这道题目的要求,Note: Your solution should run in O(log n) time and O(1) space.
因此应该用二分查找的方式,代码如下:
1 class Solution: 2 def singleNonDuplicate(self, nums: ‘List[int]‘) -> int: 3 l = 0 4 h = len(nums)-1 5 while l<h: 6 m = l + (h-l)//2 7 if m%2==1: 8 m-=1 9 if nums[m] == nums[m+1]: 10 l = m+2 11 else: 12 h = m 13 return nums[l]
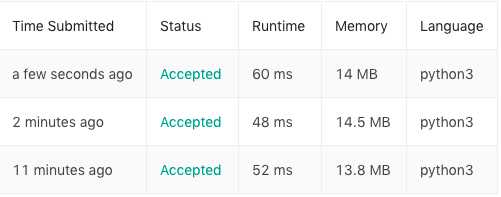
52ms,13.8mb
传统的方式,就是已经两次遍历,先遍历一遍数组,记录每一个值出现的次数,存储到一个字典中。
然后再遍历一次字典,找到只出现一次的那个值,代码如下:
1 class Solution: 2 def singleNonDuplicate(self, nums: ‘List[int]‘) -> ‘int‘: 3 count = {} 4 for num in nums: 5 count[num] = count.get(num, 0)+1 6 for key in count: 7 if count[key] == 1: 8 return key
48ms,14.5mb
这种方式想法很简单也很容易懂,但是需要额外的空间。但奇怪的是其执行时间却比二分查找的要快,感觉可能是测试集的样本问题。
还有一种技巧性比较强的方式,空间复杂度满足要求,但是时间复杂度应该更高:
1 class Solution: 2 def singleNonDuplicate(self, nums: ‘List[int]‘) -> ‘int‘: 3 res = nums[0] 4 for i in range(1,len(nums)): 5 res ^= nums[i] 6 return res
60ms,14mb
最后贴上三种方法的执行结果,从上倒下分别是第三种,第二种和第一种,这种不对称就是破除强迫症的排版(其实是我比较懒)
原文:https://www.cnblogs.com/asenyang/p/10433672.html