损失函数分为经验风险损失函数和结构风险损失函数。经验风险损失函数指预测结果和实际结果的差别,结构风险损失函数是指经验风险损失函数加上正则项。通常表示为如下:
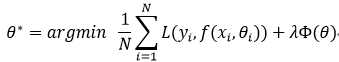
0-1损失是指,预测值和目标值不相等为1,否则为0:
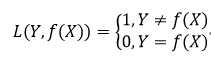

Logistic回归的损失函数就是对数损失函数,在Logistic回归的推导中,它假设样本服从伯努利分布(0-1)分布,然后求得满足该分布的似然函数,接着用对数求极值。Logistic回归并没有求对数似然函数的最大值,而是把极大化当做一个思想,进而推导它的风险函数为最小化的负的似然函数。从损失函数的角度上,它就成为了log损失函数。
log损失函数的标准形式: ![]()
在极大似然估计中,通常都是先取对数再求导,再找极值点,这样做是方便计算极大似然估计。损失函数L(Y,P(Y|X))是指样本X在标签Y的情况下,使概率P(Y|X)达到最大值(利用已知的样本分布,找到最大概率导致这种分布的参数值)
最小二乘法是线性回归的一种方法,它将回归的问题转化为了凸优化的问题。最小二乘法的基本原则是:最优拟合曲线应该使得所有点到回归直线的距离和最小。通常用欧式距离进行距离的度量。平方损失的损失函数为:
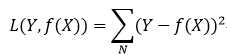
AdaBoost就是一指数损失函数为损失函数的。
指数损失函数的标准形式: ![]()
Hinge loss用于最大间隔(maximum-margin)分类,其中最有代表性的就是支持向量机SVM。
在支持向量机中,最初的SVM优化的函数如下:
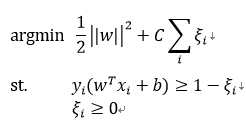
原文:https://www.cnblogs.com/nxf-rabbit75/p/10440805.html