今天看王树义老师的简书,发现有个评论把这篇文章转载了,于是打开评论里的链接,发现里面是很多质量很高的博文,于是想着把这些都爬下来,分个类。
本文代码是个人学习使用,原网站实时更新,如需观看更多高质量文章,请访问原网站:https://www.linkedinfo.co/infos
代码还是很好写的,没有什么难点,写这篇文章只是记录一下并做个标记,以后有问题可以去这个网站去查查。
下面我稍稍分析一波,然后老规矩列一下代码
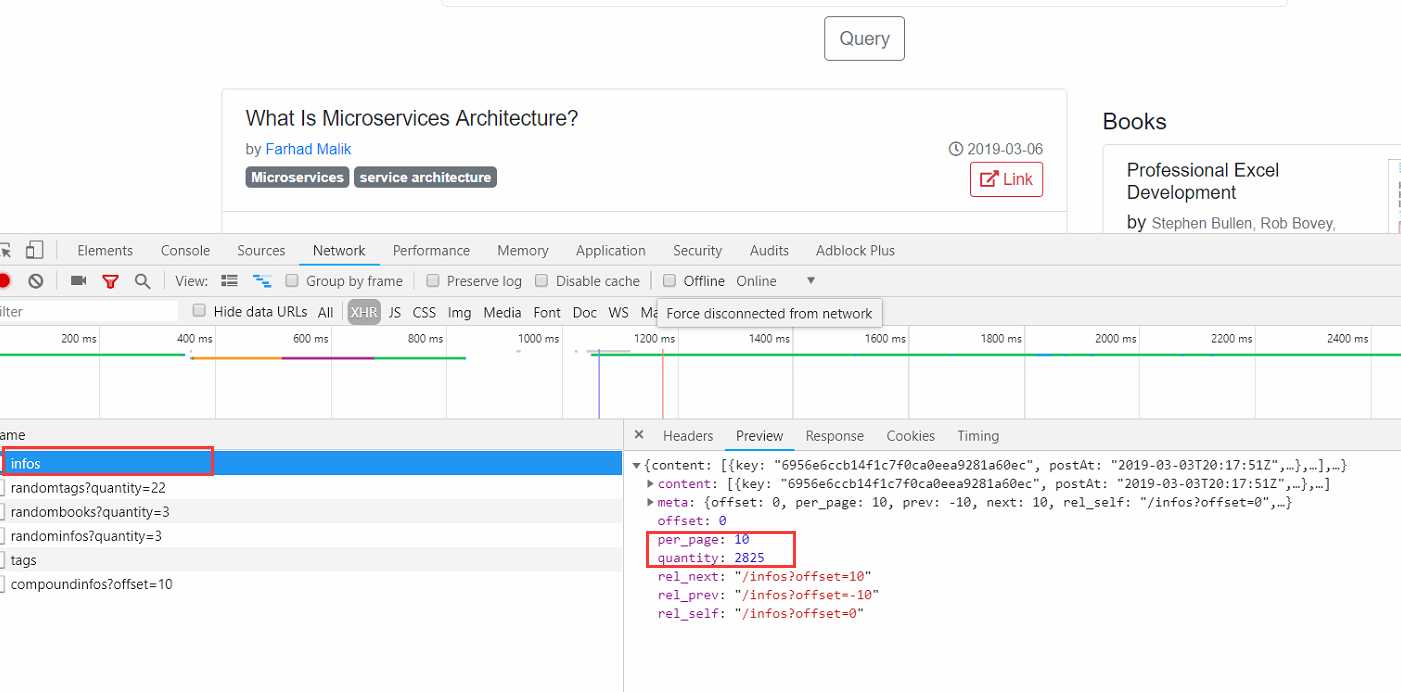
per_page:10 每页显示10条文章
quantity:2825 现在共有2825篇文章
多次查看,发现地址变化规律
https://www.linkedinfo.co/infos?offset=可变数字
1 for i in range(283): 2 url = ‘https://www.linkedinfo.co/infos?offset={}‘.format(i*10)
源代码:
本文使用excel来存储数据
import requests import re from openpyxl import workbook myx=workbook.Workbook() xl=myx.active xl.append([‘title‘,‘url‘,‘description‘]) def link(url,headers): data=requests.get(url,headers=headers,verify=False).text title=re.findall(r‘"title":"(.*?)"‘,data) urls=re.findall(r‘"url":"(.*?)"‘,data) desc=re.findall(r‘"description":"(.*?)"‘,data) long=len(title) for i in range(long): xl.append([title[i],urls[i],desc[i]]) myx.save(‘d://Temp/linkinfo.xlsx‘) if __name__ == ‘__main__‘: headers = { ‘Cookie‘: ‘__cfduid=db0849c0a6132096a19db45ce6a4e9a341551852460; _ga=GA1.2.434447590.1551852463; _gid=GA1.2.1036300570.1551852463‘, ‘Referer‘: ‘https://www.linkedinfo.co/infos?offset=0‘, ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36‘, ‘Accept‘: ‘application/json‘, # 一开始没加这个,读取失败 } for i in range(283): url = ‘https://www.linkedinfo.co/infos?offset={}‘.format(i*10) link(url,headers)
原文:https://www.cnblogs.com/zxg-1997/p/10485220.html