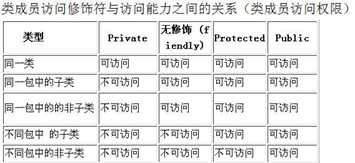
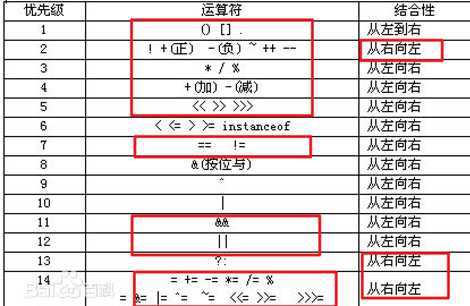
括号,非正负和自增减(右到左),乘除加减,等于不等于,逻辑与和或,然后是三木(从右到左)。最后是赋值(+=…右到左)
int x=3;
int y=1;
if(x=y)
String:不可变字符序列(成员变量字节数组被final修饰,所以是不可变的字符串序列)

StringBuilder:可变字符序列,线程不安全
StringBuffer:可变字符序列,线程安全


jre 判断程序是否执行结束的标准是(所有的前台线程执行完毕)
下面哪个语句是创建数组的正确语句?( )
float f[][] = new float[][6];
byte[] src,dst;
dst=new String (src,”GBK”).getbytes(“UTF-8”);
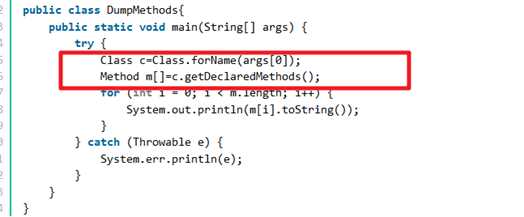
返回 Method 对象的一个数组,这些对象反映此 Class 对象表示的类或接口声明的所有方法, 包括公共、保护、默认(包)访问和私有方法,但不包括继承的方法。
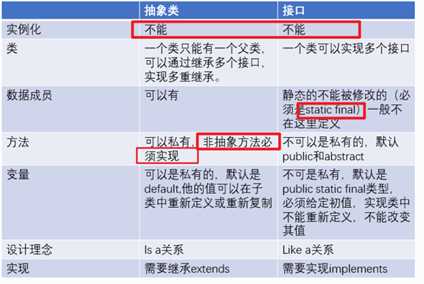

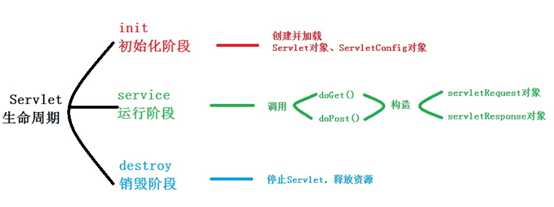
数据库系统
A: 垃圾回收在jvm中优先级相当相当低。
B:垃圾收集器(GC)程序开发者只能推荐JVM进行回收,但何时回收,回收哪些,程序员不能控制。
C:垃圾回收机制只是回收不再使用的JVM内存,如果程序有严重BUG,照样内存溢出。
D:进入DEAD的线程,它还可以恢复,GC不会回收(真正宣布一个对象死亡,至少需要经历2次标记过程。当第一次标记时会同时进行一次筛选(判断此对象是否有必要执行finalize方法)。如果对象没有覆盖该方法,就面临死亡)
final 可以修饰类,不能被继承;修饰方法,不能被重写;修饰变量,只能赋值一次
?
finally 是 try 语句中的一个语句体,不能单独使用,用来释放资源
?
finalize 是一个方法,当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法。
他是持久层框架,为了降低应用程序对物理数据源访问的频次,从而提高应用程序的运行性能,需要使用缓存机制。
1. Hibernate一级缓存又称为”session的缓存”。
session缓存内置不能被卸载,session的缓存是事务范围的缓存(session对象的生命周期通常对应一个数据库事务或者一个应用事务)。
一级缓存中,持久化类的每个实例都具有唯一的OID
2. Hibernate的二级缓存又称为”sessionFactory的缓存”。
由于sessionFactory对象的生命周期和应用程序的整个过程对应,因此Hibernate二级缓存是进程范围的缓存,有可能出现并发问题,因此需要采用适当的并发访问策略,该策略为被缓存的数据提供了事务隔离级别。
getClass(), clone(),
hashCode(),equals(),toString()
wait(),notify(), notifyAll(),
finalize()

