1.字符串操作:
解析身份证信息:
ID=input("输入你的身份证号:")
shengfen = ID[0:2]
year = ID[6:10]
month = ID[10:12]
day = ID[12:14]
sex=ID[-2]
print(‘你的省份信息为:‘+shengfen)
print(‘出生日期为:‘+year+‘年‘+day+‘月‘+day+‘日‘)
if (int(sex) % 2) == 0:
print(‘性别为:女性‘)
else:
print(‘性别为:男性‘)

凯撒密码:
from idna import unichr
a=‘‘
s=input(‘输入要加密的信息:‘)
num=input(‘输入加密数字:‘)
print(‘密文为:‘)
for i in s:
a+=unichr(ord(i)+int(num));
print(a)
print(‘还原信息:‘)
for i in a:
print(unichr(ord(i)-int(num)),end=‘‘);

2.英文词频统计预处理
import operator
text=‘‘‘It was a cold winter day in 1919. A small boy was walking along the street in London.
His name was Tom. He was very hungry.
He wanted to buy some bread, but he had no money.
What could he do? When he was very young, he wanted to be a great man in the world of films.
So he worked to sing and dance well.
Thirty years later, the boy became one of the famous people in the world.‘‘‘
text1=text.replace(‘.‘,‘ ‘).replace(‘?‘,‘ ‘).replace(‘,‘,‘ ‘).lower().split();
dic = {}
for word in text1:
if word not in dic:
dic[word] = 1;
else:
dic[word] = dic[word] + 1;
swd = sorted(dic.items(), key=operator.itemgetter(1), reverse=True)
print(swd)

3.文件操作
凯撒密码:从文件读入密函,进行加密或解密,保存到文件。
from idna import unichr
def openFile(i):
if i ==1:
return open(r‘C:\Users\Shinelon\Desktop\123.txt‘, ‘r‘, encoding=‘gb2312‘);
else:
return open(r‘C:\Users\Shinelon\Desktop\234.txt‘, ‘a‘, encoding=‘utf8‘);
a=‘‘
f=openFile(1)
text=f.read();
f.close();
num=3
print(‘密文为:‘)
for i in text:
a+=unichr(ord(i)+int(num));
print(a)
j=openFile(2)
j.seek(0)
j.truncate()
j.write(a)
j.close()
print(‘还原信息:‘)
for i in a:
print(unichr(ord(i)-int(num)),end=‘‘);
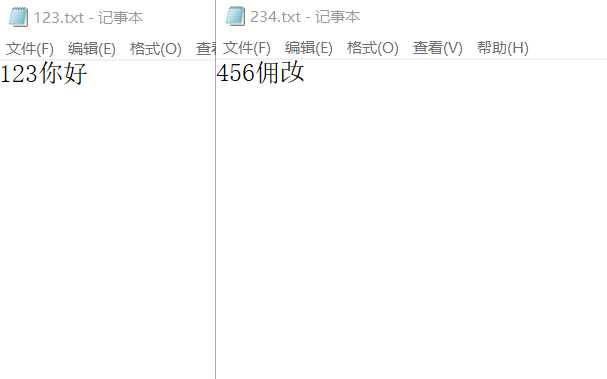
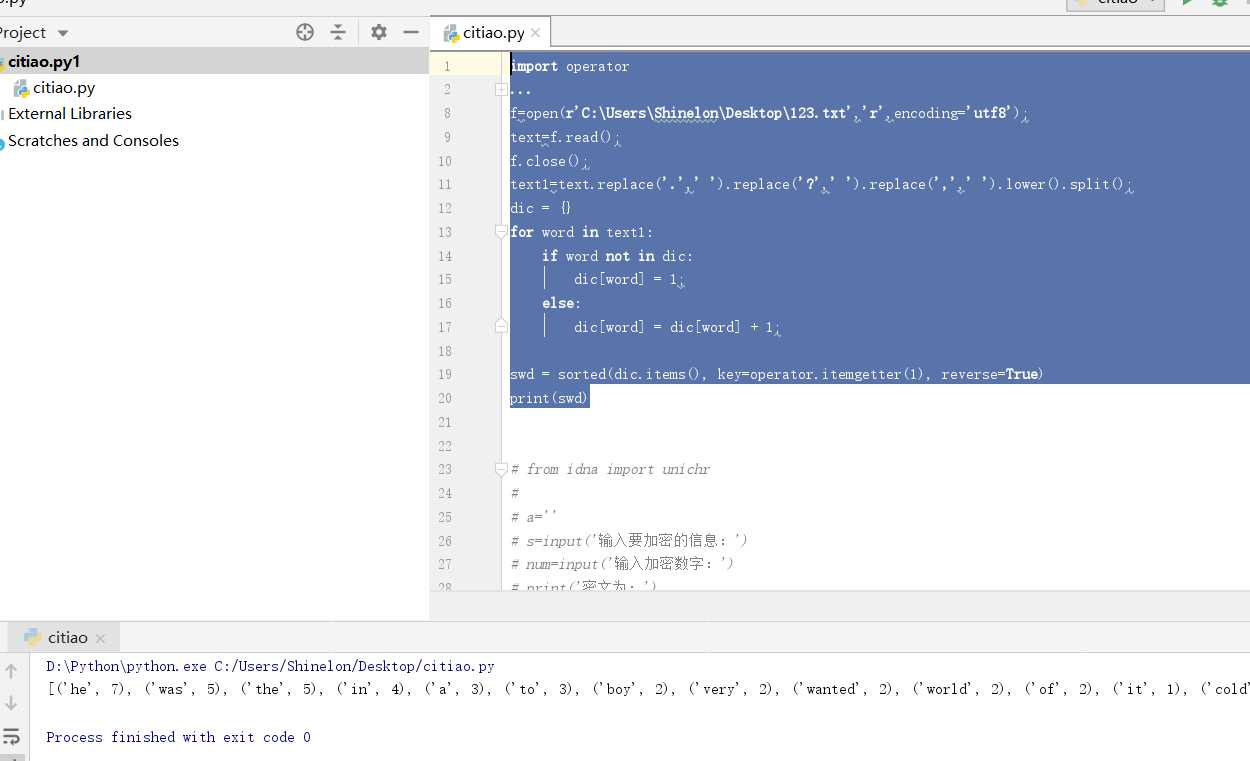
词频统计:下载一首英文的歌词或文章或小说,保存为utf8文件。从文件读入文本进行处理。
import operator
f=open(r‘C:\Users\Shinelon\Desktop\123.txt‘,‘r‘,encoding=‘utf8‘);
text=f.read();
f.close();
text1=text.replace(‘.‘,‘ ‘).replace(‘?‘,‘ ‘).replace(‘,‘,‘ ‘).lower().split();
dic = {}
for word in text1:
if word not in dic:
dic[word] = 1;
else:
dic[word] = dic[word] + 1;
swd = sorted(dic.items(), key=operator.itemgetter(1), reverse=True)
print(swd)
4.函数定义
加密函数
def jiami(xinxi,num):
temp=‘‘
for i in xinxi:
temp+=unichr(ord(i)+int(num));
return temp;
解密函数
def jiemi(xinxi,num):
temp=‘‘
for i in xinxi:
temp+=unichr(ord(i)-int(num));
return temp;
读文本函数
def openFile():
return open(r‘C:\Users\Shinelon\Desktop\123.txt‘, ‘r‘, encoding=‘utf8‘);
原文:https://www.cnblogs.com/chenshijiong/p/10508205.html