错误名:TypeError: to_bytes must receive a unicode, str or bytes object, got int
错误翻译:类型错误:to_bytes必须接收unicode、str或bytes对象,得到int to_bytes也就是需要传给服务器的二进制数据
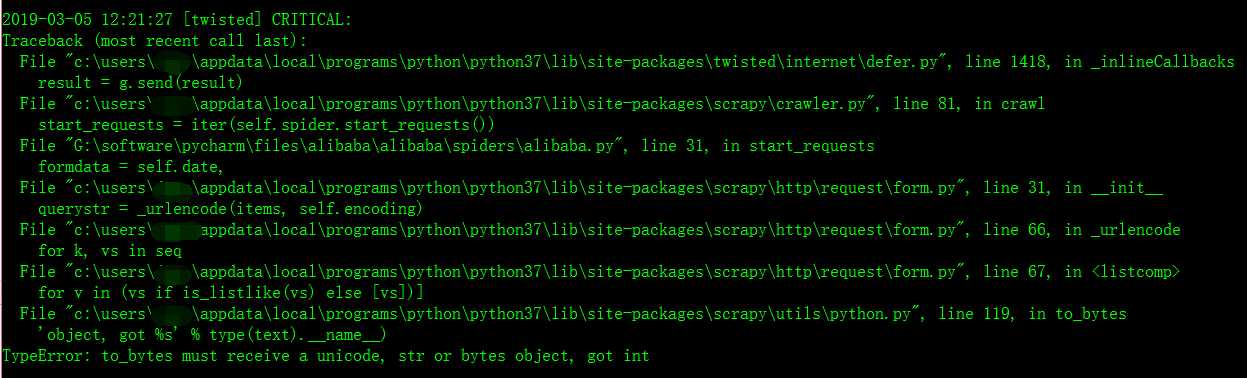
今天我企图用scrapy爬虫框架爬取阿里巴巴以及百度和腾讯的招聘网站的职位信息,在简单的进行数据分析。但是当我在写框架代码时,遇到了一个错误,我找了很久,最后发现只是一个小小的错误,就是字符串的格式出错了,我足足弄了两个小时。唉,真是想骂自己啊。。。
先来上我的错误代码
1 from lxml import etree 2 import scrapy 3 from scrapy.linkextractors import LinkExtractor 4 from scrapy.spiders import Rule,CrawlSpider 5 from alibaba.items import AlibabaItem 6 import json 7 8 9 10 11 12 class AlibabaSpider(CrawlSpider): 13 name = "alibabahr" 14 allowed_domains = ["alibaba.com"] 15 16 def __init__(self,pageIndex):
#由于阿里巴巴的限制,他们将职位信息放在了一个json文件中,用js进行数据传输,但是也没有关系,还是一样可以抓取到 下面是json数据抓取的链接URL 17 self.start_urls = ["https://job.alibaba.com/zhaopin/socialPositionList/doList.json"] 18 self.pageIndex = pageIndex #这是需要抓取的页数 19 20 21 22 def start_requests(self): 23 for page in range(int(self.pageIndex)): 24 yield scrapy.FormRequest( 25 url = self.start_urls[0], 26 callback = self.parse, 27 formdata = {"pageIndex":page,"pageSize":10}, #因为阿里的一个json文件中,是放10个职位的信息,也就是一页的信息,官网上是一
#页10个职位信息 大家看到那个"pageIndex":page,"pageSize":10 了吗,那个value值在这里是一个int型的数据,但是在进行post数据传输时,scrapy.FormRuquest
#这个方法默认是传输字符串的 所以就会报那个错误,我们只需要把那个10和page变成str数据结构就行了。
#将最后那句改成 : formdata = {"pageIndex":str(page),"pageSize":"10"}, 就可以了
28 ) 29 30 def parse(self, response): 31 content = json.loads(response.body)[‘returnValue‘] 32 pageIndex = content[‘pageIndex‘] 33 jobDates = content[‘datas‘] 34 print("pageIndex:" + str(pageIndex)) 35 print(jobDates)
改正错误之后,显示的信息是真确的,如图:

scrapy框架之post传输数据错误:TypeError: to_bytes must receive a unicode, str or bytes object, got int
原文:https://www.cnblogs.com/jums/p/10476008.html