1、虚拟机运行在QEMU进程地址空间中
KVM利用malloc()或者mmap系统调用,在QEMU主线程的虚拟地址空间中申明一段连续大小的空间用于客户机物理内存映射,在QEMU的内存管理结构中逐步添加subregion。
QEMU进程的运行跟普通的Linux进程一样,通过malloc()或者mmap()函数来申请它自己的内存,malloc()实现的大体思路:首先挨个检查堆中的内存是否可用,如果可用那么大小是否能满足需求,要是都满足的话就直接用。当遍历了堆中的所有内存块时,要是没有能满足需求的块时就只能通过系统调用sbrk()向操作系统申请新的内存,然后将新的内存添加到堆中。因此,如果一个Guest需要1GB的物理内存,QEMU会切实调用malloc(1<<30),从主机虚拟内存分配1GB给该它,然而,跟普通进程一样,在调用malloc()的时候实际上并没有分配实际的物理内存,也就是,该内存并没有实际分配,而仅仅是维护虚拟地址空间vm_area_struct而已,只有在真正需要的时候才分配物理内存,这就是COW(COPY-ON-WRITE:写时复制)技术,而物理分配的过程就是缺页异常处理。
Guest运行起来后,它将由上面malloc()申请分配来的内存看做自己的物理内存,在Guest的内核要访问它所认为的物理内存地址0x00时,它实际所看到的是由QEMU进程调用malloc()得来的内存的第一页,但因为QEMU进程在真正需要的时候才会分配物理内存,所以客户机访存时,会发生缺页陷入KVM中,在KVM的ept缺页处理中,会先去维护Host的QEMU进程页表,再维护ept页表。
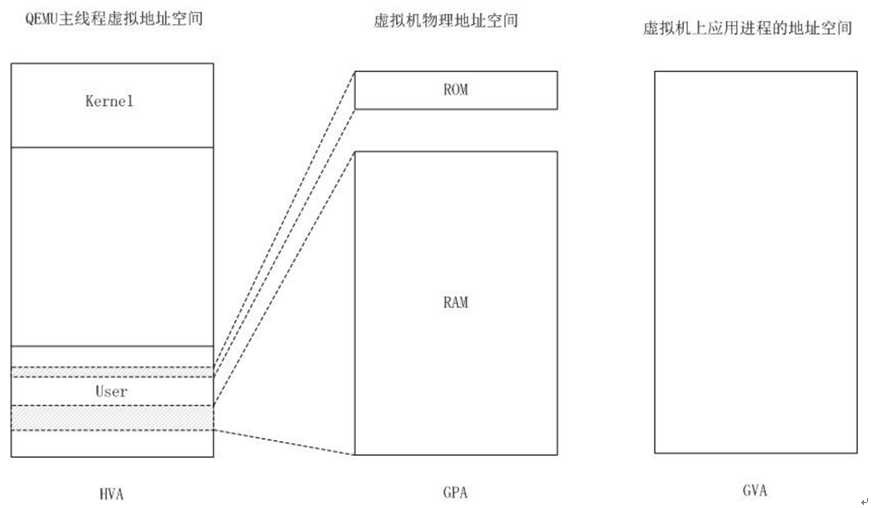
虚拟机和QEMU进程地址空间关系
2、内存槽(slot)的注册和管理
为了实现对内存区域的管理,KVM使用kvm_memory_slot结构对应QEMU中的AddressSpace,QEMU将虚拟机的物理地址在KVM中注册为多个内存槽,kvm_memory_slot结构如下:
/*kvm采用了kvm_memory_slot结构来对应Qemu中的AddressSpace。 Qemu将虚拟机的线性地址(物理地址)在KVM中注册为多个内存槽 每个虚拟机的物理内存由多个slot组成, 每个slot对应一个kvm_memory_slot结构, 该结构记录slot映射的是哪些客户物理虚拟page*/ struct kvm_memory_slot {//GPA->HVA 记录每一个地址区间的映射关系 gfn_t base_gfn;//该slot对应虚拟机页框起点 unsigned long npages;//映射的内存页数目 unsigned long *dirty_bitmap;//一个slot有许多客户机虚拟页面组成,通过dirty_bitmap标记每一个页是否可用 struct kvm_arch_memory_slot arch;//体系结构相关的结构 unsigned long userspace_addr;//起始宿主机虚拟地址 u32 flags;//slot的flag short id;//slot识别id };//首先根据客户机物理地址找到对应的映射区间,然后根据此客户机物理地址在此映射区间的偏移量就可以得到其对应的宿主机虚拟地址
KVM对每个虚拟机建立一个struct kvm结构,其中关于内存槽的结构:
struct kvm {//每个虚拟机一个,代表一个虚拟机 spinlock_t mmu_lock;//MMU最大的锁 struct mutex slots_lock;//内存槽操作锁 struct mm_struct *mm; /* userspace tied to this vm 指向虚拟机内部的页存储结构*/ struct kvm_memslots *memslots;//存储该KVM所有的memslot 在创建虚拟机时被创建kvm_create_vm
/* * Note: * memslots are not sorted by id anymore, please use id_to_memslot() * to get the memslot by its id. */ struct kvm_memslots { u64 generation; struct kvm_memory_slot memslots[KVM_MEM_SLOTS_NUM]; /* The mapping table from slot id to the index in memslots[]. */ short id_to_index[KVM_MEM_SLOTS_NUM]; };
kvm->memslots结构在创建虚拟机时kvm_create_vm被创建:
static struct kvm *kvm_create_vm(unsigned long type) { int r, i; struct kvm *kvm = kvm_arch_alloc_vm(); if (!kvm) return ERR_PTR(-ENOMEM); r = kvm_arch_init_vm(kvm, type); if (r) goto out_err_nodisable; r = hardware_enable_all(); if (r) goto out_err_nodisable; #ifdef CONFIG_HAVE_KVM_IRQCHIP INIT_HLIST_HEAD(&kvm->mask_notifier_list); INIT_HLIST_HEAD(&kvm->irq_ack_notifier_list); #endif BUILD_BUG_ON(KVM_MEM_SLOTS_NUM > SHRT_MAX); r = -ENOMEM; kvm->memslots = kzalloc(sizeof(struct kvm_memslots), GFP_KERNEL);//kvm->memslots结构在创建虚拟机时被创建 if (!kvm->memslots) goto out_err_nosrcu; kvm_init_memslots_id(kvm);
内存槽的注册入口在kvm_vm_ioctl函数中case KVM_SET_USER_MEMORY_REGION部分(在QEMU中发起流程:kvm_set_phys_mem->kvm_set_user_memory_region->kvm_vm_ioctl传参KVM_SET_USER_MEMORY_REGION),最终调用函数__kvm_set_memory_region在KVM中建立与QEMU相对应的内存槽结构。
3、KVM MMU的创建和初始化
KVM在vcpu创建时创建和初始化MMU,所以说KVM的MMU是每个VCPU独有的(但是有一些是共享的内容)。创建VCPU的代码起点是函数kvm_vm_ioctl_create_vcpu该函数中首先调用kvm_arch_vcpu_create创建vcpu,然后调用kvm_arch_vcpu_setup初始化vcpu。在x86架构中,kvm_arch_vcpu_create最终调用vmx_create_vcpu函数进行VCPU的创建工作。MMU的创建在vmx_create_vcpu -> kvm_vcpu_init -> kvm_arch_vcpu_init -> kvm_mmu_create中:
int kvm_mmu_create(struct kvm_vcpu *vcpu) { //mmu的创建 KVM的MMU是每个VCPU独有的 ASSERT(vcpu); vcpu->arch.walk_mmu = &vcpu->arch.mmu; vcpu->arch.mmu.root_hpa = INVALID_PAGE; vcpu->arch.mmu.translate_gpa = translate_gpa; vcpu->arch.nested_mmu.translate_gpa = translate_nested_gpa; return alloc_mmu_pages(vcpu); }
KVM MMU的初始化过程在kvm_vm_ioctl_create_vcpu -> kvm_arch_vcpu_setup -> kvm_mmu_setup -> init_kvm_mmu调用链中。init_kvm_mmu函数根据创建MMU的类型分别有三个调用路径init_kvm_nested_mmu、init_kvm_tdp_mmu、init_kvm_softmmu,其中init_kvm_tdp_mmu几乎初始化了kvm_mmu中所有的域。
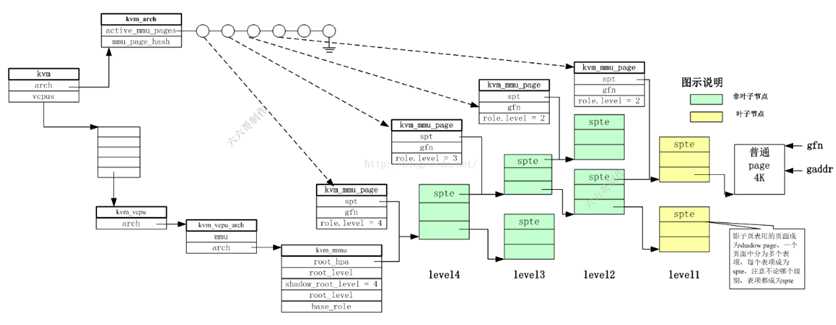
4、 EPT页表相关数据结构间联系
首先明确两个概念:物理页(physical page)和页表页(MMU page):
物理页就是真实存储数据的页;页表页就是存放EPT的页表,在KVM中每个页表页对应一个数据结构kvm_mmu_page。各自的创建方式为:(1)物理页可以通过内核提供的__get_free_page来创建,该函数最后会通过底层的alloc_page来返回一段指定大小的内存区域。(2)页表页则是从mmu_page_cache获得,该page cache是在KVM模块初始化vcpu的时候通过linux内核中的slab机制分配好作为之后MMU pages的cache使用的。
kvm_vcpu_arch结构,vcpu中架构相关的。重要成员如下:
