正则表达式和通配符的本质区别
2.区别通配符和正则表达式最简单的方法:
(1)文件目录名===>通配符
(2)文件内容(字符串,文本【文件】内容)===>正则表达式
注意:在匹配模式中一定要加上引号
|
符号 |
描述 |
实例 |
备注 |
|
. |
匹配任意单个字符(必须存在) |
l..e可以表示love、like、leee等,但不可以表示labcde、le、lee等。 |
cat /etc/passwd |grep “r..t” |
|
^ |
匹配前面字符串开头 |
匹配以abc开头的行:echo -e “abc\nxyz” |grep ^anc |
cat /etc/passwd |grep “^set” |
|
$ |
匹配前面字符串结尾 |
匹配以xyz结尾的行:echo -e “abc\nxyz” |grep xyz$ |
cat /etc/pssswd |grep “bash$” |
|
* |
匹配前一个字符的零个或多个 |
a*表示出现任意个a的情况 a*b表示 b前面有任意个a的情况(包括没有a的情况) |
cat /etc/passwd |grep “ro*t” 结果:既有root也有rt |
|
.* |
表示任意长度的任意字符 |
a.*b表示ab之间有无数个点(.) |
cat /etc/passwd |grep “a.*b” |
|
+(扩展正则) |
表示其前面的字符出现最少一次的情况 |
匹配 abc 和 abcc: echo -e "abc\nabcc\nadd" |grep -E ‘ab+‘ 匹配单个数字:echo "113" |grep -o ‘[0-9]‘ 连续匹配多个数字:echo "113" |grep -E -o ‘[0-9]+‘
|
|
|
?(扩展正则) |
表示其前面的字符出现最多一次的情况(可以0个) |
匹配 ac 或 abc: echo -e "ac\nabc\nadd" |grep -E ‘a?c‘
|
|
|
[] |
表示范围内的任意一个字符 |
匹配所有字母 echo -e "a\nb\nc" |grep ‘[a-z]‘
|
|
|
[^] |
匹配中括号之外的任意一个字符 |
匹配所有字母 echo -e "a\nb\nc" |grep ‘[a-z]‘
|
|
|
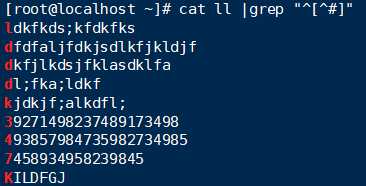
^[^] |
匹配不是中括号内任意一个字符开头的行 |
匹配不是#开头的行: grep ‘^[^#]‘ /etc/httpd/conf/httpd.conf
|
|
|
{n}或者{n,} |
匹配花括号前面字符至少n个字符 |
echo "aadadccc" | egrep "a{2}" echo "aadadccc" | egrep "a{1}"
|
|
|
{n,m} |
匹配花括号前面字符至少 n个字符,最多 m 个字符 |
"ac\{2,5\}b" 匹配a和b之间有最少2个c最多5个c的行 "ac\{,5\}b" 匹配a和b之间有最多5个c的行 "ac\{2,\}b" 匹配a和b之间有最少2个c的行
|
|
|
\< |
锚定单词首部(单词一般以空格或特殊字符做分隔) |
#echo" hi,root,iamroot" | grep "\<root" |
|
|
\> |
锚定单词尾部(单词一般以空格或特殊字符做分隔,) |
#echo "hi,root,iamroot" | grep "root\>" |
|
|
() |
\1 调用前面的第一个分组 |
例子:过滤出一行中有两个相同数字的行 # grep "\([0-9]\).*\1"
|
|
|
|(扩展正则) |
匹配竖杠两边的任意一个 |
例子:过滤出cat 或者Cat # grep "cat|Cat" a.txt # grep "(C|c)at" a.txt
|
|
注意:1.正则表达式中的{}以及()都需要加上\进行转义,而扩展正则表达式不需要。
2.|, ?,+是扩展正则独有的
3.锚定单词首部和尾部在扩展正则以及正则中都需要加上\
|
[:space:] |
匹配任意空白字符,等效\t\n\r\f\v |
注意:使用这些字符的时候需要在外面还要加一个[]括号
原文:https://www.cnblogs.com/lk99/p/10422471.html