? 最近在做一个pyqt登录校园网的小项目,想在窗口的状态栏加上当天的天气情况,用爬虫可以很好的解决我的问题。
? 考虑到所处位置的不同,需要先获取本地城市地址,然后作为中国天气网的输入,爬取指定城市的天气信息。
? a. 先通过https://www.ip.cn/爬取本地城市名称
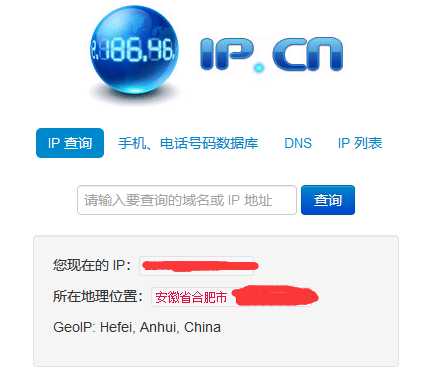
b. 再通过获取本地城市名称作为输入

进入城市页面获取所需信息即可,看起来不难,不就是爬、爬吗
? a 很容易实现,直接上代码
target_url = 'https://www.ip.cn/'
municipality = ['北京市','上海市','重庆市','天津市']
def download_page(url):
"""
获取网页源代码
"""
html = requests.get(url).content
return html
def get_city_name(html):
"""
对网页内容进行解析并分析得到需要的数据
"""
selector = etree.HTML(html) # 将源码转换为能被XPath匹配的格式
location = selector.xpath("/html/body/div/div[4]/div/p[2]/code")[0].text
location = location.split(" ")[0]
if location in municipality:
city = location[:-1] # 直辖市的话不取'市',不然天气结果会不准
else:
for i, char in enumerate(location):
if char == "区" or char == "省":
index = i + 1
break
city = location[index:-1] # 取'省'后面一直到'市'中间的城市名称用作天气搜索
return city
我的ip会返回‘合肥’,北京,上海这些直辖市和一些自治区需要特别处理一下才能获得所需城市名,这里必须返回城市名称,不然直接搜索会出现这样,得不到任何天气data,好吧,能给我天气情况就行,要什么自行车:

?
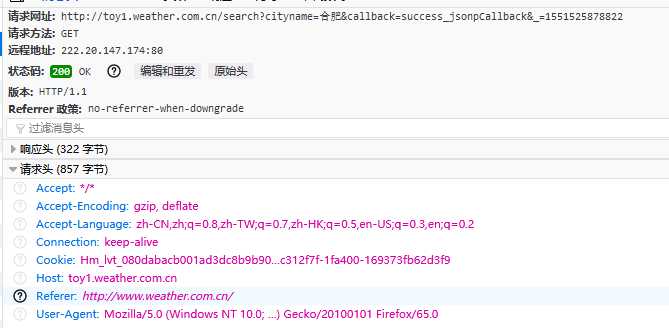
b 的话需要2步走,首先获取城市对于编码
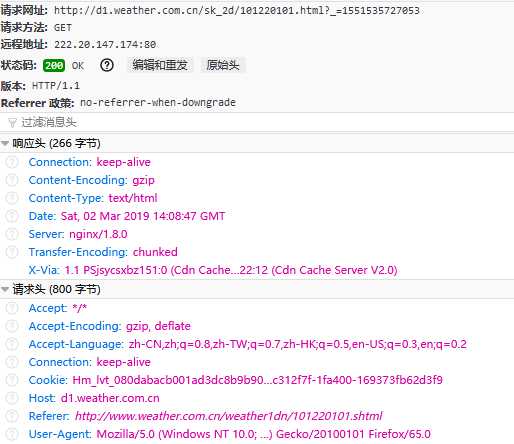
在输入合肥点击搜索之后,通过观察网络请求信息,浏览器发送了一个GET请求,服务器响应数据中包含城市码,如下图

