k-近邻算法可以完成很多分类任务,但是它最大的缺点就是无法给出数据的内在含义,决策树的主要优势在于数据形式非常容易理解。比如给你一个100以内的数来猜,通过对你猜的数的是大还是小来引导你得到最后的结果。
优点:计算复杂度低,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特诊数据。
缺点:可能会产生过度匹配问题。
第一个要解决的是找出哪些特征在划分数据分类时起决定性作用,特征选取的越好,得到的划分结果越是准确。
信息增益:划分数据集前后信息发生的变化。信息增益在集合信息的度量方式称为熵。熵定义为信息的期望值。符号xi的信息定位为:
l(xi)=-log2p(xi) ,p(xi)表示选择该分类的概率
此时信息期望为:
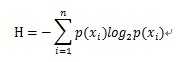
其中n为分类数目。
def calcShannonEnt(dataSet): numEntries = len(dataSet) labelsCounts= {} for featVec in dataSet: currentLabel = featVec[-1] if currentLabel not in labelsCounts.keys(): labelsCounts[currentLabel]=0 labelsCounts[currentLabel]+=1 shannonEnt=0.0 for keys in labelsCounts: prob=float(labelsCounts[keys])/numEntries shannonEnt-=prob*log(prob,2) return shannonEnt
上面的代码是计算特定特征的数据集熵。
在构建决策树时采用的是递归的方法,递归结束的条件是遍历完所有划分数据集的属性,或者每个分支下的所有实例都是具有相同的分类。这个过程会很耗时。
原文:http://www.cnblogs.com/zhxg/p/3892831.html