struct kvm_vcpu_arch {//VCPU中架构相关部分 /* * rip and regs accesses must go through * kvm_{register,rip}_{read,write} functions. */ unsigned long regs[NR_VCPU_REGS]; u32 regs_avail; u32 regs_dirty; unsigned long cr0; unsigned long cr0_guest_owned_bits; unsigned long cr2; unsigned long cr3; unsigned long cr4; unsigned long cr4_guest_owned_bits; unsigned long cr8; u32 hflags; u64 efer; u64 apic_base; struct kvm_lapic *apic; /* kernel irqchip context */ unsigned long apic_attention; int32_t apic_arb_prio; int mp_state; u64 ia32_misc_enable_msr; bool tpr_access_reporting; /* * Paging state of the vcpu * * If the vcpu runs in guest mode with two level paging this still saves * the paging mode of the l1 guest. This context is always used to * handle faults. */ struct kvm_mmu mmu;//mmu成员指向vMMU结构,可以看出vMMU是每VCPU一个 /* * Paging state of an L2 guest (used for nested npt) * * This context will save all necessary information to walk page tables * of the an L2 guest. This context is only initialized for page table * walking and not for faulting since we never handle l2 page faults on * the host. */ struct kvm_mmu nested_mmu; /* * Pointer to the mmu context currently used for * gva_to_gpa translations. */ struct kvm_mmu *walk_mmu;//walk_mmu成员指向mmu struct kvm_mmu_memory_cache mmu_pte_list_desc_cache;//用来分配struct pte_list_desc结构,该结构主要用于反向映射 参考rmap_add函数,每个rmapp指向的就是一个pte_list struct kvm_mmu_memory_cache mmu_page_cache;//用来分配spt页结构,对应kvm_mmu_page.spt object数目不够则调用mmu_topup_memory_cache_page函数,其中直接调用了__get_free_page函数来获得页面 struct kvm_mmu_memory_cache mmu_page_header_cache;//用来分配struct kvm_mmu_page结构,从该cache分配的页面可能会调用kmem_cache机制来分配 //上述1,3两个cache中缓存的object数目不够 则从对应kmem_cache获取 对应函数mmu_topup_memory_cache
kvm_mmu结构是vMMU的数据结构,每一个VCPU一个该结构。重要成员如下:
hpa_t root_hpa;//存储level4页表页物理地址,如EPT中的eptp 即VMCS的EPT_pointer int root_level;// guest中页表的级别,根据VCPU特性不同而不同,如开启long mode就是4,开启PAE的就是3等 int shadow_root_level;//影子页表的级数,EPT情况下这个是4 union kvm_mmu_page_role base_role;//设置了vMMU角色所代表的一些硬件特性,如是否开启了NX,是否开启了SMEP等 bool direct_map;//该MMU是否保证存储的页结构和VCPU使用的页结构的一致性。如果为true则每次MMU内容时都会刷新VCPU的TLB,否则需要手动同步。
下面重点关注ept页表页相关数据结构
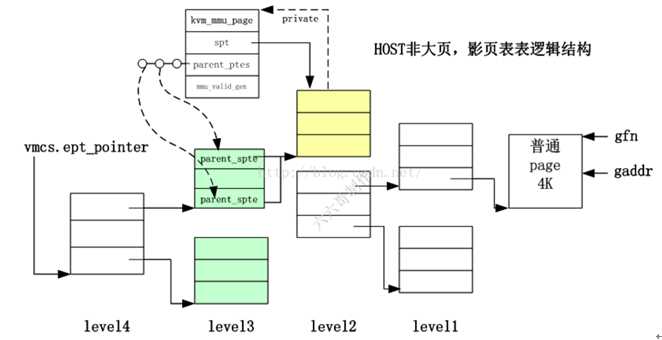
4K物理页的四级页表中重要数据结构
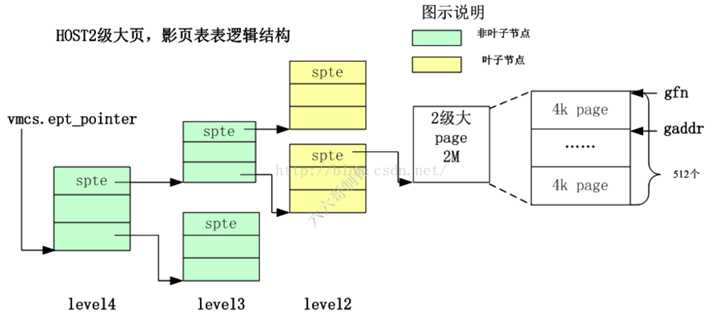
4K物理页的四级页表中重要数据结构
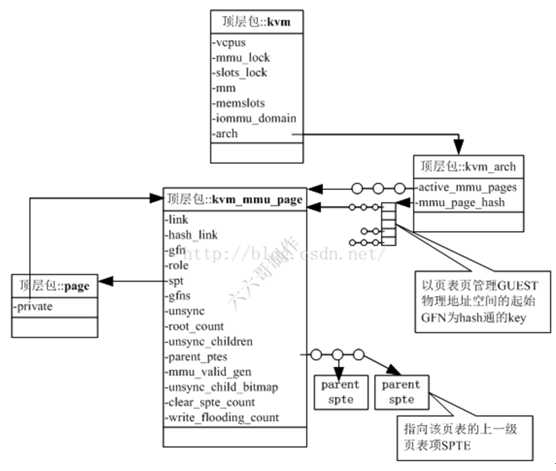
图8 Ept相关数据结构
kvm_arch结构,重要成员如下:
struct hlist_head mmu_page_hash[KVM_NUM_MMU_PAGES];// /* * Hash table of struct kvm_mmu_page. 当分配完一个kvm_mmu_page结构之后,会用其管理GUEST物理地址空间的起始GFN为key计算一个hash值, 并上到哈希表arch.mmu_page_hash[]上,以便可以快速的根据gfn找到管理该物理地址空间的页表页 */ struct list_head active_mmu_pages;//只要是激活的页表页,也会加入arch.active_mmu_page链表中,以便在后面快速的释放内存
kvm_mmu_page结构是ept页表页的管理数据结构。重要成员如下:
struct kvm_mmu_page { //EPT页表页的管理结构. KVM MMU页表的结构 struct list_head link;//将该结构链接到kvm->arch.active_mmu_pages(激活的页表页)和invalid_list上,标注该页结构不同的状态 struct hlist_node hash_link;//将该结构链接到kvm->arch.mmu_page_hash哈希表上,以便进行快速查找,hash key由接下来的gfn和role决定 /* * The following two entries are used to key the shadow page in the * hash table. */ gfn_t gfn; /*每级的页表页都会管理GUEST物理地址空间的一部分 这段GUEST物理地址空间的起始地址对应的GFN就在这个成员中被记录下来 当通过gaddr(GPA)遍历影子页表页的时候,就会根据gaddr算出gfn 然后看gfn落在每级中的哪个spte内,从而确定使用哪个spte 然后用spte来定位出下一级页表地址或pfn*/ //上述GPA->GFN然后由GFN确定spte???不是GPA不同位和EPTP一起寻址下一级页表地址么??? /*当分配完一个kvm_mmu_page结构之后, 会用其管理GUEST物理地址空间的起始GFN为key计算一个hash值, 并上到哈希表arch.mmu_page_hash[]上, 以便可以快速的根据gfn找到管理该物理地址空间的页表页*/ union kvm_mmu_page_role role; /*kvm_mmu_page结构管理的页面可以作为影子页表中任何一个level的页表 也就是影子页表所代表的角色不同,有时候是level1 有时候是level4 其所管理的页面被用作哪个界别是靠role.level区分的。*/ u64 *spt; /*指向影子页表页,页中被分为多个spte 影子页表用的页面称为shadow page,一个页面中分为多个表项,每个表项成为spte 注意不论哪个级别,表项都成为spte ->该kvm_mmu_page对应的页表页的宿主机虚拟地址hva */ /* hold the gfn of each spte inside spt */ gfn_t *gfns;// 在shadow paging机制下,每个kvm_mmu_page对应多个gfn,存储在该数组中 bool unsync;//用在最后一级页表页,用于判断该页的页表项是否与guest的翻译同步(即是否所有pte都和guest的tlb一致) //如果为false,则可能出现修改了该页中的pte但没有更新tlb,而guest读取了tlb中的数据,导致了不一致。 int root_count; /* Currently serving as active root 该页被多少个vcpu作为根页结构*/ unsigned int unsync_children;//记录该页结构下面有多少个子节点是unsync状态的 unsigned long parent_ptes; /* Reverse mapping for parent_pte 所有引用该页表页的上级页表项存放在该链表中*/ /* The page is obsolete if mmu_valid_gen != kvm->arch.mmu_valid_gen. */ unsigned long mmu_valid_gen;//该页的generation number,用于和kvm->arch.mmu_valid_gen进行比较,比它小表示该页是invalid的 /*该页的generation number。KVM维护了一个全局的的gen number(kvm->arch.mmu_valid_gen), 如果该域与全局的gen number不相等,则将该页标记为invalid page。 该结构用来快速的碾压掉KVM的MMU paging structure。 例如,如果想废弃掉当前所有的MMU页结构,需要处理掉所有的MMU页面和对应的映射; 但是通过该结构,可以直接将kvm->arch.mmu_valid_gen加1,那么当前所有的MMU页结构都变成了invalid, 而处理掉页结构的过程可以留给后面的过程(如内存不够时)再处理, 可以加快废弃所有MMU页结构的速度。 当mmu_valid_gen值达到最大时,可以调用kvm_mmu_invalidate_zap_all_pages手动废弃掉所有的MMU页结构。*/ DECLARE_BITMAP(unsync_child_bitmap, 512);//记录了unsync的子结构的位图 #ifdef CONFIG_X86_32 /* * Used out of the mmu-lock to avoid reading spte values while an * update is in progress; see the comments in __get_spte_lockless(). */ int clear_spte_count; #endif /* Number of writes since the last time traversal visited this page. */ int write_flooding_count; /*在写保护模式下,对于任何一个页的写都会导致KVM进行一次emulation。 对于叶子节点(真正指向数据页的节点),可以使用unsync状态来保护频繁的写操作不会导致大量的emulation, 但是对于非叶子节点(paging structure节点)则不行。 对于非叶子节点的写emulation会修改该域,如果写emulation非常频繁,KVM会unmap该页以避免过多的写emulation。*/ };