def get_city_code(city='合肥'):
"""
输入一个城市,返回在中国天气网上城市所对应的code
"""
try:
parameter = urlparse.parse.urlencode({'cityname': city})
conn = http.client.HTTPConnection('toy1.weather.com.cn', 80, timeout=5)
conn.request('GET', '/search?'+parameter)
r = conn.getresponse()
data = r.read().decode()[1:-1]
json_data = json.loads(data)
code = json_data[0]['ref'].split('~')[0] # 返回城市编码
return code
except Exception as e:
raise e模拟发送请求即可,头信息在这,这里&callback和&_参数可以不要,然后对响应做下处理,因为得到的JSON数据字符串,需要将字符串转为JSON数据格式,这就能得到城市码了。
终于到了最后一步,也是最烦,不对,是最难的一步,获取城市天气信息,按说操作思路和上面差不多,就是分析页面数据然后找标签就行了,,,
可是这个网站竟然是javascript动态加载的,获取的页面图上所指的内容啥都没,这要我怎么获取天气情况,对于只会爬取非动态网页的小白,只能留下没技术的眼泪。
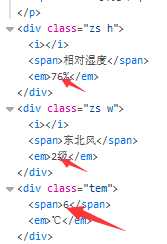
?就这样,又去学了一点动态爬取网站的基础知识,通过一个一个请求分析查看,终于找到了我所要的信息,其实只要看响应就行了,服务器js返回的值都在这能看到。

接着套路和上面一样,发送一个GET请求等服务器返回数据我们拿来用就行了
。。。。。。。。

问题又出现了,这次又是403,还有有人已经走过这条路了,在GET请求加上headers就行了,不让服务器发现这是爬取,而是认为这是浏览器在请求,结果发现只需要架构Referer就行,看来服务器并没有真正做到反扒。。。。
def get_city_weather(city_code):
"""
通过城市编码找到天气信息
"""
try:
url = 'http://www.weather.com.cn/weather1dn/' + city_code + '.shtml'
# 这里选择的体验新版,所以是1dn,旧版是1d
headers = { "Referer": url }
conn = http.client.HTTPConnection('d1.weather.com.cn', 80, timeout=5)
conn.request('GET', '/sk_2d/' + city_code + '.html', headers=headers)
r = conn.getresponse()
data = r.read().decode()[13:]
weather_info = json.loads(data)
return weather_info
except Exception as e:
raise e好了,大功告成!

贴一下自己的代码供有需要的人参考:
import json
import urllib as urlparse
import http.client
import requests
from lxml import etree
target_url = 'https://www.ip.cn/'
municipality = ['北京市','上海市','重庆市','天津市']
def download_page(url):
"""
获取网页源代码
"""
html = requests.get(url).content
return html
def get_city_name(html):
"""
对网页内容进行解析并分析得到需要的数据
"""
selector = etree.HTML(html) # 将源码转换为能被XPath匹配的格式
location = selector.xpath("/html/body/div/div[4]/div/p[2]/code")[0].text
location = location.split(" ")[0]
if location in municipality:
city = location[:-1] # 直辖市的话不取'市',不然天气结果会不准
else:
for i, char in enumerate(location):
if char == "区" or char == "省":
index = i + 1
break
city = location[index:-1] # 取'省'后面一直到'市'中间的城市名称用作天气搜索
return city
def get_city_code(city='合肥'):
"""
输入一个城市,返回在中国天气网上城市所对应的code
"""
try:
parameter = urlparse.parse.urlencode({'cityname': city})
conn = http.client.HTTPConnection('toy1.weather.com.cn', 80, timeout=5)
conn.request('GET', '/search?' + parameter)
r = conn.getresponse()
data = r.read().decode()[1:-1]
json_data = json.loads(data)
code = json_data[0]['ref'].split('~')[0] # 返回城市编码
return code
except Exception as e:
raise e
def get_city_weather(city_code):
"""
通过城市编码找到天气信息
"""
try:
url = 'http://www.weather.com.cn/weather1dn/' + city_code + '.shtml'
headers = { "Referer": url }
conn = http.client.HTTPConnection('d1.weather.com.cn', 80, timeout=5)
conn.request('GET', '/sk_2d/' + city_code + '.html', headers=headers)
r = conn.getresponse()
data = r.read().decode()[13:]
weather_info = json.loads(data)
return weather_info
except Exception as e:
raise e
if __name__ == '__main__':
city = get_city_name(download_page(target_url))
city_code = get_city_code(city)
city_wether = get_city_weather(city_code)
print(city_wether)PS:第一次写博客,markdown刚学还不是很熟,表达可能也有点欠缺。
每次都是从别人那填好的坑走过,这次要填自己的坑,给别人开路
原文:https://www.cnblogs.com/huxiaozhouzhou/p/10463405.html