责存储应用程序监控信息存储分析展示等服务
代码埋点是实现Tracker重要一步。
如果在业务代码中实现追踪埋点,不但工程量大,而且代码入侵严重。
var tracker = Tracker.Instance;
using(var context = tracker.Begin())
{
context.SetSpan("name of span");
/// some business logic
context.EndSpan();
tracker.Send(context);
}
为了实现dotnet全平台下(Framework、dotcore)追踪,我们需要清楚C#代码是如何变成机器可运行的代码。
我们只能通过,在CLR即时编译 IL之前,修改已生成的IL,来实现代码埋点。这样以来,我们便可以轻松的实现零入侵业务代码。
如何实现修改已生成的IL ? 我们通过实现CLR公共语言运行时ICorProfilerCallback 中重写JITCompilationStarted 方法即可实现。
在dotnet core 下通过DiagnosticSource 实现,应用程序性能诊断
DiagnosticSource VS EventSource
原文:https://www.cnblogs.com/yankliu-vip/p/how-to-implement-apm-tracer-on-dotnet.html