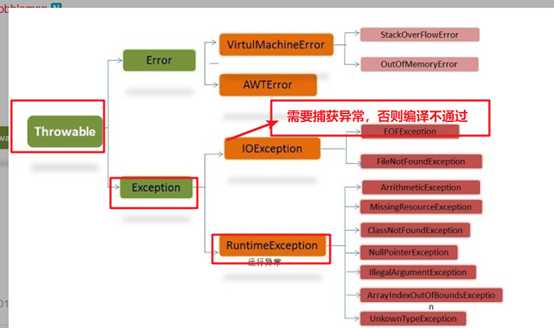
jvm有一个默认的异常处理机制:控制台打印异常相关信息;程序停止
>所有的RuntimeException类及其子类被称为运行时异常
>其他的异常就是编译时异常
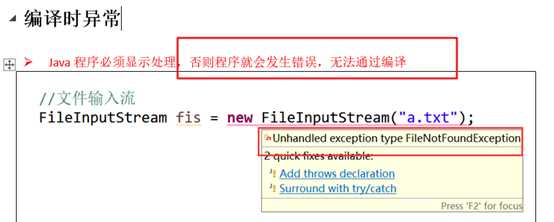

throws
用在方法声明后面,跟的是异常类名
可以跟多个异常类名,用逗号隔开
它表示抛出异常,由该方法的调用者来处理
throw
用在方法体内,跟的是异常对象名
只能抛出一个异常对象名,表示抛出异常
? final可以修饰类,不能被继承;修饰方法,不能被重写;修饰变量,只能赋值一次
? finally是try语句中的一个语句体,不能单独使用,用来释放资源
? finalize是一个方法,当垃圾回收器确定不存在对该对象的更多引用时,由对象的垃圾回收器调用此方法。【当对象从内存中消失会调用这个方法】
boolean isOdd = false;
for(int i=1;i<=2;++i)
{
if(i%2==1)isOdd = true;
else isOdd = false;
a+=i*(isOdd?1:-1);
}
-1
-2
0
1

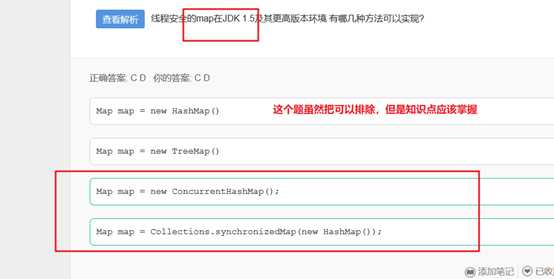

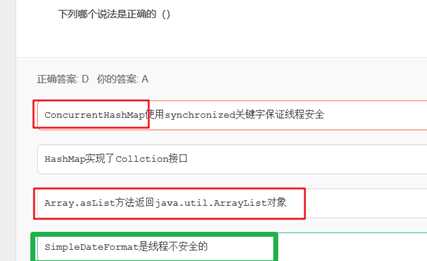
A选项中,ConcurrentHashMap 使用segment来分段和管理锁,segment继承自ReentrantLock,因此ConcurrentHashMap使用ReentrantLock来保证线程安全。
C中,应该是Arrays.asList(),其将一个数组转化为一个List对象,这个方法会返回一个ArrayList类型的对象, 这个ArrayList类并非java.util.ArrayList类,而是Arrays类的内部类:

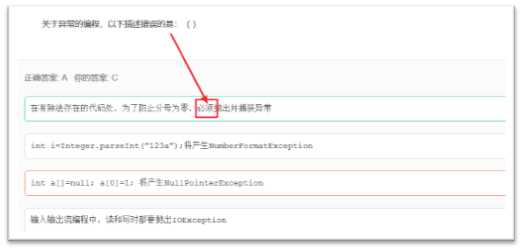

异常分为运行时异常,非运行时异常和error,其中error是系统异常,只能重启系统解决。非运行时异常需要我们自己补获,而运行异常是程序运行时由虚拟机帮助我们补获,运行时异常包括数组的溢出,内存的溢出空指针,分母为0等!