5、EPT页表初始化及缺页源码
EPT页表在初始化时,会将arch.mmu.root_hpa置成INVALID_PAGE,而在虚拟机的入口函数vcpu_enter_guest中调用kvm_mmu_reload->kvm_mmu_load->mmu_alloc_roots初始化根目录页面,并调用arch.mmu.set_cr3(实际为vmx_set_cr3)来设置Guest的CR3寄存器,来完成EPT根页表的初始化。
当Guest第一次访问某页面时,首先触发的是Guest OS的page fault,Guest OS会修复好自己mmu的页结构,并且访问对应的GPA,此时由于对应的EPT结构还没有建立,会触发EPT Violation。对于Intel EPT,EPT缺页的处理在函数tdp_page_fault中。tdp_page_fault 调用路径如下图:
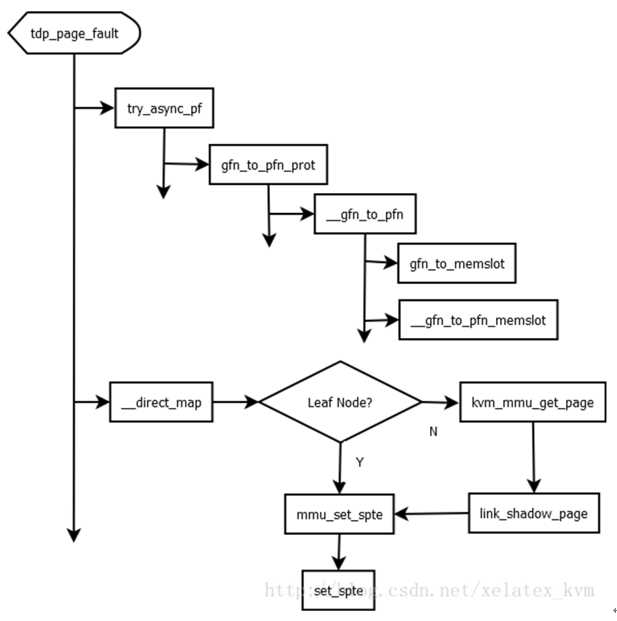
图10 tdp_page_fault 调用路径
tdp_page_fault函数是在虚拟机发生EPT Violation的处理函数,其中有两个重要函数:try_async_pf和__direct_map。
static int tdp_page_fault(struct kvm_vcpu *vcpu, gva_t gpa, u32 error_code, bool prefault) {//EPT缺页处理 负责完成GPA->HPA转化 pfn_t pfn; int r; int level; int force_pt_level; gfn_t gfn = gpa >> PAGE_SHIFT;//物理地址右移12位得到物理页框号(相对于虚拟机而言) unsigned long mmu_seq; int write = error_code & PFERR_WRITE_MASK; bool map_writable; ASSERT(vcpu); ASSERT(VALID_PAGE(vcpu->arch.mmu.root_hpa)); if(isolation_enabled)//hui { if(!xxxx_handle_ept_isolation_fault(vcpu,gpa)) return 0; } if (unlikely(error_code & PFERR_RSVD_MASK)) { r = handle_mmio_page_fault(vcpu, gpa, error_code, true);//mmio pagefault的处理 if (likely(r != RET_MMIO_PF_INVALID)) return r; } r = mmu_topup_memory_caches(vcpu);//分配缓存池 qemu-kvm自己实现内存管理功能 if (r) return r; force_pt_level = mapping_level_dirty_bitmap(vcpu, gfn);//判断当前gfn对应的slot是否可用 if (likely(!force_pt_level)) { level = mapping_level(vcpu, gfn);//得到最低级的level,如果是2M的页,那么level就为2,为4K的页,level就为1. gfn &= ~(KVM_PAGES_PER_HPAGE(level) - 1);/*获取大页的起始页框号 算式含义:对gfn向下取元整,大页面的起始页框号应该是512的整数倍*/ } else level = PT_PAGE_TABLE_LEVEL; //尝试快速处理violation,只有当GFN对应的物理页存在且violation是由读写操作引起的,才可以使用快速处理,因为这样不用加MMU-lock if (fast_page_fault(vcpu, gpa, level, error_code)) return 0; mmu_seq = vcpu->kvm->mmu_notifier_seq; smp_rmb(); if (try_async_pf(vcpu, prefault, gfn, gpa, &pfn, write, &map_writable))//从gfn获得pfn (当然这只是一个PFN,还需要PF完成真正页面的分配) return 0; if (handle_abnormal_pfn(vcpu, 0, gfn, pfn, ACC_ALL, &r))//处理反常的物理页框 return r; spin_lock(&vcpu->kvm->mmu_lock); if (mmu_notifier_retry(vcpu->kvm, mmu_seq)) goto out_unlock; make_mmu_pages_available(vcpu); if (likely(!force_pt_level)) transparent_hugepage_adjust(vcpu, &gfn, &pfn, &level); r = __direct_map(vcpu, gpa, write, map_writable, level, gfn, pfn, prefault);//完成EPT页表的构造,找到最终level的相应ept表项,设置物理地址。否则相应level不存在,则分配ept页表页 spin_unlock(&vcpu->kvm->mmu_lock); return r; out_unlock: spin_unlock(&vcpu->kvm->mmu_lock); kvm_release_pfn_clean(pfn); return 0; }
5.1 try_async_pf
该函数是从gfn获得pfn
static bool try_async_pf(struct kvm_vcpu *vcpu, bool prefault, gfn_t gfn, gva_t gva, pfn_t *pfn, bool write, bool *writable) {//根据gfn和gpa,在memslot中查找,得到qemu中分配页面的HVA,再通过host内核函数__get_user_pages_fast得到这个HVA页面的pfn bool async; *pfn = gfn_to_pfn_async(vcpu->kvm, gfn, &async, write, writable);//第四个参数不为NULL if (!async) return false; /* *pfn has correct page already */ if (!prefault && can_do_async_pf(vcpu)) { trace_kvm_try_async_get_page(gva, gfn); if (kvm_find_async_pf_gfn(vcpu, gfn)) { trace_kvm_async_pf_doublefault(gva, gfn); kvm_make_request(KVM_REQ_APF_HALT, vcpu); return true; } else if (kvm_arch_setup_async_pf(vcpu, gva, gfn)) return true; } *pfn = gfn_to_pfn_prot(vcpu->kvm, gfn, write, writable);//gfn到hva到pfn 第四个参数为NULL return false; }
gfn_to_pfn_prot-> __gfn_to_pfn两个重要函数:gfn_to_memslot和__gfn_to_pfn_memslot
static pfn_t __gfn_to_pfn(struct kvm *kvm, gfn_t gfn, bool atomic, bool *async, bool write_fault, bool *writable) { struct kvm_memory_slot *slot; if (async)//不为NULL则初始化为false *async = false; slot = gfn_to_memslot(kvm, gfn);//确定该gfn映射到哪一个kvm_memory_slot return __gfn_to_pfn_memslot(slot, gfn, atomic, async, write_fault, writable);//gfn到hva到pfn }
__gfn_to_pfn_memslot有两个重要函数:__gfn_to_hva_many和hva_to_pfn
static pfn_t __gfn_to_pfn_memslot(struct kvm_memory_slot *slot, gfn_t gfn, bool atomic, bool *async, bool write_fault, bool *writable) { unsigned long addr = __gfn_to_hva_many(slot, gfn, NULL, write_fault);//获得gfn到hva的映射 if (addr == KVM_HVA_ERR_RO_BAD) return KVM_PFN_ERR_RO_FAULT; if (kvm_is_error_hva(addr)) return KVM_PFN_NOSLOT; /* Do not map writable pfn in the readonly memslot. */ if (writable && memslot_is_readonly(slot)) { *writable = false; writable = NULL; } return hva_to_pfn(addr, atomic, async, write_fault, writable);//获得hva到pfn的映射 【重要】 正常的HOST地址翻译的过程,如果HVA对应的地址并不在内存中,还需要HOST自己处理缺页中断 }
hva_to_pfn有两个分支函数:hva_to_pfn_fast和hva_to_pfn_slow
