CPU增加高速缓存,线程切换分时复用CPU,编译程序优化指令次序。这三个操作提升了性能,但也带来了三个导致并发安全性的特性,即 可见性,原子性,有序性。
下面深入介绍一下三个特性出现的原因:
一.可见性: (多核CPU缓存导致)
单核CPU的线程操作同一个CPU缓存,具有线程间的可见性。而多核CPU的缓存,多个线程操作会操作不同CPU的缓存,造成不可见性。
例如:A线程,B线程 同时对变量C进行循环1万次自增操作 。假如某时A线程将变量C加1,写入自己的CPU缓存,但还未写入内存,这将导致B线程操作C变量的时候,读的还是内存中旧值。导致最终变量C的结果不是20000,而是 10000到20000的随机数。
如以下代码:
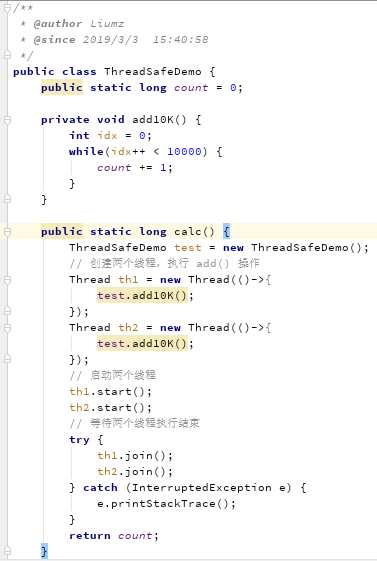
执行了方法后的结果:
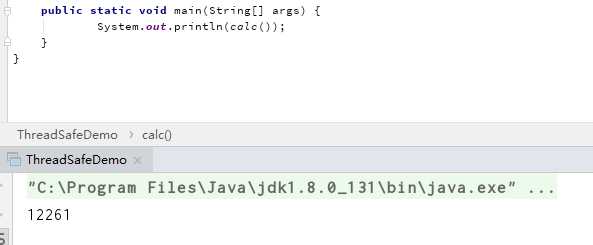
总结:A线程计算的变量放在自己的CPU缓存中,还未读入内存。导致B不可见,从内存读的还是旧的数据,导致数据计算错误。
二.原子性: (非原子操作和线程切换带来)
一条高级语言指令通常需要多条CPU指令完成。CPU指令是原子操作。
如 count +=1 语句需要三条CPU指令
1.将count变量从内存写入CPU的寄存器。
2.在CPU中进行 +1 操作。
3.结果写入内存(或写入CPU缓存)。
操作系统根据线程分时切换来调度任务。线程切换时,可能发生在任何一条CPU指令执行完
假如线程A,线程B都对count做自增操作,当线程A执行到指令1后,切换到了线程B执行指令1,2,3。这时内存中count值写入为1。
再切换到线程A,此时直接执行2,3。此时写入内存的仍然是count=1。而不是原子操作自增的2。
总结就是:非原子性操作时,线程A操作变量操作还未写入内存中,线程B已经对此变量进行读操作。导致数据不正确。
三.有序性:(编译优化)
编译器为了优化性能,会改变程序执行的先后顺序
例子:双重检查创建单例对象
如以下代码:

若有两个线程来获取实例,比如此时线程A获取锁,进入 instance = new LazySingletonSync2() 时。线程B开始调用getInstance方法,进行 if(instance == null) 的判断,
此时关键出现在 instance = new LazySingletonSync2() 语句的指令执行顺序上:
new对象时,我们认为的操作是:
1.分配一块内存M
2.在内存M上初始化对象 instance
3.将内存M的地址赋值给变量
实际编译器优化后是
1.分配一块内存M
2.将内存M的地址赋值给变量
3.在内存M上初始化对象 instance
若线程A这时只执行到第2步指令,导致 线程B 判断 instance == null 为否,直接返回了instance。但其实此时对象还没初始化。这就导致了线程B返回的对象是有问题的,直接调用会造成空指针引用的异常。
原文:https://www.cnblogs.com/liumz0323/p/10467527.html