栈
堆
方法区
垃圾回收器(GC Garbage Collection):
所谓 volatile的措施,就是
1. 每次从内存中取值,不从缓存中什么的拿值。这就保证了用 volatile修饰的共享变量,每次的更新对于其他线程都是可见的。
2. volatile保证了其他线程的立即可见性,就没有保证原子性。
3.由于有些时候对 volatile的操作,不会被保存,说明不会造成阻塞。不可用与多线程环境下的计数器。
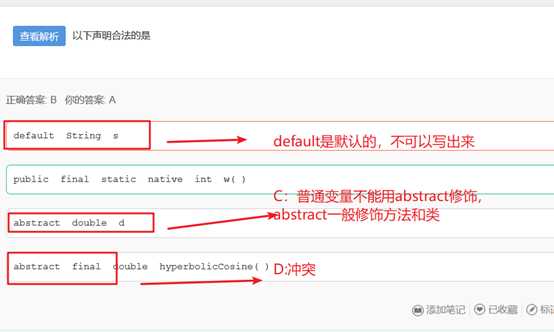
声明合法:
Math.round(-11.5)= -11(算法,+0.5取floor)
Math.round(11.5)= 12
Math类中提供了三个与取整有关的方法:ceil、floor、round
ceil的英文意义是天花板,该方法就表示向上取整,所以,Math.ceil(11.3)的结果为12,Math.ceil(-11.3)的结果是-11;
floor的英文意义是地板,该方法就表示向下取整,所以,Math.floor(11.6)的结果为11,Math.floor(-11.6)的结果是-12;
round它表示“四舍五入”,算法为Math.floor(x+0.5),即将原来的数字加上0.5后再向下取整,所以,Math.round(11.5)的结果为12,Math.round(-11.5)的结果为-11。
Netstat -nltp
Netstat -nlup
netstat命令各个参数说明如下:
-t : 指明显示TCP端口
-u : 指明显示UDP端口
-l : 仅显示监听套接字(所谓套接字就是使应用程序能够读写与收发通讯协议(protocol)与资料的程序)
-p : 进程的名称
-n : 不进行DNS轮询(可以加速操作)
Ps –ef (e:显示所有进程 f:全格式
ls –al |more(分页查看目录)
按常理来说,这个sql语句应该是:
delete tablename where id not in(select min(id) from tablename group by name,kecheng,fenshu);
这种写法在sqlserver或者oracle中是支持的,但是mysql目前是不支持的,会报类似错:You can‘t specify target table ‘tablename‘ for update ,这是因为在mysql中不能同时查询一个表的数据再同时进行删除.
因此我们可以考虑用别名的方法,将子查询的结果放到一个别名中。
完整的sql语句如下:
DELETE FROM tablename where id not in (select bid from (select min(id) as bid from tablename group by name,kecheng,fenshu) as b ) ;
解释:
select bid from (select min(id) as bid from tablename group by name,kecheng,fenshu) as b
这个子查询的目的是从b中列出讲筛选结果,即bid的集合。
(select min(id) as bid from tablename group by name,kecheng,fenshu) as b
将分组结果中的最小的bid当做一个心的集合当做一个心的子表b,
注意mid(id)一定要有一个别名,这里取的是bid,作为b的一个列名,因为在上一级查询中要用到这个列名(红色标注)

