之前讲到时序差分是目前主流强化学习的基本思路,这节就学习一下主流算法之一 Sarsa模型。
Sarsa 是免模型的控制算法,是通过更新状态动作价值函数来得到最优策略的方法。
更新方法 Q(S,A)=Q(S,A)+α(R+γQ(S′,A′)?Q(S,A))
// 回归一下蒙特卡罗的更新方式 Q(S,A)=Q(S,A)+1/N(S,A)*(R+γQ(S′,A′)?Q(S,A))
// 学习率α不同,目标价值函数R+γQ(S′,A′)不同
Sarsa 算法流程
输入{S, A, R, α,γ},迭代轮数T, 探索率?
输出:所有的状态和动作对应的价值Q
1. 随机初始化所有的状态和动作对应的价值Q. 对于终止状态其Q值初始化为0.
2. for i from 1 to T,进行迭代。
a) 初始化S为当前状态序列的第一个状态。设置A为??贪婪法在当前状态S选择的动作。
b) 在状态S执行当前动作A,得到新状态S′和奖励R
c) 用??贪婪法在状态S′选择新的动作A′
d) 更新价值函数Q(S,A)
e) S=S′,A=A′
f) 如果S′是终止状态,当前轮迭代完毕,否则转到步骤b)
这里有一个要注意的是,步长α一般需要随着迭代的进行逐渐变小,这样才能保证动作价值函数Q可以收敛。当Q收敛时,我们的策略??贪婪法也就收敛了。
下面我们用一个著名的实例Windy GridWorld来研究SARSA算法。
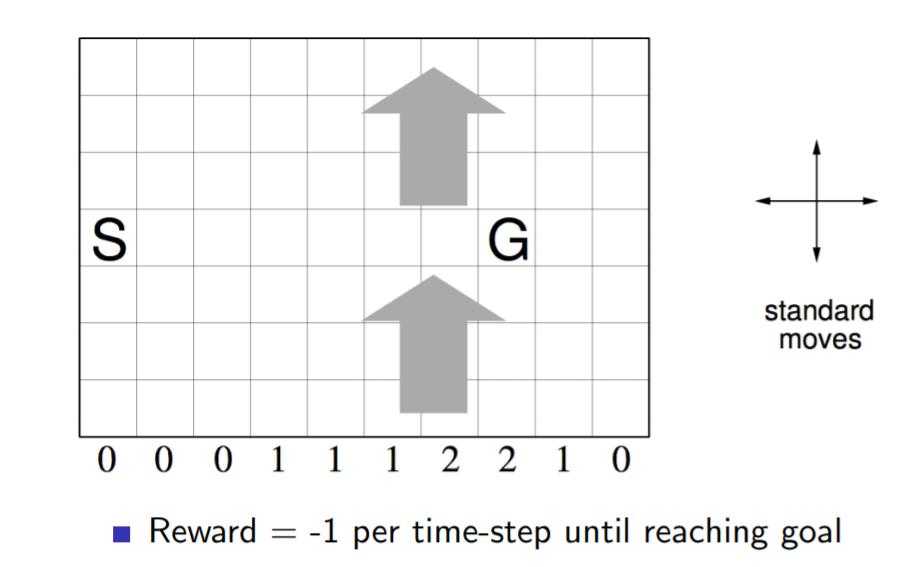
如下图一个10×7的长方形格子世界,标记有一个起始位置 S 和一个终止目标位置 G,格子下方的数字表示对应的列中一定强度的风。当个体进入该列的某个格子时,会按图中箭头所示的方向自动移动数字表示的格数,借此来模拟世界中风的作用。同样格子世界是有边界的,个体任意时刻只能处在世界内部的一个格子中。个体并不清楚这个世界的构造以及有风,也就是说它不知道格子是长方形的,也不知道边界在哪里,也不知道自己在里面移动移步后下一个格子与之前格子的相对位置关系,当然它也不清楚起始位置、终止目标的具体位置。但是个体会记住曾经经过的格子,下次在进入这个格子时,它能准确的辨认出这个格子曾经什么时候来过。格子可以执行的行为是朝上、下、左、右移动一步,每移动一步只要不是进入目标位置都给予一个 -1 的惩罚,直至进入目标位置后获得奖励 0 同时永久停留在该位置。现在要求解的问题是个体应该遵循怎样的策略才能尽快的从起始位置到达目标位置。
# encoding:utf-8 __author__ = ‘HP‘ import numpy as np world_size = [7, 10] world = np.zeros(world_size) start = [3, 0] end = [3, 7] # end = [6, 9] actions = [[-1, 0], [1, 0], [0, -1], [0, 1]] # 上下左右 alpha = 0.05 rd = 1 # 衰减因子 q = np.zeros([world_size[0] * world_size[1], len(actions)]) def get_q_x(stat): # 根据状态找到在q表中的行数 return stat[0] * world_size[1] + stat[1] def R(stat, action): # 奖励函数 if stat[0] + action[0] == end[0] and stat[1] + action[1] == end[1]: return 0 else: return -1 def stat_change(stat, action): # 无风状态转移 new_stat = [] new_x = stat[0] + action[0] if new_x < 0: new_stat.append(0) elif new_x > world_size[0] - 1: new_stat.append(world_size[0] - 1) else: new_stat.append(new_x) new_y = stat[1] + action[1] if new_y < 0: new_stat.append(0) elif new_y > world_size[1] - 1: new_stat.append(world_size[1] - 1) else: new_stat.append(new_y) return new_stat def stat_change(stat, action): # 