/* * Pin guest page in memory and return its pfn. * @addr: host virtual address which maps memory to the guest * @atomic: whether this function can sleep * @async: whether this function need to wait IO complete if the * host page is not in the memory * @write_fault: whether we should get a writable host page * @writable: whether it allows to map a writable host page for !@write_fault * * The function will map a writable host page for these two cases: * 1): @write_fault = true * 2): @write_fault = false && @writable, @writable will tell the caller * whether the mapping is writable. */ static pfn_t hva_to_pfn(unsigned long addr, bool atomic, bool *async, bool write_fault, bool *writable) {//获得hva到pfn的映射 【重要】 正常的HOST地址翻译的过程,如果HVA对应的地址并不在内存中,还需要HOST自己处理缺页中断 struct vm_area_struct *vma; pfn_t pfn = 0; int npages; /* we can do it either atomically or asynchronously, not both */ BUG_ON(atomic && async); //查tlb缓存 默认页表项已经存在,直接通过遍历页表得到对应的页框 __get_user_pages_fast if (hva_to_pfn_fast(addr, atomic, async, write_fault, writable, &pfn)) return pfn; if (atomic) return KVM_PFN_ERR_FAULT; //快表未命中,查内存页表 不做假设,如果有页表项没有建立,还需要建立页表项,物理页面没有分配就需要分配物理页面 npages = hva_to_pfn_slow(addr, async, write_fault, writable, &pfn); if (npages == 1) return pfn; down_read(¤t->mm->mmap_sem); if (npages == -EHWPOISON || (!async && check_user_page_hwpoison(addr))) { pfn = KVM_PFN_ERR_HWPOISON; goto exit; } vma = find_vma_intersection(current->mm, addr, addr + 1); if (vma == NULL) pfn = KVM_PFN_ERR_FAULT; else if ((vma->vm_flags & VM_PFNMAP)) { pfn = ((addr - vma->vm_start) >> PAGE_SHIFT) + vma->vm_pgoff; BUG_ON(!kvm_is_mmio_pfn(pfn)); } else { if (async && vma_is_valid(vma, write_fault)) *async = true; pfn = KVM_PFN_ERR_FAULT; } exit: up_read(¤t->mm->mmap_sem); return pfn; }
hva_to_pfn_fast函数中直接调用了linux内核函数__get_user_pages_fast
/* * The atomic path to get the writable pfn which will be stored in @pfn, * true indicates success, otherwise false is returned. */ static bool hva_to_pfn_fast(unsigned long addr, bool atomic, bool *async, bool write_fault, bool *writable, pfn_t *pfn) { struct page *page[1]; int npages; if (!(async || atomic)) return false; /* * Fast pin a writable pfn only if it is a write fault request * or the caller allows to map a writable pfn for a read fault * request. */ if (!(write_fault || writable)) return false; npages = kvm___get_user_pages_fast(addr, 1, 1, page);//#define kvm___get_user_pages_fast __get_user_pages_fast if (npages == 1) { *pfn = page_to_pfn(page[0]); if (writable) *writable = true; return true; } return false; }
hva_to_pfn_slow三个分支函数分别调用了linux内核的函数:__get_user_pages和get_user_pages_fast和__get_user_pages_fast
/* * The slow path to get the pfn of the specified host virtual address, * 1 indicates success, -errno is returned if error is detected. */ static int hva_to_pfn_slow(unsigned long addr, bool *async, bool write_fault, bool *writable, pfn_t *pfn) {//快表未命中,查内存页表 不做假设,如果有页表项没有建立,还需要建立页表项,物理页面没有分配就需要分配物理页面 struct page *page[1]; int npages = 0; might_sleep(); if (writable) *writable = write_fault; if (async) { down_read(¤t->mm->mmap_sem); npages = get_user_page_nowait(current, current->mm, addr, write_fault, page);//调用__get_user_pages, get_user_pages的主要实现函数 up_read(¤t->mm->mmap_sem); } else npages = get_user_pages_fast(addr, 1, write_fault, page);//调用了linux内核的get_user_pages函数. //在linux-3.10.1里这里直接就是get_user_pages_fast,在qemu页表中查找, //如果页表项无效还通过get_user_pages调用handle_mm_fault分配页表和页框并建立各级页表联系 if (npages != 1) return npages; /* map read fault as writable if possible */ if (unlikely(!write_fault) && writable) { struct page *wpage[1]; //__get_user_pages_fast 是get_user_pages_fast的前部分,也就是直接在qemu页表中查找,页表项无效不分配 npages = kvm___get_user_pages_fast(addr, 1, 1, wpage); if (npages == 1) { *writable = true; put_page(page[0]); page[0] = wpage[0]; } npages = 1; } *pfn = page_to_pfn(page[0]); return npages; }
get_user_pages_fast是linux内核函数,从qemu进程页表中查找物理页,如果页表项无效还会通过get_user_pages函数调用 handle_mm_fault分配新的页表或页框并建立和上一级页表项关联,总之进入该函数就开始维护qemu进程页表,最后得到物理页框的page结构。
__get_user_pages_fast和get_user_pages_fast函数前部分相同,是直接在qemu进程页表中寻找,页表项不存在不进行分配。
__get_user_pages是get_user_pages的主要实现函数,也就是分配页表页和页框建立页表间联系。所以,以下分析get_user_pages_fast:
/** * get_user_pages_fast() - pin user pages in memory * @start: starting user address * @nr_pages: number of pages from start to pin * @write: whether pages will be written to * @pages: array that receives pointers to the pages pinned. * Should be at least nr_pages long. * * Attempt to pin user pages in memory without taking mm->mmap_sem. * If not successful, it will fall back to taking the lock and * calling get_user_pages(). * * Returns number of pages pinned. This may be fewer than the number * requested. If nr_pages is 0 or negative, returns 0. If no pages * were pinned, returns -errno. */ int get_user_pages_fast(unsigned long start, int nr_pages, int write, struct page **pages) {//hva_to_pfn_slow调用时,nr_pages是 1。 //从此处开始就是通过addr在qemu进程页表中的操作,表项无效get_user_pages就新分配页表页 //并建立和表项联系,即维护好qemu进程页表 struct mm_struct *mm = current->mm; unsigned long addr, len, end; unsigned long next; pgd_t *pgdp; int nr = 0; start &= PAGE_MASK; addr = start; len = (unsigned long) nr_pages << PAGE_SHIFT; end = start + len; if (end < start) goto slow_irqon; #ifdef CONFIG_X86_64 if (end >> __VIRTUAL_MASK_SHIFT) goto slow_irqon; #endif /* * XXX: batch / limit ‘nr‘, to avoid large irq off latency * needs some instrumenting to determine the common sizes used by * important workloads (eg. DB2), and whether limiting the batch size * will decrease performance. * * It seems like we‘re in the clear for the moment. Direct-IO is * the main guy that batches up lots of get_user_pages, and even * they are limited to 64-at-a-time which is not so many. */ /* * This doesn‘t prevent pagetable teardown, but does prevent * the pagetables and pages from being freed on x86. * * So long as we atomically load page table pointers versus teardown * (which we do on x86, with the above PAE exception), we can follow the * address down to the the page and take a ref on it. */ local_irq_disable();//禁止本地中断,开始遍历 当前进程 的页表,就是qemu进程页表 pgdp = pgd_offset(mm, addr); do {//while循环,获取二级表的基址 pgd_t pgd = *pgdp; next = pgd_addr_end(addr, end);//next在这里基本就是end了,因为前面申请的仅仅是一个页面的长度(hva_to_pfn_slow该函数调用时。 if (pgd_none(pgd))//如果表项内容为空,则goto到了slow,即要为其建立表项 goto slow; if (!gup_pud_range(pgd, addr, next, write, pages, &nr)) goto slow; } while (pgdp++, addr = next, addr != end); local_irq_enable(); VM_BUG_ON(nr != (end - start) >> PAGE_SHIFT); return nr; { int ret; slow: local_irq_enable(); slow_irqon: /* Try to get the remaining pages with get_user_pages */ start += nr << PAGE_SHIFT; pages += nr; down_read(&mm->mmap_sem); ret = get_user_pages(current, mm, start, (end - start) >> PAGE_SHIFT, write, 0, pages, NULL);//表项为空 申请页表页 并建立和前一级页目录项关系 会调用handle_mm_fault up_read(&mm->mmap_sem); /* Have to be a bit careful with return values */ if (nr > 0) { if (ret < 0) ret = nr; else ret += nr; } return ret; } }
也是__get_user_pages_fast的类似实现。看出表项为空就走slow,否则就gup_pud_range->gup_pmd_range->gup_pte_range得到pfn的page结构。
Slow的主要函数就是get_user_pages,其主要函数是__get_user_pages,该函数很长,主要看了handle_mm_fault分配页表页和页框并建立联系:
/* * By the time we get here, we already hold the mm semaphore */ int handle_mm_fault(struct mm_struct *mm, struct vm_area_struct *vma, unsigned long address, unsigned int flags)// {/*分配新的页表页和页框 最后调用handle_pte_fault*/ pgd_t *pgd; pud_t *pud; pmd_t *pmd; pte_t *pte; __set_current_state(TASK_RUNNING); count_vm_event(PGFAULT); mem_cgroup_count_vm_event(mm, PGFAULT); /* do counter updates before entering really critical section. */ check_sync_rss_stat(current); if (unlikely(is_vm_hugetlb_page(vma))) return hugetlb_fault(mm, vma, address, flags); retry: pgd = pgd_offset(mm, address); pud = pud_alloc(mm, pgd, address);//pgd项有效则pud_offset获取pud项, //否则分配pud表,并pud_populate建立pgd项和pud表关系 if (!pud) return VM_FAULT_OOM; pmd = pmd_alloc(mm, pud, address);//分配pmd页表页,建立pud项和pmd表关系 if (!pmd) return VM_FAULT_OOM; if (pmd_none(*pmd) && transparent_hugepage_enabled(vma)) { if (!vma->vm_ops) return do_huge_pmd_anonymous_page(mm, vma, address, pmd, flags); } else { pmd_t orig_pmd = *pmd; int ret; barrier(); if (pmd_trans_huge(orig_pmd)) { unsigned int dirty = flags & FAULT_FLAG_WRITE; /* * If the pmd is splitting, return and retry the * the fault. Alternative: wait until the split * is done, and goto retry. */ if (pmd_trans_splitting(orig_pmd)) return 0; if (pmd_numa(orig_pmd)) return do_huge_pmd_numa_page(mm, vma, address, orig_pmd, pmd); if (dirty && !pmd_write(orig_pmd)) { ret = do_huge_pmd_wp_page(mm, vma, address, pmd, orig_pmd); /* * If COW results in an oom, the huge pmd will * have been split, so retry the fault on the * pte for a smaller charge. */ if (unlikely(ret & VM_FAULT_OOM)) goto retry; return ret; } else { huge_pmd_set_accessed(mm, vma, address, pmd, orig_pmd, dirty); } return 0; } } if (pmd_numa(*pmd)) return do_pmd_numa_page(mm, vma, address, pmd); /* * Use __pte_alloc instead of pte_alloc_map, because we can‘t * run pte_offset_map on the pmd, if an huge pmd could * materialize from under us from a different thread. */ if (unlikely(pmd_none(*pmd)) && unlikely(__pte_alloc(mm, vma, pmd, address)))//分配pte页并建立和pmd项关系 return VM_FAULT_OOM; /* if an huge pmd materialized from under us just retry later */ if (unlikely(pmd_trans_huge(*pmd))) return 0; /* * A regular pmd is established and it can‘t morph into a huge pmd * from under us anymore at this point because we hold the mmap_sem * read mode and khugepaged takes it in write mode. So now it‘s * safe to run pte_offset_map(). */ pte = pte_offset_map(pmd, address);//pte项 /*handle_pte_fault()的任务就是为pte绑定新的页框,它会根据pte页表项的情况来做不同的处理*/ return handle_pte_fault(mm, vma, address, pte, pmd, flags); }