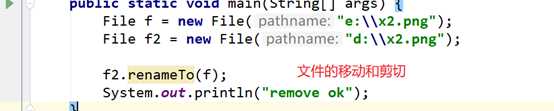

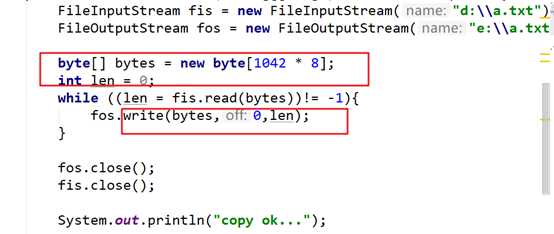
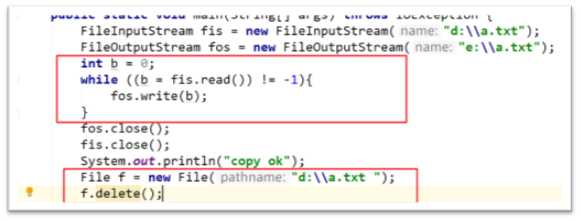
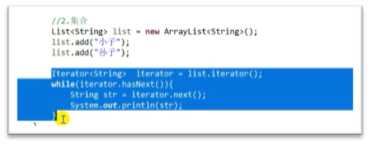
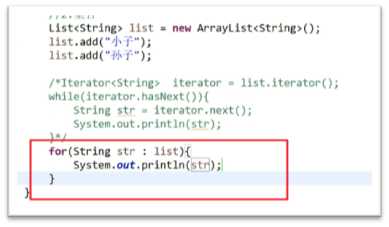
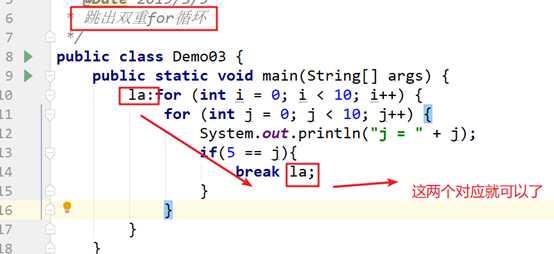

(单例的一个例子)