有风状态转移 f = [0, 0, 0, -1, -1, -1, -2, -2, -1, 0] new_stat = [] new_x = stat[0] + action[0] + f[stat[1]] if new_x < 0: new_stat.append(0) elif new_x > world_size[0] - 1: new_stat.append(world_size[0] - 1) else: new_stat.append(new_x) new_y = stat[1] + action[1] if new_y < 0: new_stat.append(0) elif new_y > world_size[1] - 1: new_stat.append(world_size[1] - 1) else: new_stat.append(new_y) return new_stat def choose_max(stat): # 选择最大价值 q_stat = q[get_q_x(stat),:].tolist() max_q = max(q_stat) max_q_count = q_stat.count(max_q) if max_q_count == 1: # 最大的q只有一个 action = actions[q_stat.index(max_q)] return max_q, R(stat, action), stat_change(stat, action), action else: # 最大的q不止一个,随机选一个 indexs = [ind for ind, value in enumerate(q_stat) if value == max_q] index_choose = indexs[np.random.randint(0, len(indexs) - 1)] return q_stat[index_choose], R(stat, actions[index_choose]), stat_change(stat, actions[index_choose]), actions[index_choose] def choose(stat): # e贪心策略 if np.random.rand() > 0.3: maxq, r, stat_, action = choose_max(stat) else: index = np.random.randint(0, len(actions) - 1) q_stat = q[get_q_x(stat),:] maxq, r, stat_, action = q_stat[index], R(stat, actions[index]), stat_change(stat, actions[index]), actions[index] return maxq, r, stat_, action for i in range(10000): # 10000 轮 maxq0, r0, stat_0, action0 = choose(start) while True: stat_ = stat_change(start, action0) if stat_ == end: start = [3, 0] break maxq, r, stat__, action = choose_max(stat_) q[get_q_x(start), actions.index(action0)] += alpha * (r0 + maxq - q[get_q_x(start), actions.index(action0)]) start = stat_ action0 = action print(q) # 路径 start = [3, 0] world[start[0], start[1]] = 1 world[end[0], end[1]] = 1 while True: world[start[0], start[1]] = 1 q_stat = q[get_q_x(start),:].tolist() act = actions[q_stat.index(max(q_stat))] stat_ = stat_change(start, act) start = stat_ if stat_ == end:break print(world)

原文:https://www.cnblogs.com/yanshw/p/10408197.html