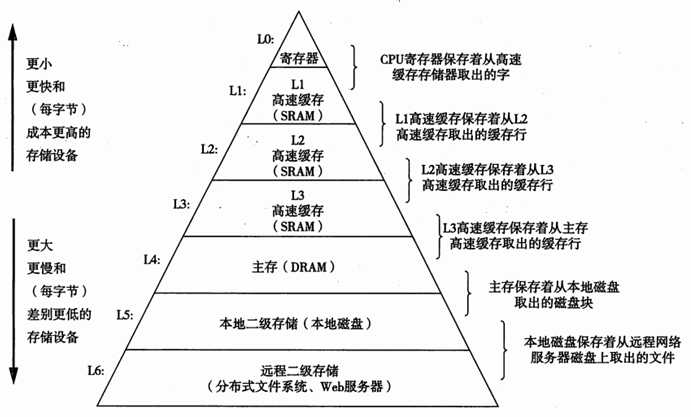
基于缓存的存储器层次结构行之有效,是因为较慢的存储设备比较快的存储设备更便宜,还因为程序往往展示局部性:
时间局部性:被引用过一次的存储器的位置很可能在不远的将来被再次引用。
空间局部性:如果一个存储器位置被引用了一次,那么程序很可能在不远的将来引用附近的一个存储器位置。
一个通用的高速缓存存储器会有S = 2 ^ s个set(组)
每个set含有E个line(既通常所说的cache line)
每个line又包含1位vaild bit、 t位tag、B = 2 ^ b bytes cache block(真正存储数据的地方)。
通常我们说的cache line 64位 32位,实际上是说的cache line中cache block是64位32位。
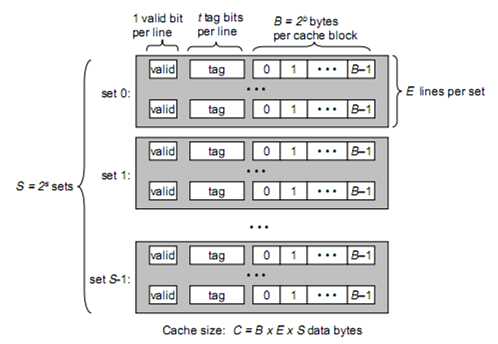
假设我们的存储器地址有m位,共M = 2^m个不同的地址。我们看一下各个变量之间的关系。
cache缓存数据的大小C = (sizeof set * number of set) = (size of block * lines a set) * number of set = B * E * S
内存大小2^m Cache line大小2^b 内存的cache line个数2^(m-b)
2^(m-b)个cache line分到2^s个set里, 每个set会有2^(m - b –s)个cache line,这个数字不是E,是指会有2^(m – b –s)个cache line落到这个set 里面,那么就需要有m-b-s位tag,标记出当前是哪个cache line落到这个set里面了。也就是说t = m - b –s。
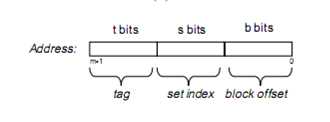
如上图所示,m位地址的内存,需要s位做索引,选set,t位做tag,选cache line,然后b 位做偏移取具体地址的内存。
高速缓存确定一个请求是否命中,然后抽取出被请求的字的过程,分为三步1)组选择2)行匹配3)字抽取。
直接映射每个组只有一行E=1
选组
地址中取s bits选组
选行
地址中取t bits与cache line中t bits tag匹配,匹配则命中,不匹配则cache miss
字抽取
地址中的b bits就是cache line中偏移,在命中的cache line中的取字。
直接映射不命中时,不需要什么策略,直接把索引的组中的cache line替换掉即可。
组相连映射中,一个组包括多个cache line,目前常见的有四路组相连映射,16路组相连映射,即一个set中有4个或16个cache line。对比直接映射,set 个数要比直接映射的少。因此s会小,相应的落到每个set中的cache line会多,因此t会大。
选组
组相连映射的组选择与直接映射一致。
选行
cache line的选择时,因为一个set中有多个cache line,因此需要搜索set中的每个cache line的tag,对比检查是否命中。
字抽取
与直接映射一致
组相连映射对于一个index就会有多个行与之相对应,比较每行的tag是否与想要的地址相符合,这样就会大大增加命中的几率,避免了一小段程序中频繁cache失效的问题。
组相连映射不命中时,由于索引到的组中会有多个cache line,因此会有多种算法选择到底替换哪个cache line。
全相连映射就是组相连映射只有一个组的情况。
选组
全相连映射组选择很简单,只有一个组,不需要组索引,s = 0,地址只被划分为一个标记tag,和一个偏移。