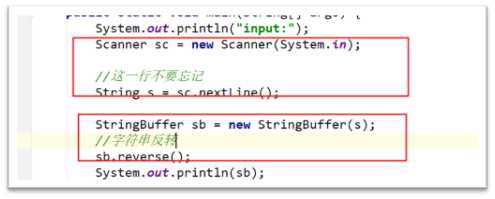
(这个涉及到hash表的一些问题)hashCode相等,equals也不一定相等, 两个类也不一定相等
equals相同, 说明是同一个对象, 那么hashCode一定相同
(重名的人很多, 名字相同, 但不是同一个人, hashCode就是名字, 人就是对象)
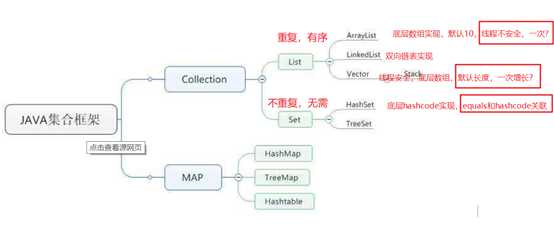
List列表在数据结构上可以被看做线性表,常用的有ArrayList和LinkList(不常用的有Vector(类似于ArrayList)),他们的底层存储结构有所不同,一个是数组,一个是链表;这两个是注重数据存储结构的区分和数据结构数据操作方法上的区分,也就是栈和队列;即Stack和Queue,Stack是一个继承了Vector的类,Queue是一个继承于Collection的接口(因为队列可以分很多种),LinkedList实现了Deque接口,Deque继承了Queue接口,常用的有ArrayBlockingQueue(基于数组),LinkedBlockingQueue(基于链表),PriorityBlockingQueue(实现优先级排序)等。
Map是一种映射,用于存储关系型数据,保存着两种值,一组用于保存key,另外一组用于保存valeu,并且key不能重复。\
Set集合,存储的元素不能重复,其通过equals的方法,来判断元素是否重复
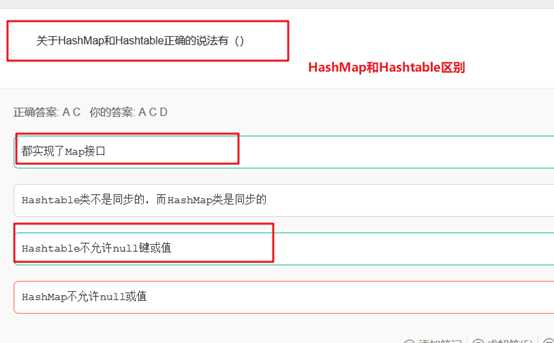
HashTable和HashMap的实现原理几乎一样,差别无非是1.HashTable不允许key和value为null;HashTable是线程安全的。
ConcurrentHashMap采用了非常精妙的”分段锁”策略。
这个map的主干是segment,而segment继承了ReentrantLock,从而实现了线程安全。
HashMap:数组方式存储key/value,线程非安全,允许null作为key和value,key不可以重复,value允许重复,不保证元素迭代顺序是按照插入时的顺序,key的hash值是先计算key的hashcode值,
TreeMap:基于红黑二叉树的NavigableMap的实现,线程非安全,不允许null,key不可以重复,value允许重复
用volatile修饰的变量,线程在每次使用变量的时候,都会读取变量修改后的最的值。
List 元素是有序的、可重复
ArrayList、Vector默认初始容量为10
Vector:线程安全,但速度慢
底层数据结构是数组结构
加载因子为1:即当 元素个数 超过 容量长度 时,进行扩容
扩容增量:原容量的 1倍
如 Vector的容量为10,一次扩容后是容量为20
ArrayList:线程不安全,查询速度快
底层数据结构是数组结构
扩容增量:原容量的 0.5倍+1
如 ArrayList的容量为10,一次扩容后是容量为16
Set(集) 元素无序的、不可重复。
HashSet:线程不安全,存取速度快
底层实现是一个HashMap(保存数据),实现Set接口
默认初始容量为16(为何是16,见下方对HashMap的描述)
加载因子为0.75:即当 元素个数 超过 容量长度的0.75倍 时,进行扩容
(为何加载因子小于1而不等于1:当向Set中添加对象始,首先调用此对象所在类的hashCode()方法。
计算此对象的哈希值,此哈希值决定了此对象在set中的位置。存储空间不是连续的)
扩容增量:原容量的 1 倍
如 HashSet的容量为16,一次扩容后是容量为32
Map是一个双列集合
HashMap:默认初始容量为16
(为何是16:16是2^4,可以提高查询效率,另外,32=16<<1 -->至于详细的原因可另行分析,或分析源代码)
加载因子为0.75:即当 元素个数 超过 容量长度的0.75倍 时,进行扩容
扩容增量:原容量的 1 倍
如 HashSet的容量为16,一次扩容后是容量为32
eg.
ArrayList list = new ArrayList(20);中的list扩充几次?
答:0次。
解析: ArrayList list=new ArrayList(); 这种是默认创建大小为10的数组,每次扩容大小为1.5倍。
ArrayList list=new ArrayList(20); 这种是指定数组大小的创建,没有扩充。
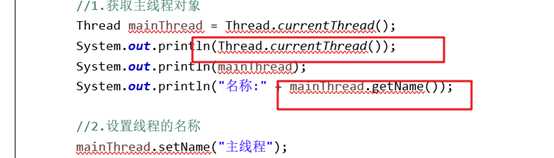
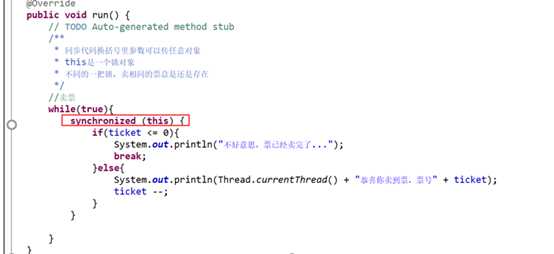



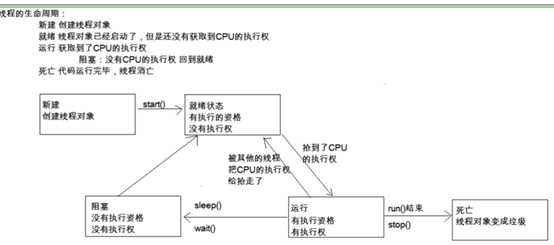
ReentrainLock




$(document).ready和window.onload都是在都是在页面加载完执行的函数,大多数情况下差别不大,但也是有区别的。
$(document).ready:是DOM结构绘制完毕后就执行,不必等到加载完毕。 意思就是DOM树加载完毕,就执行,不必等到页面中图片或其他外部文件都加载完毕。并且可以写多个.ready。
window.onload:是页面所有元素都加载完毕,包括图片等所有元素。只能执行一次。
原文:https://www.cnblogs.com/juna3066/p/10479041.html