主要函数就是pud_alloc、pmd_alloc、__pte_alloc和handle_pte_fault。
static inline pud_t *pud_alloc(struct mm_struct *mm, pgd_t *pgd, unsigned long address)// {//判断pgd是否为invalide,是则调用__pud_alloc;不是则获取地址继续查 return (unlikely(pgd_none(*pgd)) && __pud_alloc(mm, pgd, address))? NULL: pud_offset(pgd, address);// } static inline pmd_t *pmd_alloc(struct mm_struct *mm, pud_t *pud, unsigned long address) {//判断pud是否为invalide,是则调用__pmd_alloc;不是则获取地址继续查 return (unlikely(pud_none(*pud)) && __pmd_alloc(mm, pud, address))? NULL: pmd_offset(pud, address);// } /* * Allocate page upper directory. * We‘ve already handled the fast-path in-line. */ int __pud_alloc(struct mm_struct *mm, pgd_t *pgd, unsigned long address)// {//pgd页表项为invalide,分配新的pud页表页 并建立pgd表项和新pud页表页关系 pud_t *new = pud_alloc_one(mm, address);//分配一个pud页表页 if (!new) return -ENOMEM; smp_wmb(); /* See comment in __pte_alloc */ spin_lock(&mm->page_table_lock); if (pgd_present(*pgd)) /* Another has populated it */ pud_free(mm, new); else pgd_populate(mm, pgd, new);//pgd_populate用来建立pgd entry和PUD页表页的关系 spin_unlock(&mm->page_table_lock); return 0; } #endif /* __PAGETABLE_PUD_FOLDED */ #ifndef __PAGETABLE_PMD_FOLDED /* * Allocate page middle directory. * We‘ve already handled the fast-path in-line. */ int __pmd_alloc(struct mm_struct *mm, pud_t *pud, unsigned long address) {//pud页表项为invalide,分配新的pmd页表页 并建立pud项和pmd表关系 pmd_t *new = pmd_alloc_one(mm, address);//分配pmd页表页 if (!new) return -ENOMEM; smp_wmb(); /* See comment in __pte_alloc */ spin_lock(&mm->page_table_lock); #ifndef __ARCH_HAS_4LEVEL_HACK if (pud_present(*pud)) /* Another has populated it */ pmd_free(mm, new); else pud_populate(mm, pud, new);//建立pud项和pmd表关系 #else if (pgd_present(*pud)) /* Another has populated it */ pmd_free(mm, new); else pgd_populate(mm, pud, new);//如果不是四级页表 free刚才的pmd 建立pgd项和pud表关系 //(可是三级页表不是没有pud表?这里是把pud当pmd了 因为pud刚才建好了? #endif /* __ARCH_HAS_4LEVEL_HACK */ spin_unlock(&mm->page_table_lock); return 0; }
pud_alloc、pmd_alloc和__pte_alloc作用类似,都是分配页表页(pud_alloc_one、pmd_alloc_one、pte_alloc_one)并建立上级页目录项和页表页联系(pgd_populate、pud_populate、pmd_populate)。
handle_pte_fault是为pte绑定新的页框,它会根据pte页表项的情况来做不同的处理。这个处理里涉及到很多类型,比如映射页和匿名页的区别处理,由写一个只读页触发的需要写时复制,这里也是do_fork子进程复制父进程页表后,进行写时复制和父进程区分。这里就不写了了,之后想看了文件系统,对这里有一定认识后再分析。
5.2 __direct_map
该函数完成EPT页表的构造,找到最终level的相应ept表项,设置物理地址,否则相应level页表页不存在,则分配ept页表页
/* * 建立EPT页表结构,负责将GPA逐层添加到EPT页表中 * @vcpu: 发生EPT VIOLATION的VCPU * @gfn: 缺页GUEST物理地址的GFN * @level: 叶子页表所在的level * @pfn: gfn对应的HOST物理页的页框号 */ static int __direct_map(struct kvm_vcpu *vcpu, gpa_t v, int write, int map_writable, int level, gfn_t gfn, pfn_t pfn, bool prefault) { struct kvm_shadow_walk_iterator iterator; struct kvm_mmu_page *sp;//KVM用结构体kvm_mmu_page表示一个EPT页表页结构 int emulate = 0; gfn_t pseudo_gfn; /* * 遍历所有页表中addr对应的页表项spte */ for_each_shadow_entry(vcpu, (u64)gfn << PAGE_SHIFT, iterator) { /* * 叶子节点,直接映射真正的物理页面pfn。说明Violation是因为虚拟机寻址的物理页面不在内存中, * 所以需要try**后续的一些调用host函数得到的pfn */ if (iterator.level == level) { /* * 若找到最终level的EPT页表项,调用mmu_set_spte将GPA添加进去, * 若为各级中间level的页表项,调用__set_spte将下一级物理地址添加进去 【感觉这句没用到? */ mmu_set_spte(vcpu, iterator.sptep, ACC_ALL, write, &emulate, level, gfn, pfn, prefault, map_writable);// direct_pte_prefetch(vcpu, iterator.sptep); ++vcpu->stat.pf_fixed; break; } /* * 非叶子页表页表项,表项不存在导致的EPT Violation,分配下一级页表,并链接到当前的spte中 */ if (!is_shadow_present_pte(*iterator.sptep)) {//该页表项之前并没有初始化 u64 base_addr = iterator.addr; base_addr &= PT64_LVL_ADDR_MASK(iterator.level);/*将GPA对齐到level级页表页表项所管理的地址空间的起始地址上*/ pseudo_gfn = base_addr >> PAGE_SHIFT;/*将对齐后的GPA转换为页帧号*/ sp = kvm_mmu_get_page(vcpu, pseudo_gfn, iterator.addr, iterator.level - 1, 1, ACC_ALL, iterator.sptep);/*分配一个EPT页表页,即kvm_mmu_page结构*/ link_shadow_page(iterator.sptep, sp);/*将新分配到的下一级页表页的基地址填充到当前页表项SPTE中*/ } } return emulate; }
for_each_shadow_entry函数利用kvm_shadow_walk_iterator结构遍历EPT页表,逐级查找GPA所对应的页表项
#define for_each_shadow_entry(_vcpu, _addr, _walker) for (shadow_walk_init(&(_walker), _vcpu, _addr); shadow_walk_okay(&(_walker)); shadow_walk_next(&(_walker)))
kvm_shadow_walk_iterator数据结构含义:
/* * 遍历影子页表时所用的迭代器 */ struct kvm_shadow_walk_iterator {//shadow_walk_init初始化该结构 u64 addr;//GPA,寻找的GuestOS的物理页帧,即(u64)gfn << PAGE_SHIFT hpa_t shadow_addr;//指向当前level级页表的基地址 u64 *sptep;//当前正在遍历的页表中的页表项指针 /** * sptep不是下一级页表的基地址,而是当前页表中药使用的表项,而该表项中含有下一级表项的基地址, * 更新的时候,需要向sptep中填入下一级表项物理地址或HPA物理地址 */ int level;//当前所处的页表级别 unsigned index;// gaddr在当前level页表中的索引 };