选行
全相连映射cache line选择时,需要多缓存中的所有cache line进行搜索对比。
字抽取
与之前一致
全相连映射需要大量的搜索cache line进行对比,导致构造一个又大又快的全相连高速缓存很困难,而且很昂贵。因此全相连缓存只适合做小的高速缓存,比如TLB。
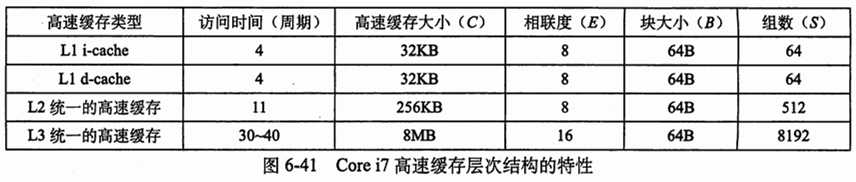
以上内容来自《深入理解计算机系统》6.4 以下内容来自互联网
逻辑cache,Virtual index virtual tagged是纯粹用虚拟地址来寻址,逻辑地址索引逻辑地址tag,这种方式带来了很多的问题,每一行数据在原有tag的基础上都要将进程标识加上以区分多个进程之间的相同地址,而在 处理共享内存时也比较麻烦,共享内存在不同的进程中的虚拟地址不相同,如何同步是个问题。
物理cache,Physical index physical tagged,物理地址索引和物理地址tag,是一种最容易理解的操作方式,cache针对物理地址进行操作,简单粗暴,而且不会有歧义。但是这种方式的缺陷也很明显,在多进程操作系统 中,每个进程拥有自己独立的地址空间,指令和代码都是以虚拟地址的方式存在,cpu发出的memory access的指令都是以虚拟地址的方式发出,这样的话,对于每一个memory access的操作,都要先等待MMU将虚拟地址翻译为物理地址,这是一种串行的方式,效率较低。
现在比较多的是采用virtual index physical tagged的方式,virtual index的含义是当cpu发出一个地址请求之后,低位地址去和cache中的index匹配, physical tagged是指虚拟地址的高位地址去和mmu中的页表匹配以拿到物理地址(index和取物理地址这两个过程是并行的),然后用从mmu中取到的物理地 址作为tag(或者tag的一部分)去和cache line的tag位匹配,这样既保证了同一地址在cache中的唯一性(有个例外,cache alias)又能将mmu和cache并行工作,提高了效率。
这种方式带来的唯一问题就是cache alias,一个物理地址缓存到两个cache line中。
cache alias主要发生在cache大小同内存页框大小不一致时,比如说每路cache的大小是8k,而现在较为常用的页框大小是4k,这两个数字说明的问题 分别是这样的:页框大小为4k意味着mmu在划分虚拟空间时是以4k为粒度,每一个4k对齐的内存区域作为内存分配的最小单位,于是就有了这样的结果,虚拟地址和物理地 址的低12位是相同的,因为低12位地址是作为其在4k页框内的偏移,不管它的虚拟地址是什么,它在4k页面内的偏移是一定的。Cache大小为8k,意味着cache index是用依据13位地址来运算的,而如果以虚拟地址来寻址cache,低13位中就包含了一位虚拟地址,所以这种方式称为virtual index。问题出现了,一个物理地址当它被不同进程使用时,由于mmu分页机制仅能保证其低12位相同,那么第13位很有可能是不同的,这样就造成了一 个物理地址在cache中有两个副本,可能会造成同步问题。针对于cache alias问题,目前的方案是由操作系统来保证,对于同一物理地址在不同进程空间的虚拟地址,他们的虚拟地址的差一定是cache大小的整数倍,也就是说 他们的第13位一定是相同的。同时已经有些cpu厂商在开发监视模块,试图在硬件层面解决类似的同步问题。
CPU的高速缓存存储器知识整理,布布扣,bubuko.com
原文:http://www.cnblogs.com/jintianfree/p/3896012.html