shadow_walk_init函数
/* * 负责初始化struct kvm_shadow_walk_iterator结构,准备遍历EPT页表 * @addr 是发生 ept violation的guest物理地址(调用者已经进行了页面对齐,因为EPT映射都是整页面进行的) * @vcpu 发生EPT violation的VCPU * @iterator 迭代器 */ static void shadow_walk_init(struct kvm_shadow_walk_iterator *iterator, struct kvm_vcpu *vcpu, u64 addr) { iterator->addr = addr;//把要索引的地址赋给addr iterator->shadow_addr = vcpu->arch.mmu.root_hpa;//初始化时,要查找的页表基址就是 当前VCPU的根页表目录的物理地址 EPT Pointer的基地址 /* * 初始化 指向根页表(level = 4级) * 注意这里iterator->level是mmu.shadow_root_level 而不是role.level */ iterator->level = vcpu->arch.mmu.shadow_root_level; /* * 如果HOST上EPT是4级,但是guest页表小于4级,说明GUEST可能是32bit paging,或其他的映射方式 * 这种是非直接映射 * 从下一级 level = 3 开始 */ if (iterator->level == PT64_ROOT_LEVEL && vcpu->arch.mmu.root_level < PT64_ROOT_LEVEL && !vcpu->arch.mmu.direct_map) --iterator->level; /*PAE的情况,PDPT中只有4个PDPTP*/ if (iterator->level == PT32E_ROOT_LEVEL) { iterator->shadow_addr = vcpu->arch.mmu.pae_root[(addr >> 30) & 3]; iterator->shadow_addr &= PT64_BASE_ADDR_MASK; --iterator->level; if (!iterator->shadow_addr) iterator->level = 0; } }
shadow_walk_okay函数
/* * 检查是否还需要遍历当前页表,当level < 1的时候,已经遍历完最后一个级别就不需要遍历了 */ static bool shadow_walk_okay(struct kvm_shadow_walk_iterator *iterator) { if (iterator->level < PT_PAGE_TABLE_LEVEL)//若页表级数小于1,已经遍历完最后一个级别就不需要遍历了 直接退出 return false; iterator->index = SHADOW_PT_INDEX(iterator->addr, iterator->level);//获得要寻找的addr在当前level级页表中对应的页表项索引值 /* * shadow_addr 指向当前level级页表的基地址,通过偏移index距离得到对应的页表项,记录spte的地址到sptep中 * sptep不是下一级页表的基地址,而是当前页表中要使用的表项,而该表项中含有下一级表项的基地址, 更新的时候,需要向sptep中填入下一级表项物理地址或HPA物理地址 */ iterator->sptep = ((u64 *)__va(iterator->shadow_addr)) + iterator->index; return true; }
shadow_walk_next函数
/* * 处理完了当前级别页表,取得下一级页表。 * 函数进入的时候, spte的值是 当前级别页表 中使用的页表项的值 */ static void __shadow_walk_next(struct kvm_shadow_walk_iterator *iterator, u64 spte) { /* * 如果当前页表项已经是叶子页表页表项,直接赋值level = 0,以便在shadow_walk_okay中退出 */ if (is_last_spte(spte, iterator->level)) { iterator->level = 0; return; } /* * 不是最后一级页表的页表项的话 * 从SPTE中提取出下一级影子页表的基地址,记录到shadow_addr,相当于 i-- * 因为到了下一级页表,页表级别也就减少1。 */ iterator->shadow_addr = spte & PT64_BASE_ADDR_MASK; --iterator->level; } static void shadow_walk_next(struct kvm_shadow_walk_iterator *iterator) {//索引下一级EPT页表 return __shadow_walk_next(iterator, *iterator->sptep); }
mmu_set_spte用来设置影子页表项,这样就可以将PFN或者下一级页表的基地址填到SPTE中,其中包括刷新TLB、将spte加入gfn对应的rmap中。但感觉在此处的利用是在一级页表中entry指向的物理页被换出磁盘,所以只是设置EPT的叶子页表项,将最终的pfn添加到对应spte中。
该函数中关于反向映射的添加:rmap_add(添加gfn反向映射spte)
static int rmap_add(struct kvm_vcpu *vcpu, u64 *spte, gfn_t gfn) {//添加gfn反向映射spte 添加的内容是struct pte_list_desc struct kvm_mmu_page *sp; unsigned long *rmapp; sp = page_header(__pa(spte));//通过影子页表项找到该页kvm_mmu_page,一个该结构描述一个层级的页表,地址保存在page结构的private字段 kvm_mmu_page_set_gfn(sp, spte - sp->spt, gfn); rmapp = gfn_to_rmap(vcpu->kvm, gfn, sp->role.level);//获取gfn(客户机物理页框)反向映射的指针 得到这个gfn对应的memory slot return pte_list_add(vcpu, spte, rmapp);//每个rmapp指向一个pte_list }
gfn_to_rmap调用gfn_to_memslot(得到这个gfn对应的memory slot),__gfn_to_rmap通过gfn_to_index(gfn在slot中的index)利用index从slot->arch.rmap数组中取出相应的rmap。有了gfn对应的rmap之后,再调用pte_list_add将这次映射得到的spte加到这个rmap中,pte_list_add函数如下:
/* * Pte mapping structures: * * If pte_list bit zero is zero, then pte_list point to the spte. * * If pte_list bit zero is one, (then pte_list & ~1) points to a struct * pte_list_desc containing more mappings. * * Returns the number of pte entries before the spte was added or zero if * the spte was not added. * */ static int pte_list_add(struct kvm_vcpu *vcpu, u64 *spte, unsigned long *pte_list) { struct pte_list_desc *desc; int i, count = 0; if (!*pte_list) { /*如果*pte_list为空,表示这个rmap之前没有创建过,那么将其赋值 直接设置逆向映射即可 */ rmap_printk("pte_list_add: %p %llx 0->1\n", spte, *spte); *pte_list = (unsigned long)spte; } else if (!(*pte_list & 1)) { /*这个pte_list不为空,但是其第一位是0 表示这个rmap之前已经被设置了一个值, 那么需要将这个pte_list的值改为某个struct pte_list_desc的地址, 然后将第一位设成1,来表示该地址并不是单纯的一个spte的地址,而是指向某个struct pte_list_desc*/ rmap_printk("pte_list_add: %p %llx 1->many\n", spte, *spte); desc = mmu_alloc_pte_list_desc(vcpu); desc->sptes[0] = (u64 *)*pte_list; desc->sptes[1] = spte; *pte_list = (unsigned long)desc | 1; ++count; } else { /*这个pte_list不为空,而且其第一位是1,那么通过访问由这个地址得到的struct pte_list_desc,得到更多的sptes*/ rmap_printk("pte_list_add: %p %llx many->many\n", spte, *spte); desc = (struct pte_list_desc *)(*pte_list & ~1ul); while (desc->sptes[PTE_LIST_EXT-1] && desc->more) { desc = desc->more; count += PTE_LIST_EXT; } if (desc->sptes[PTE_LIST_EXT-1]) { /*如果已经满了,就再次扩展more*/ desc->more = mmu_alloc_pte_list_desc(vcpu); desc = desc->more; } for (i = 0; desc->sptes[i]; ++i)/*找到首个为空的项,进行填充*/ ++count; desc->sptes[i] = spte; } return count; }
kvm_mmu_get_page当创建新页表页后,用到了上述kvm_arch结构的成员mmu_page_hash链表
/* gfn:gaddr通过某些计算得到的gfn,计算的公式是(gaddr >> 12) & ~((1 << (level * 9)) - 1); gaddr:产生该ept violation的gpa; level:该页表页对应的level,可能取值为3,2,1; direct:在EPT机制下,该值始终为1,如果是shadow paging机制,该值为0; access:该页表页的访问权限; parent_pte:上一级页表页中指向该级页表页的页表项的地址。 */ static struct kvm_mmu_page *kvm_mmu_get_page(struct kvm_vcpu *vcpu, gfn_t gfn, gva_t gaddr, unsigned level, int direct, unsigned access, u64 *parent_pte) {//分配一个EPT页表页,即kvm_mmu_page结构 union kvm_mmu_page_role role; unsigned quadrant; struct kvm_mmu_page *sp; bool need_sync = false; role = vcpu->arch.mmu.base_role; role.level = level;//代表本页表页在ept中的级别 role.direct = direct; if (role.direct) role.cr4_pae = 0; role.access = access; if (!vcpu->arch.mmu.direct_map && vcpu->arch.mmu.root_level <= PT32_ROOT_LEVEL) { quadrant = gaddr >> (PAGE_SHIFT + (PT64_PT_BITS * level)); quadrant &= (1 << ((PT32_PT_BITS - PT64_PT_BITS) * level)) - 1; role.quadrant = quadrant; } //通过role和gfn在反向映射表中查找kvm mmu page,如果存在之前创建过的page,则返回该page //查找之前已经使用过的kvm_mmu_page,该宏根据gfn的值在kvm_mmu_page结构中的hash_link进行 for_each_gfn_sp(vcpu->kvm, sp, gfn) {//查找页表页已被上一级spte分配,找到了 if (is_obsolete_sp(vcpu->kvm, sp)) continue; if (!need_sync && sp->unsync) need_sync = true; if (sp->role.word != role.word) continue; if (sp->unsync && kvm_sync_page_transient(vcpu, sp)) break; mmu_page_add_parent_pte(vcpu, sp, parent_pte); /*设置parent_pte对应的reverse map,将本次的parent_spte加入到反向链表中 设置sp->parent_pte=parent_pte*/ if (sp->unsync_children) { kvm_make_request(KVM_REQ_MMU_SYNC, vcpu); kvm_mmu_mark_parents_unsync(sp); } else if (sp->unsync) kvm_mmu_mark_parents_unsync(sp); __clear_sp_write_flooding_count(sp); trace_kvm_mmu_get_page(sp, false); return sp; } /*该gfn对应的页表页不存在,则分配出来页表页及其管理结构*/ ++vcpu->kvm->stat.mmu_cache_miss; sp = kvm_mmu_alloc_page(vcpu, parent_pte, direct);//创建新的struct kvm_mmu_page if (!sp) return sp; sp->gfn = gfn;//设置所管理GUEST物理地址空间的起始gfn和level角色 sp->role = role; /*当分配完一个kvm_mmu_page结构之后, 会用其管理GUEST物理地址空间的起始GFN为key计算一个hash值, 并上到哈希表arch.mmu_page_hash[]上, 以便可以快速的根据gfn找到管理该物理地址空间的页表页*/ hlist_add_head(&sp->hash_link, &vcpu->kvm->arch.mmu_page_hash[kvm_page_table_hashfn(gfn)]); if (!direct) { if (rmap_write_protect(vcpu->kvm, gfn)) kvm_flush_remote_tlbs(vcpu->kvm); if (level > PT_PAGE_TABLE_LEVEL && need_sync) kvm_sync_pages(vcpu, gfn); account_shadowed(vcpu->kvm, gfn); } sp->mmu_valid_gen = vcpu->kvm->arch.mmu_valid_gen; init_shadow_page_table(sp);//初始化清空页表页中所有的SPTE为0 trace_kvm_mmu_get_page(sp, true); return sp; }
for_each_gfn_sp用到kvm_arch结构的成员mmu_page_hash表快速查找
/* * NOTE: we should pay more attention on the zapped-obsolete page * (is_obsolete_sp(sp) && sp->role.invalid) when you do hash list walk * since it has been deleted from active_mmu_pages but still can be found * at hast list. * * for_each_gfn_indirect_valid_sp has skipped that kind of page and * kvm_mmu_get_page(), the only user of for_each_gfn_sp(), has skipped * all the obsolete pages. */ /*利用起始gfn在哈希表arch.mmu_page_hash[]上,快速的查找管理该物理地址空间的页表页是否已经被分配了 已经被上级spte分配,则找到了 */ #define for_each_gfn_sp(_kvm, _sp, _gfn) \ hlist_for_each_entry(_sp, &(_kvm)->arch.mmu_page_hash[kvm_page_table_hashfn(_gfn)], hash_link) if ((_sp)->gfn != (_gfn)) {} else
kvm_mmu_alloc_page用到了上述kvm_vcpu_arch结构的成员mmu_page_cache(spt页结构)、mmu_page_header_cache(kvm_mmu_page结构)这两个都是kvm定义的cache结构,用于进一步优化MMU的分配效率,kvm_arch结构的成员active_mmu_pages(激活的页表页)
static struct kvm_mmu_page *kvm_mmu_alloc_page(struct kvm_vcpu *vcpu, u64 *parent_pte, int direct) { struct kvm_mmu_page *sp; //mmu_memory_cache_alloc从之前分配好的mmu page的memory cache中得到一个kvm_mmu_page结构体实例 sp = mmu_memory_cache_alloc(&vcpu->arch.mmu_page_header_cache);//分配管理页表页的 kvm_mmu_page结构 sp->spt = mmu_memory_cache_alloc(&vcpu->arch.mmu_page_cache);//分配具体EPT页表页 if (!direct) sp->gfns = mmu_memory_cache_alloc(&vcpu->arch.mmu_page_cache); set_page_private(virt_to_page(sp->spt), (unsigned long)sp); /* * The active_mmu_pages list is the FIFO list, do not move the * page until it is zapped. kvm_zap_obsolete_pages depends on * this feature. See the comments in kvm_zap_obsolete_pages(). */ list_add(&sp->link, &vcpu->kvm->arch.active_mmu_pages);//加到活动链表 sp->parent_ptes = 0; mmu_page_add_parent_pte(vcpu, sp, parent_pte);//设置其parent_pte的reverse map.所有引用该页表页的上级页表项称为parent_spte,存放在kvm_mmu_page的parent_ptes链表中 kvm_mod_used_mmu_pages(vcpu->kvm, +1); return sp; }
源码:kvm-3.10.1。图上有来源水印。研一时候分析写的的,现在很多忘记了-_-以后的东西要抽空搬上来,好好经营博客
原文:https://www.cnblogs.com/beixiaobei/p/10507517.html